
Why data reliability is important
Imagine a major marketing campaign built on faulty customer data. Your targeted ads miss the mark, resources are wasted, and sales fall flat. This is a stark example of what happens when the data driving your decisions is unreliable.
Data reliability is the foundation of accurate and consistent data over time. It means you can trust the information you’re using is complete, accurate, and up-to-date across all your systems. In our increasingly data-driven world, data reliability is no longer optional – it’s essential.
You can monitor data reliability for free
Before you keep reading, DQOps Data Quality Operations Center is a data observability platform that measures and improves data reliability. Please refer to the DQOps documentation to learn how to get started.
What is data reliability
Data reliability refers to the overall trustworthiness of data over time. It means the information you collect and use is accurate, complete, consistent across different sources, timely, and aligns with your business rules and expectations. Think of it as the degree to which you can confidently rely on your data to be a true representation of reality.
Reliable data is the cornerstone of effective decision-making. When your data is accurate and up-to-date, you can make informed choices about everything from product development to marketing campaigns to resource allocation. Reliable data also promotes operational efficiency, minimizing errors and helping you streamline processes throughout your organization.
Why data can be unreliable
Even with the best intentions, many factors can undermine the reliability of your data. Here are some of the most common culprits:
- Human Error: We all make mistakes, and when it comes to data, simple typos, misinterpretations, or inconsistent data entry practices can quickly compromise reliability.
- System Failures: Software glitches, outdated technology, and unexpected malfunctions can corrupt data or introduce inaccuracies.
- Poor Data Governance: Without clear standards, policies, and ownership of data quality, inconsistencies and errors become increasingly likely.
- Multiple, Disparate Data Sources: When merging data from different systems, incompatible formats, inconsistent definitions, and data duplication can significantly impact reliability.
- Changes over Time: What’s being measured, how it’s measured, or the systems involved can all shift over time. If not carefully managed, these changes can create reliability issues.
Identifying the root causes of unreliability in your organization is the first step to improvement. By addressing these issues, you can take major strides in ensuring the data you rely on remains clean, accurate, and a true asset. Read more about the root cause analysis in our blog.
Why data reliability matters
Data reliability is essential because it empowers you to make informed decisions that drive business success. Without trustworthy data, you risk basing your strategies on faulty assumptions, which can lead to misguided actions.
Reliable data also streamlines operations by minimizing errors, redundancies, and the wasted time and money that inevitably follow. In an environment where trust is precious, data reliability fosters strong relationships with customers, partners, and your own teams. They know they can count on the information you provide. Lastly, data reliability gives you a competitive advantage. Organizations that can quickly and confidently analyze data will spot trends, pinpoint opportunities, and outpace those slowed down by unreliable information.
Ensuring data reliability is a continuous process. It requires careful planning, ongoing monitoring, and a commitment to data quality across the entire organization. The reward, however, is immense: a bedrock of accurate information upon which you can make intelligent decisions that drive progress.
How to ensure data reliability
Ensuring data reliability is an ongoing process, not a one-time fix. To maintain a trustworthy stream of information, we need to continuously monitor our data for common quality issues. Data observability platforms are powerful tools for this task. They provide real-time insights into the health of our data pipelines, allowing us to identify anomalies, inconsistencies, and potential errors before they impact decision-making.
Data reliability doesn’t happen in a silo. Assigning clear roles and responsibilities is crucial. This involves establishing a team or individuals tasked with monitoring data quality metrics, reacting to issues when they arise, and implementing solutions. When discrepancies are identified, the source of the problem becomes vital. Issues stemming from our data transformation pipelines fall within the purview of our data engineering team. They can leverage their expertise to refine the transformations, ensuring the data is cleaned and formatted correctly before populating target systems.
However, data quality issues can also originate from the source systems themselves. In such cases, collaboration with data platform owners becomes essential. Working together, we may need to address flaws in the data capture process or even modify existing business processes to prevent the generation of incorrect data at the source. By working across teams and addressing issues at their root cause, we can create a robust system that delivers consistently reliable data. If you engage all data stakeholders, you can build a strong use case for implementing data quality.
Data quality dimensions
The best way to measure data quality is by breaking down potential reliability issues into categories focused on specific aspects of data health. These categories are called data quality dimensions. By monitoring and measuring these dimensions, you gain a comprehensive view of your data’s reliability.
Below is a list of the most common data quality dimensions that are key to maintaining trustworthy data:
- Accuracy: The data correctly reflects the real-world value it represents. This means ensuring it’s free from errors and aligns with the information it’s intended to measure. For instance, a customer’s address in your CRM system should exactly match their address on file. Additionally, when comparing data between systems, such as the aggregated measures in your fact table to the sum of daily transactions in your ERP system, the numbers should match.
- Completeness: All the necessary data fields or elements are present. A complete customer record includes their name, address, email, and phone number, while a survey response has no questions left unanswered.
