
Reliable file ingestion is a critical data management process. It ensures that files are loaded once and files are never lost. In this blog post, we’ll explore a robust architecture designed to handle the ingestion of flat files (CSV, JSON, XML) while ensuring data quality and reliability.
Flat file ingestion is a common pattern in data architectures, especially those that involve exporting data from various sources and using a file drop location as an intermediary step before loading it into a data lake. Cloud-based data architectures often rely on this pattern to transfer data to their cloud-hosted data lakes.
The process typically involves transforming semi-structured files like CSV, JSON, and XML into a more efficient format like Parquet for querying. However, this process can be prone to errors. Corrupted files, incorrect structures, missing values, or data type mismatches can all disrupt the ingestion process and compromise the usability of the data.
To address these challenges, we’ll delve into the essential data quality validation steps that should be incorporated into a reliable file ingestion pipeline. By implementing these steps, we can prevent issues and establish straightforward procedures for fixing and reloading files, ultimately ensuring the integrity and reliability of our data ingestion process.
File Ingestion Reliability Issues
File ingestion, while crucial, can be fraught with challenges that impact reliability. A robust ingestion process should address these common issues to ensure smooth and continuous data integration. Here are some key areas where things can go wrong:
- File Duplication: The same file might be ingested multiple times, leading to duplicate records in your data lake.
- Corrupted Files: Partially uploaded or otherwise corrupted files can cause parsing errors and data loss. This is especially problematic for structured formats like JSON and XML.
- Schema Changes: Changes in the structure of incoming files, such as new, missing, or reordered columns, can disrupt the ingestion process and require adjustments to your data lake schema.
- Data Type Mismatches: Even if the file structure is correct, individual values might not conform to the expected data types. For example, a date field might suddenly appear in a different format.
- Business Rule Violations: The data might violate business rules or constraints defined by your organization. This could include things like invalid data ranges, inconsistencies, or missing required information.
The Principles of a Reliable File Ingestion Pipeline
A reliable file ingestion pipeline should be designed with resilience and maintainability in mind. It needs to gracefully handle unexpected errors, adapt to changes in data formats, and provide mechanisms for recovery and debugging. Here are some key principles to consider:
- Idempotency: The pipeline should be able to process the same file multiple times without creating duplicates or inconsistencies in the target data lake. This is often achieved by tracking ingested files and implementing checks to prevent re-processing.
- Phased Approach: Break down the ingestion process into distinct phases, each with its own validation and error handling. This allows for easier identification and resolution of issues.
- Schema Enforcement: Validate the structure of incoming files against expected schemas to catch inconsistencies early on. This can prevent downstream errors and data corruption.
- Data Type Validation: Ensure that data values conform to the expected types before loading them into the data lake. This includes handling type conversions and dealing with potential formatting issues.
- Data Quality Checks: Implement data quality checks at various stages of the pipeline to identify and flag potential issues. This could involve checks for completeness, consistency, accuracy, and adherence to business rules.
- Recoverability: Design the pipeline to be easily restartable from any stage. This allows you to recover from errors and resume processing without losing data or progress.
- Monitoring and Alerting: Implement monitoring and alerting to track the pipeline’s health and notify you of any errors or anomalies. This helps ensure timely intervention and minimizes data loss.
By adhering to these principles, you can build a robust and reliable file ingestion pipeline that ensures the integrity and availability of your data. A reliable data ingestion process ensures that each step is reproducible and idempotent. This means that in case of a failure, the file loading process can be restarted from the point of failure and continue without causing data duplication.
The following infographic presents the architecture of a reliable file ingestion pipeline that can ingest data from files to tables on a data lake.
