
Data observability for data operations
Detect potential issues with data pipelines
Data operations teams ensure smooth data pipelines, readily available data for analysis, and overall data quality. However, manually monitoring data quality across complex pipelines is time-consuming and error-prone. Identifying and fixing the source of issues can be difficult without cooperation with data engineers or data source owners. These inefficiencies can lead to delays in resolving data quality issues and ultimately hinder the integrity of your data insights.
If you plan to create a data quality operations team or designate a data quality specialist, you need a platform that can support them. DQOps comes with a built-in user interface designed to centralize the entire data quality management process in one place, allowing you to address problems quickly.

Simplify data quality management
Built-in user interface
Manage both built-in and custom data quality checks with user-friendly interface.

Quality issues notifications
Integrate notifications about issues with Slack or other platforms using webhooks and assign incidents to other teams.
Source data quality checks
Detect any problems or instability in the data sources before they affect the entire data warehouse or data lake.
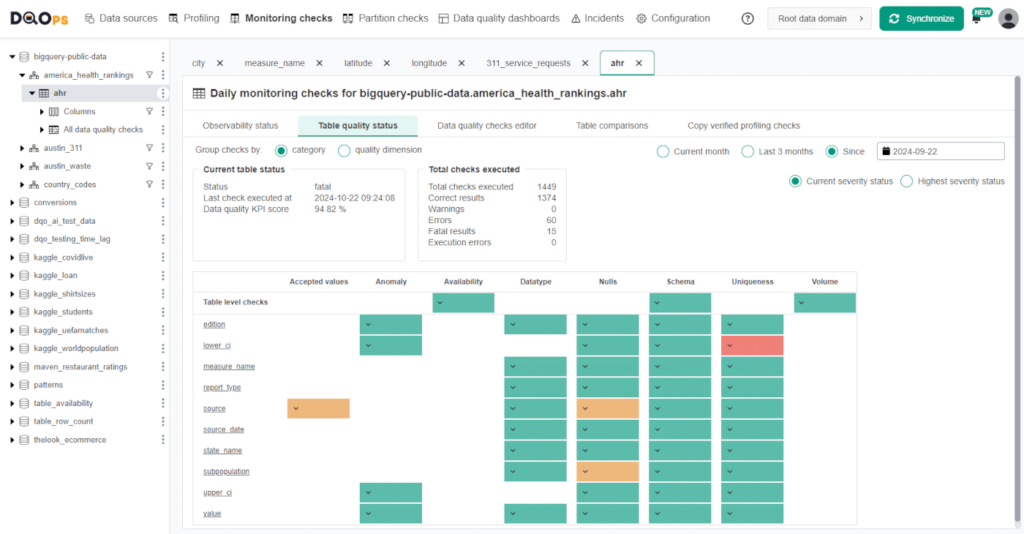
All downstream tables are always correct
DQOps platform helps define data quality metrics for the target tables and performs daily checks or checks after each data load to identify any missing data or quality issues.
- Detect data pipeline issues by monitoring target tables.
- Ensure daily that your target tables meet the requirements.
- Release your data pipelines with data quality checks monitored by DQOps to ensure they are working as expected.
DQOps platform helps define data quality metrics for the target tables and performs daily checks or checks after each data load to identify any missing data or quality issues.
- Detect data pipeline issues by monitoring target tables.
- Ensure daily that your target tables meet the requirements.
- Release your data pipelines with data quality checks monitored by DQOps to ensure they are working as expected.
All data is up to date

All data is up to date
DQOps platform comes with a verified set of timeliness checks to monitor the data freshness, staleness, and ingestion delay.
- Detect tables that have not been refreshed recently.
- Detect any missing time ranges if an incremental data load has missed a few days of data.
- Identify which tables are receiving updates inconsistently with a variable delay.
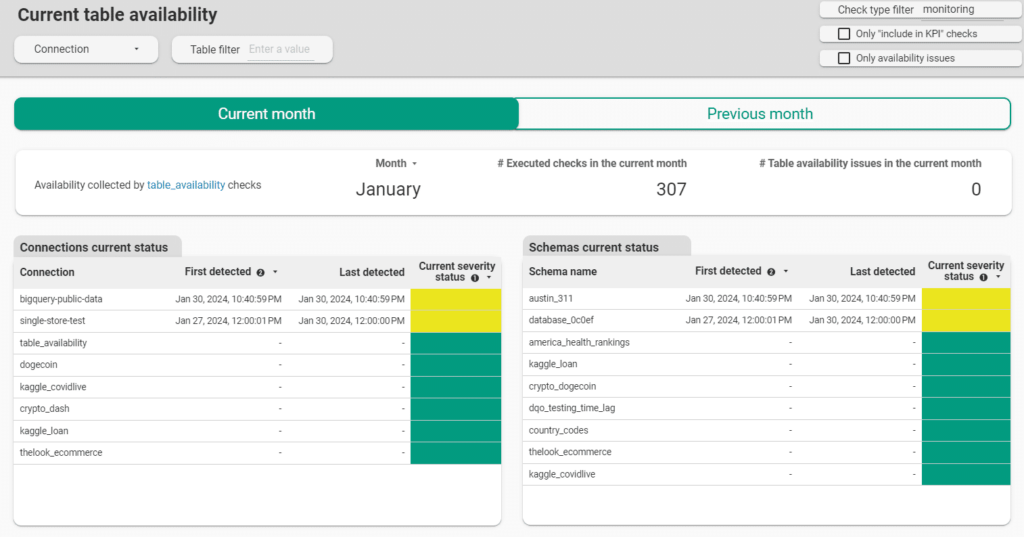
Database availability
DQOps can run simple queries on the database and data lake to detect when the table is not available for use.
- Ensure that all tables are available.
- Check that tables are populated with data.
- Monitor data availability issues on dedicated data quality dashboards.
DQOps can run simple queries on the database and data lake to detect when the table is not available for use.
- Ensure that all tables are available.
- Check that tables are populated with data.
- Monitor data availability issues on dedicated data quality dashboards.