- Consistency: Data adheres to the same format, structure, and representation across different systems or datasets – and over time. Consistency ensures the quality of data remains stable without unexpected anomalies or odd values. For example, the number of transactions for each weekday should be relatively similar—a sudden 10x increase on a single day would signal an inconsistency that needs investigation.
- Timeliness: The data is up-to-date and available when needed for decision-making. Imagine inventory levels that are updated in real-time as stock is sold or purchased or financial reports that are generated on a regular schedule to provide timely insights.
- Validity: The data conforms to defined business rules, constraints, and its specific format requirements. An email address with the ‘@’ symbol and domain suffix is considered valid. Similarly, a product code that falls within a specific range of allowable values, adhering to a predefined standard, would also be considered valid.
By monitoring data quality dimensions for data sources, we can identify the type of data reliability problem in a form that is easy to communicate to data stakeholders.
If you are interested in details, you can review the mapping of data quality checks to data quality dimensions in DQOps documentation.
How to measure data reliability
Data reliability is an abstract term, but thankfully, there is a way to measure it with tangible measures. If we can measure something with a number, we can identify problems with data reliability and improve it over time. The data quality measure we should use is a data quality KPI score.
We obtain a data quality KPI score by executing data quality checks on the monitored datasets at regular intervals, such as daily. The data quality KPI is the percentage of passed data quality checks out of all executed checks, as shown in the formula below.
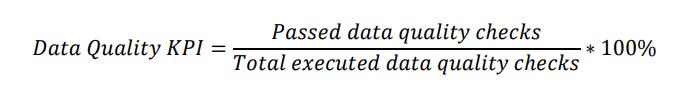
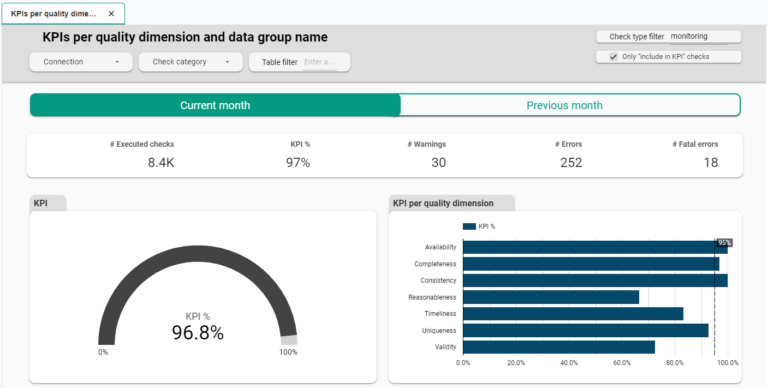
Using data quality dashboards, we can share the data quality KPI with data stakeholders. These stakeholders could be the data platform owners, data engineering teams, or data science teams that depend on the reliability of the data. The example below shows the current data quality KPI for the current month and the values from past months.
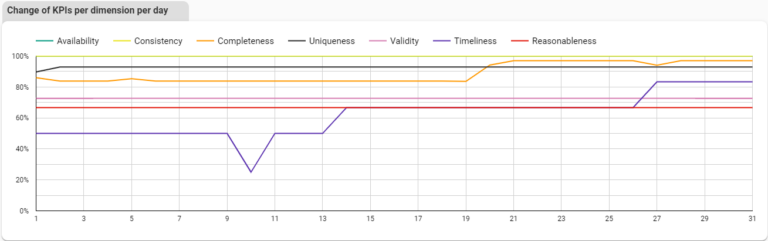
We can also measure the data quality KPIs daily, splitting the measures for each data quality dimension.
How data reliability differs from data validity
Data validity and data reliability are closely related but distinct. Think of data validity as a snapshot – is the format and structure of your data correct right now? Data reliability asks a bigger question – can you trust this data to be correct and usable over time? Data reliability and data validity are two essential concepts in data management. While they are closely related, they are not the same thing. That is why data validity is just one of the data quality dimensions that we monitor over time to ensure data reliability.
Data validity refers to the accuracy and correctness of data at a specific point in time. It ensures that the data is in the correct format, has the correct values, and is consistent with other data in the system. For example, a customer’s address should be a valid street address, and a product’s price should be a valid numeric value.
Data reliability, on the other hand, refers to the consistency and trustworthiness of data over time. It ensures that the data can be relied upon to be accurate and complete, even as it changes and is updated. For example, a customer’s address may change over time, but the data system should be able to track and update this change reliably.
Here are some key differences between data validity and data reliability:
- Data validity is a snapshot, while data reliability is a long-term commitment. Data validity focuses on the accuracy of data at a specific point in time, while data reliability focuses on the consistency and trustworthiness of data over time.
- Data validity is about the format and structure of data, while data reliability is about the quality of data. Data validity ensures that data is in the correct format and has the correct values, while data reliability ensures that data is accurate, complete, and consistent.
- Data validity is important for ensuring that data can be processed correctly, while data reliability is important for ensuring that data can be trusted to make decisions. Data validity is essential for ensuring that data can be used for its intended purpose, while data reliability is essential for ensuring that data can be used to make informed decisions.