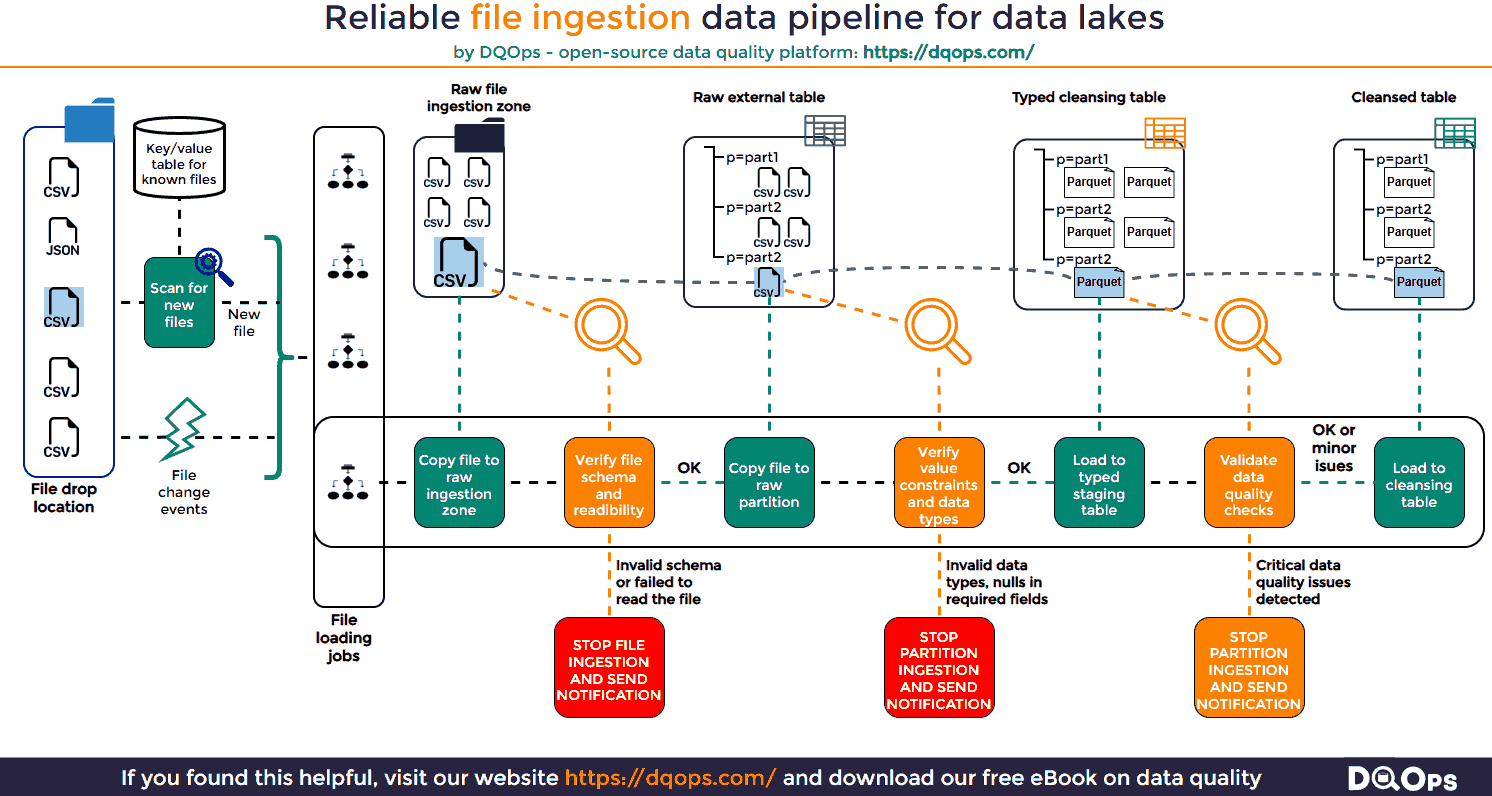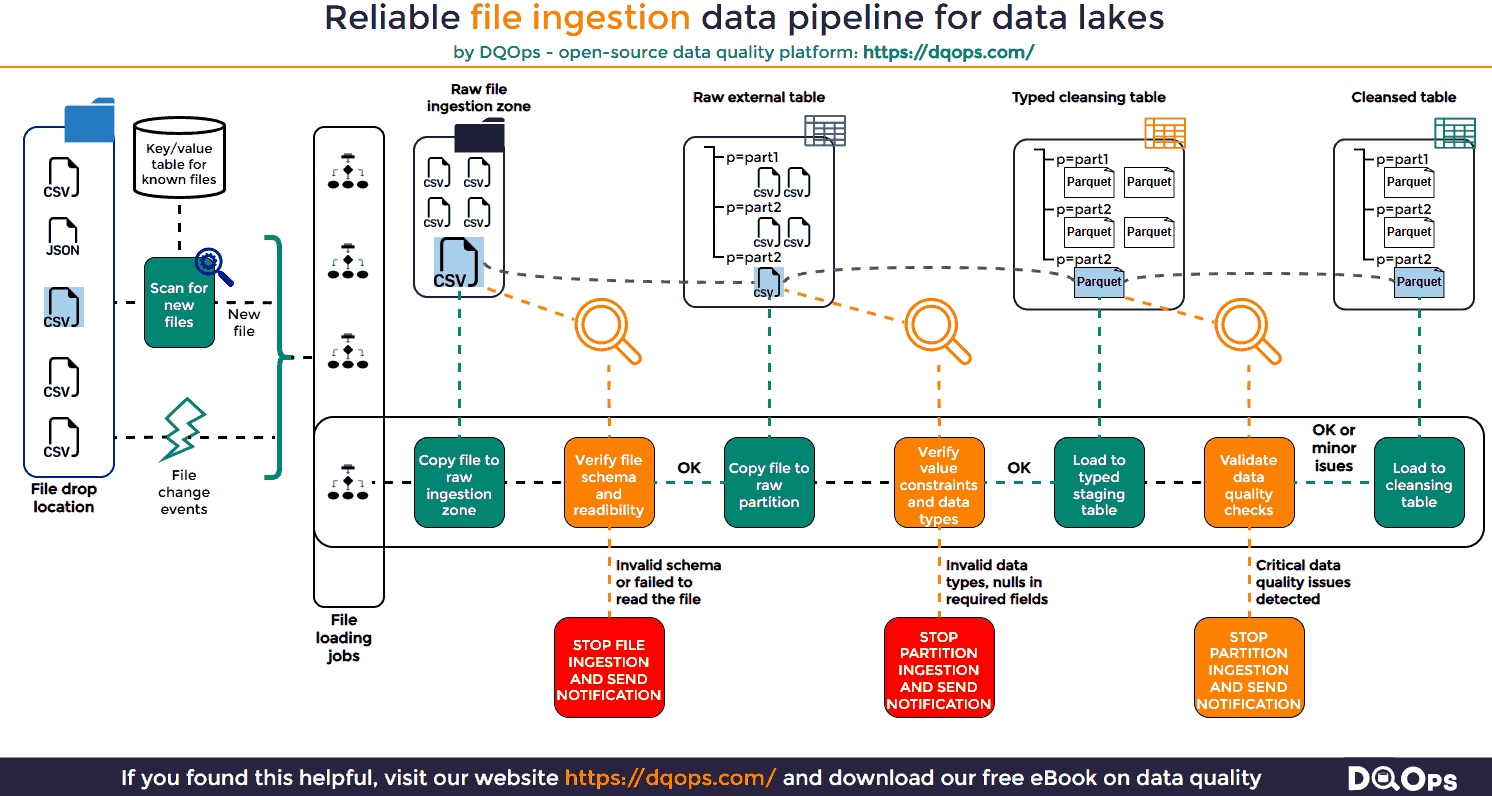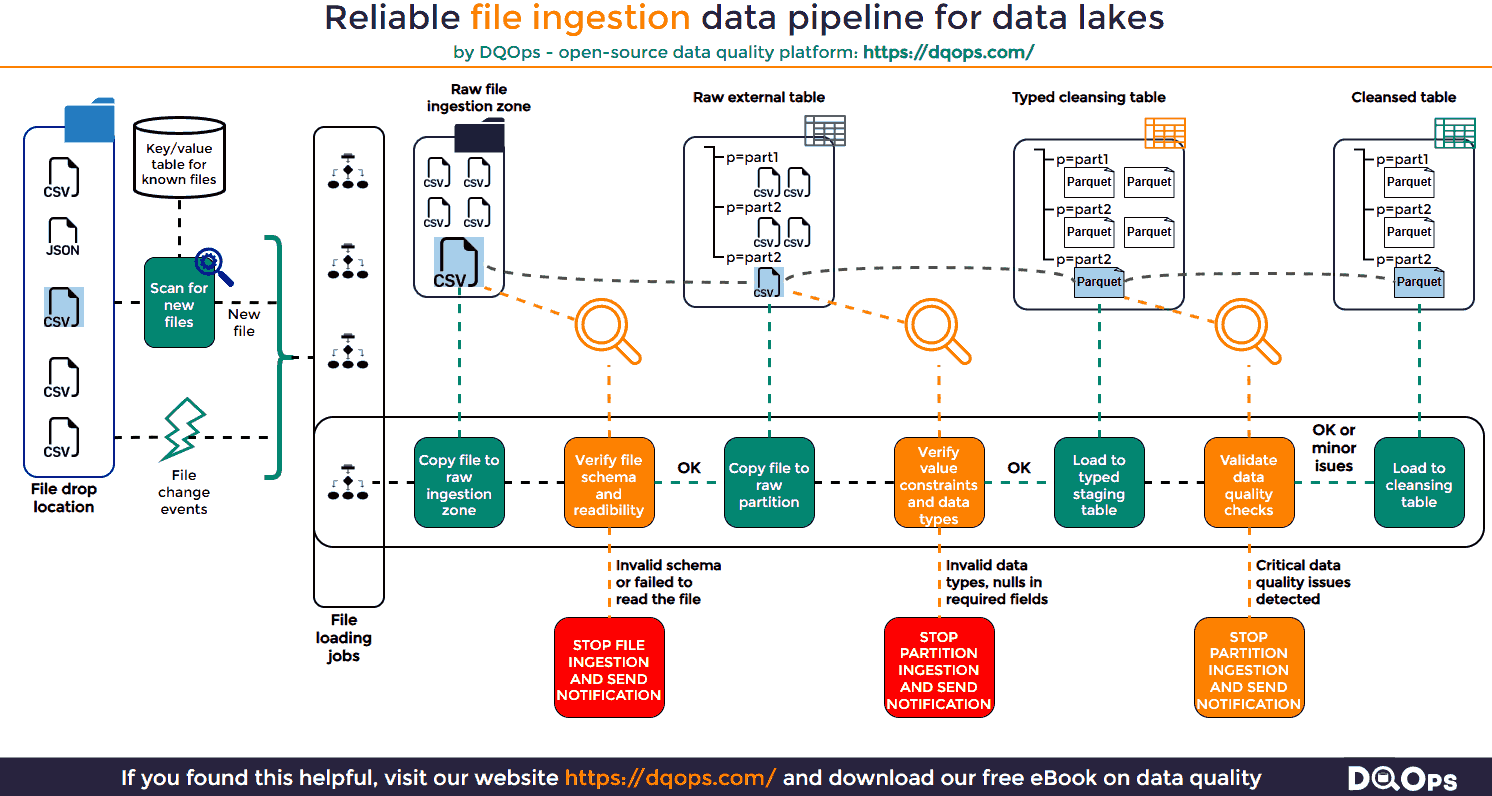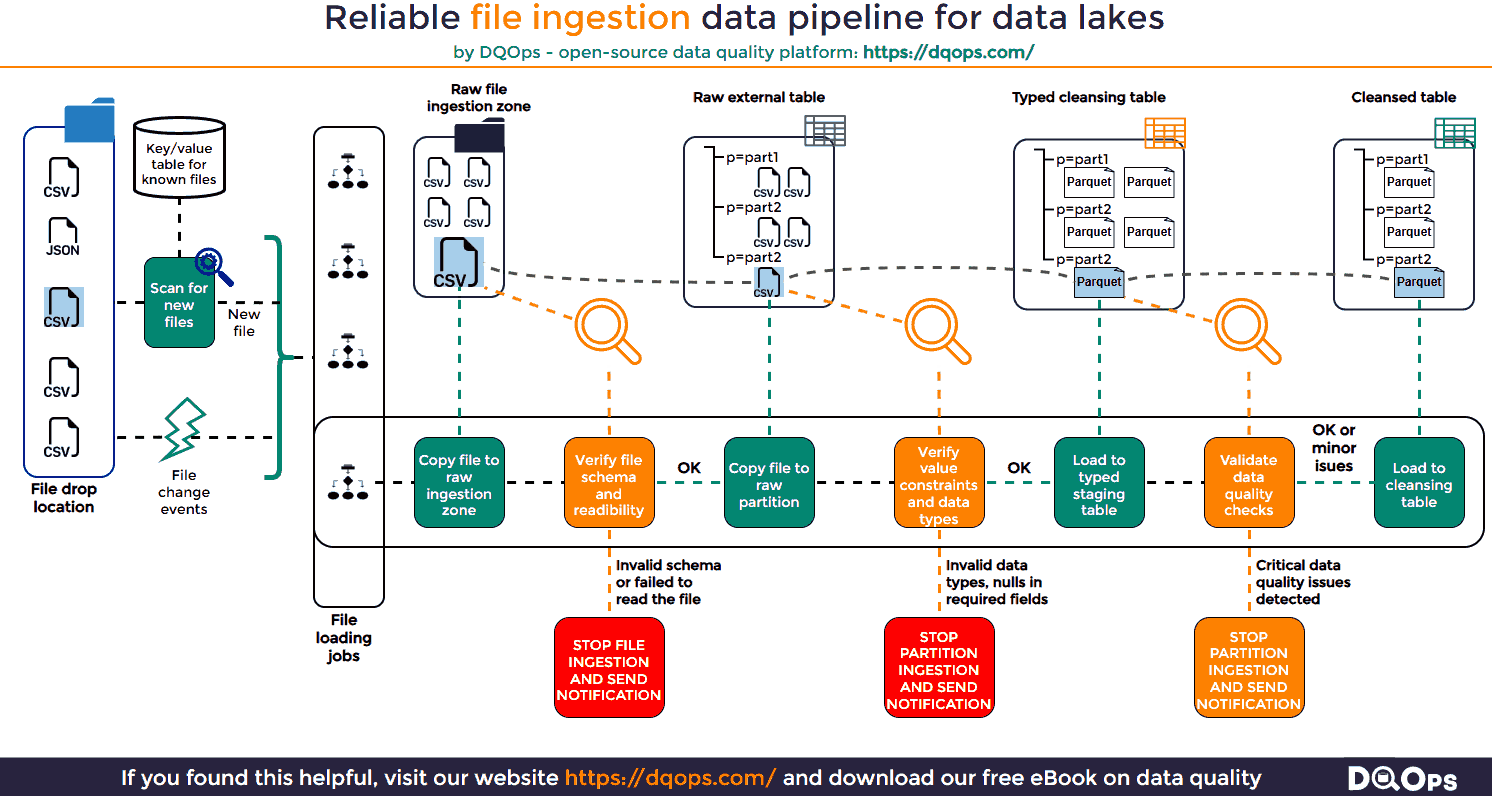
File Detection in File Ingestion Pipelines
File detection is a crucial first step in any reliable file ingestion pipeline. It ensures that new files are identified and processed while preventing duplicate ingestion. This concept, known as idempotency, is essential for maintaining data integrity and avoiding inconsistencies in your data lake.