Both data validity and data reliability are important for ensuring the quality of data. By understanding the differences between these two concepts, organizations can better manage their data and make informed decisions.
Ensuring data reliability with a data observability platform
Data reliability is crucial for businesses that rely on data-driven insights. To ensure data reliability, organizations need to set up a data observability platform. This platform will provide real-time insights into the health of data pipelines, allowing organizations to identify anomalies, inconsistencies, and potential errors before they impact decision-making.
The first step in ensuring data reliability is to identify the data assets whose reliability is most important. This can be done by considering the impact that unreliable data would have on the organization. For example, if a company relies on customer data for marketing campaigns, then the reliability of that data is critical.
Once the critical data assets have been identified, the next step is to decide which of the data quality dimensions are most important for that data asset. The data quality dimensions are accuracy, completeness, consistency, timeliness, and validity. For example, if a company is tracking customer orders, then the accuracy and completeness of the order data are critical.
There are two ways to integrate a data observability platform into a data environment.
- Embedded into data pipelines: We can integrate data reliability monitoring directly into data pipelines and ETL processes. This approach will allow us to instantly detect certain types of data quality issues, such as data in an invalid format. We can also stop data processing when corrupted data is identified, the invalid data will not spread into downstream data platforms. However, monitoring data reliability inside a data transformation code, which could be a source of data reliability issues, is unreliable and will not detect many data quality issues, such as data timeliness problems with outdated or missing data.
- Standalone data monitoring system: We can establish a data observability system that is independent of any data transformation code and connected to monitored data sources. This system will run autonomously. A standalone data observability platform will not detect data quality issues instantly. It will not prevent the loading of corrupted data. A standalone system will monitor all data quality dimensions at regular intervals, giving us a reliable data quality KPI score that we can trust.
To ensure data reliability instantly and without skipping any data quality dimension, we need a standalone data observability platform that exposes a client API for data pipelines. The platform will constantly monitor data reliability for all data quality dimensions. Still, the data pipelines and ETL processes can check the data quality KPI measures for data sources before the source data is passed through the data pipeline.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
What is DQOps Data Quality Operations Center
DQOps is a data observability platform that bridges the gap between monitoring data sources to measure data reliability and integrating data reliability assessment into data pipelines.
The unique features of DQOps are listed below.
- DQOps stores the configuration of data quality checks that cover all data quality dimensions in YAML files, becoming the data contract between data producers and consumers. An extensive DQOps client can be integrated into data pipelines and ETL processes to run data quality checks or look up each data asset‘s last known data quality KPI score.
- The DQOps user interface is designed for users who are unfamiliar with coding, SQL, and editing YAML files. You can define custom data quality checks to detect business-relevant issues. DQOps will show them in the user interface.
- DQOps has over 50 data quality dashboards to analyze data reliability from all angles. The dashboards can be customized for different use cases and data domains.
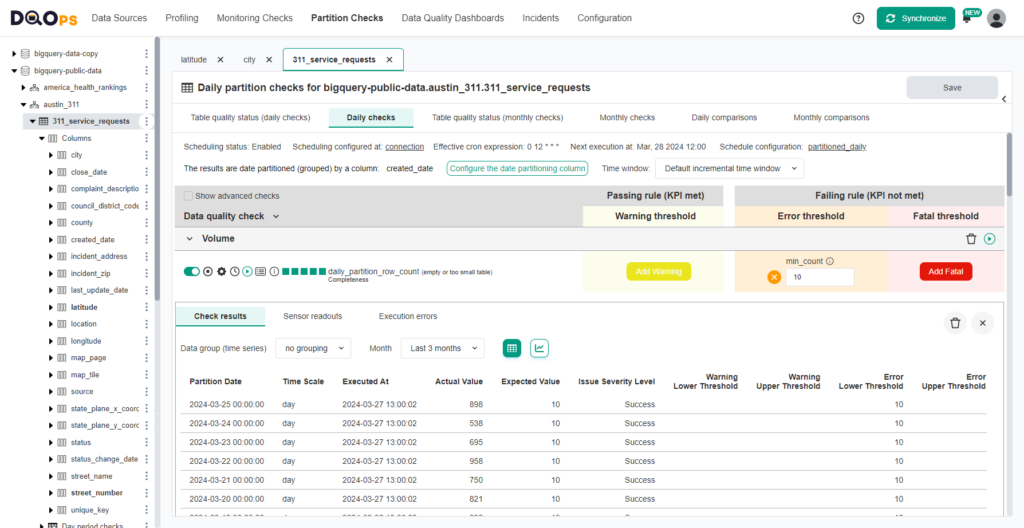
The following image shows the data quality check configuration screen to monitor daily data volume.
Check out the getting started with DQOps documentation to see DQOps in action.
You can also download our free eBook “A Step-by-Step Guide to Improve Data Quality,” which describes our proven data quality improvement process.