There are two primary approaches to achieve reliable file detection:
Event-Driven File Detection
Cloud platforms like AWS, Azure, and GCP offer event-driven services that can trigger actions based on file system events. For instance, you can configure notifications to be sent to a message queue or a function when a new file is uploaded to a cloud storage bucket. This approach offers several benefits:
- Real-time detection: New files are detected and processed almost immediately.
- Scalability: Cloud providers handle the scaling and reliability of the event delivery mechanism.
- Reduced latency: Eliminates the need for continuous polling, leading to faster processing.
Database-Based File Tracking
A more traditional approach involves a dedicated component that periodically scans the file system for new files. To ensure idempotency, this component typically uses a database to track processed files. Here’s how it works:
- File Scanning: The component scans the file drop location for files with a recent creation or modification timestamp.
- File Locking: To avoid processing partially uploaded files, the component can attempt to acquire an exclusive lock on the file before processing.
- Database Lookup: The component checks its database to see if the file has already been processed. If not, it triggers a new ingestion job and records the file’s information in the database.
Both approaches have their merits. Event-driven detection offers real-time capabilities and scalability, while database-based tracking provides more control and flexibility. The choice depends on your specific needs and infrastructure.
File Structure Validation
Once a new file is detected and copied to the raw ingestion zone, it’s essential to validate its structure before proceeding further. This step helps identify corrupted files or files that deviate from the expected format, preventing downstream errors and data inconsistencies.
File structure validation typically involves two key checks:
File Readability and Integrity
This check ensures that the file is not corrupted and can be parsed correctly. For structured formats like JSON and XML, this involves verifying that the file adheres to the syntax rules and has all the required elements. For CSV files, it might involve checking for consistent delimiters, proper quoting, and the correct number of columns in each row.
Schema Validation
This check verifies that the file contains the expected columns or fields. For CSV files, this can be done by inspecting the header row. For JSON and XML files, it might involve analyzing a sample of records to determine the structure. The order of columns can also be validated if your processing logic relies on positional information.
If a file fails either of these checks, it indicates a potential problem. The file should be quarantined to prevent further processing, and an alert should be sent to the appropriate team for investigation. This could involve notifying the data provider to resend the file or engaging developers to update the ingestion pipeline if the file structure has legitimately changed.
By incorporating file structure validation early in the ingestion process, you can catch and address potential issues before they impact your data lake, ensuring data quality and reliability.
Data Types and Constraint Validation
After validating the file structure, the next crucial step is to assess the quality of the data itself. This involves checking individual data values against predefined constraints and expected data types. This step is often referred to as “data contract validation” as it ensures the data adheres to agreed-upon rules and standards.
To facilitate this validation, it’s often helpful to load the file into an intermediate data structure like an external table or a data frame. This allows you to leverage SQL or data processing libraries to perform efficient data quality checks.
Here are some common data validation checks that should be performed:
Nullability Checks
Verify that mandatory columns contain values and no nulls are present where they are not allowed.
Uniqueness Checks
Identify any duplicate values in columns that are expected to be unique. This can be done within the scope of the current file or across all files loaded into the target table.
Data Type Conversion Checks
Ensure that values in columns designated as numeric, date, boolean, or timestamp can be successfully converted to their respective data types. This helps identify formatting issues or invalid values.
Data Format Validation
Check that data conforms to specific format requirements. For example, if a column is expected to contain a formatted string like “City, Country”, validate that the values adhere to this format.
Range Checks
Validate that numeric values fall within an acceptable range.
Pattern Matching
Use regular expressions to validate that string values conform to specific patterns, such as email addresses or phone numbers.
If any of these checks fail, the data loading process should be halted, and an alert should be triggered. This allows data engineers to investigate the issue, potentially update the data transformation logic or schema, and re-process the file once the necessary adjustments have been made.
By implementing comprehensive data type and constraint validation, you can ensure that only high-quality, consistent data makes its way into your data lake.
Data Quality Checks
While technical data quality checks ensure the integrity and consistency of your data, it’s equally important to validate the data against business rules and expectations. This is where data quality checks come into play. These checks are often defined by data stewards, business analysts, or other data-literate users who understand the nuances of the data and its intended use.
Unlike technical validations that might halt the ingestion process upon failure, data quality checks are typically designed to flag potential data quality issues without necessarily stopping the workflow. This allows for more flexibility in handling data that might be technically valid but still raise concerns from a business perspective.
Examples of data quality checks include:
- Range checks: Verifying that values fall within expected ranges, such as price ranges or dates.
- Consistency checks: Ensuring consistency between related data points, such as customer addresses and shipping information.
- Completeness checks: Checking for missing values in critical fields.
- Accuracy checks: Comparing data against known standards or external sources to verify accuracy.
- Timeliness checks: Ensuring data is up-to-date and relevant.
Data quality platforms can provide a user-friendly interface for defining and managing these checks. These platforms often offer integrations with data pipelines, allowing you to trigger data quality checks on specific files or partitions within your data lake.
One such platform is DQOps, a data quality platform that empowers users to define and execute data quality checks within their data pipelines. Its user-friendly interface and collaborative features make it easier for both technical and non-technical users to participate in ensuring data quality.
By incorporating data quality checks into your file ingestion pipeline, you can gain valuable insights into the business context of your data and proactively address potential issues before they impact downstream analysis and decision-making.
How to Verify Data Quality to Ensure Reliable File Ingestion
Even with robust validation in place, unforeseen issues can arise in a file ingestion pipeline. That’s why it’s crucial to incorporate data observability to gain comprehensive visibility into the health and performance of your data ingestion process.
Data observability goes beyond traditional monitoring by providing a holistic view of your data ecosystem. It involves collecting and analyzing various metrics and signals to proactively identify and address potential problems.
Here’s how data observability contributes to reliable file ingestion:
- Error Tracking: Observability tools can capture and analyze errors or exceptions that occur during the ingestion process, providing insights into the root cause and frequency of failures.
- Pipeline Monitoring: Track key metrics like file processing time, data volume, and throughput to identify bottlenecks or performance degradation.
- Data Quality Monitoring: Continuously monitor the quality of ingested data by tracking metrics like null values, duplicates, and schema changes. This helps identify trends and anomalies that might indicate data quality issues.
- Data Freshness Monitoring: Track the age of the most recent data in your data lake to ensure data is up-to-date and timely. This can reveal issues with data delivery or pipeline failures that prevent new data from being ingested.
Data observability platforms like DQOps provide comprehensive features for monitoring and analyzing data pipelines. They can automatically detect anomalies, alert you to potential problems, and provide insights to help you troubleshoot and resolve issues quickly.
By incorporating data observability into your file ingestion strategy, you can gain a deeper understanding of your data pipeline’s behavior, proactively identify and address potential problems, and ensure the reliable and timely delivery of high-quality data to your data lake.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
What is the DQOps Data Quality Operations Center
DQOps is a data quality and observability platform designed to monitor data and assess the data quality trust score with data quality KPIs. DQOps provides extensive support for configuring data quality checks, applying configuration by data quality policies, detecting anomalies, and managing the data quality incident workflow.
DQOps is a platform that combines the functionality of a data quality platform to perform the data quality assessment of data assets. It is also a complete data observability platform that can monitor data and measure data quality metrics at table level to measure its health scores with data quality KPIs.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can monitor data sources and ensure data quality within a data platform. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time. This is a great resource to learn about data quality.




