
Author: Piotr Czarnas, DQOps Founder
Managing data quality lifecycle: Introducing DQOps Data Quality Operations Center
After over two years of development, we are releasing DQOps Data Quality Operations Center, our data quality and observability platform. We’re excited to show off the final version of our solution! After lots of hard work over the past two years, we’ve finally got it to a point where it’s got all the features we’ve been dreaming of. Now, you’ll get a comprehensive data quality process that handles everything from start to finish. We’ve put a lot of passion into building the DQOps Data Quality Operation Center, and it’s a real game-changer for anyone who works with data.
It has been nearly 20 months since we launched the initial preview. Over time, we have been actively seeking and incorporating valuable feedback into our solution. Consequently, we are pleased to announce the release of version 1.0, which addresses all known requirements. Remarkably, the code base has expanded significantly, showing a tenfold increase in size. Furthermore, the comprehensive documentation includes use cases and ready-to-use code samples for all data quality checks and operations. By leveraging DQOps, organizations can effectively automate their data quality processes.
We’d love to hear your feedback on GitHub.
Importance of Data Quality
Let’s skip the why-data-quality-matters talk; we all know it’s a big deal. All surveys constantly remind us how important it is to the data world. If you are reading this page, you must have faced data quality issues. It is one of the most critical challenges faced by many organizations today. Data quality issues can lead to various problems, including incorrect decisions, wasted time and resources, and damage to reputation.
Data quality issues can significantly impact an organization’s bottom line. A study by the University of Texas at Austin found that they cost businesses an average of $14.2 million per year.
DQOps Origins
DQOps is not the first data quality platform I have built. Before that, I designed and led the development of a custom data quality platform for one of the world’s 30 biggest companies, the biggest company in its market area. During this multi-year challenge, I led the development and managed a group of data quality engineers who were moving from one data domain to another.
Along that journey, the team transitioned through all three data platform maturity phases. We integrated the checks into the data pipeline, doing the work of data engineers, configuring and fine-tuning data quality, working in close collaboration with data owners, and finally monitoring the whole solution after we covered the data domains. We created over a thousand custom data quality checks to detect issues that mattered to the business users. We analyzed petabyte scale tables, applying incremental data quality monitoring at a partition level. The business sponsors were asking about our progress in improving the quality of critical data assets. We had to develop an agile approach to data cleansing by prioritizing tables and sharing the data quality KPIs of cleansed datasets.
We created machine learning features similar to those of many top-notch data observability vendors, but I will not name them here. Just shortly, we used machine learning to detect anomalies and autoconfigure alerting thresholds. We implemented similarity matching to cluster similar alerts, limiting the number of issues raised. We even applied machine learning for predictive failure detection. You heard that right. We were predicting data quality issues before they happened. I am not even counting anomaly detection with seasonability prediction. That is too obvious.
So, what did we do wrong? It was a platform that was too focused on managing data quality checks from the user interface. It was designed for data quality engineers. It suffered the same issue that hinders the data engineers in integrating big data governance and popular data observability tools directly inside the data pipelines. It was a centralized platform, tightly dependent on a single data quality database. Even though we employed an agent-based architecture, running remote data collection agents in all hyper scaler clouds, namely AWS, Azure, and GCP, it was still centralized.
The biggest challenge was at the operational level. The data engineering teams were making changes to the data model. Yes, great. We detected them as any other Data Observation tool would do. The timeliness metric was down because no new data was coming, and the schema drift checks detected schema changes. But now, the hard part was coming. The monitored table was not just decommissioned. It was migrated and renamed. All our work on setting up the data quality checks from the user interface had to be repeated. We have built several tools for importing and exporting the configuration. We had command-line tools for performing these changes in bulk.
To summarize our journey, let’s say we had to eat our dog food.
A vision of a better data quality platform
I had to rethink the whole approach to data quality. A better data quality platform should flawlessly follow the development process, allowing users to manage data quality checks at different stages. Data engineers should be able to work with code and use version control to store the configuration of data quality checks. Data consumers such as data scientists, data analysts, and data owners should be able to profile data sources and experiment with data quality checks quickly. Finally, all data quality checks already configured should build up a complete test suite that is monitored when the data platform is in production. The data observability should not only detect anomalies but also run all data quality checks selected by data engineers, data owners, data scientists, and data quality engineers.
Data stakeholders who are engaged with a data platform at different stages of maturity have different expectations of data quality.
- Data engineers need to integrate data quality checks directly in data pipelines, testing the quality of data sources before they are transformed and verifying the data quality of target tables populated by the pipeline. Today, we call this process Data Contracts. However, data contracts need a way to share the data quality expectations in files that are easy to modify and version in Git. The data quality platform should store the configuration in simple YAML files. If we store the configuration files locally, we need a decentralized data quality platform to run locally on the data engineer’s computer.
- Data consumers are our users who want to know the data quality score for tables and quickly assert their expectations about the data quality of essential data sources. For example, a data scientist looking for a data set to train a model wants to verify the completeness of some columns and test whether other columns contain only allowed values. They don’t want to touch the data pipeline code because something could break. Of course, data scientists can launch a Notebook and run a few statements with Pandas or PySpark. However, if they assess the data quality this way, it will be a one-time assessment. As soon as the data changes, their training pipeline will break. Using a web interface to find a table of interest, look up the current data quality status, and set up some data quality checks is much faster. These checks will run forever, and a more extensive data contract will accumulate into a more significant test suite to observe daily. Many organizations even hire dedicated data quality engineers who serve the role of software testers for data platforms. They need a simple way to manage big test suites. Remember those YAML files preferred by data engineers? Now, the data quality must offer a user interface to edit them.
- Data operations teams need a way to react quickly to changes in the data model. Over time, all these data quality checks defined by data engineers and data consumers have accumulated. The data support team must be able to reconfigure them. When tables are migrated between environments or databases, the configuration of the data quality checks must be fairly easy to update. The data quality platform should now become a Data Observability platform that monitors tables. It should manage data quality issues and send notifications.
All these users also share some requirements for a data quality platform. The prevailing requirement is extensibility, which, in the context of data quality, means the ability to define custom data quality checks and standards and apply AI for anomaly detection.
- Data engineers want to assert the data quality status of common columns shared across the data model, such as creation timestamps, keys, identifiers, etc. To avoid making mistakes, the same templated SQL query should be used to analyze all columns that play the same role. We need a templating engine to define reusable data quality checks.
- Data consumers such as data scientists, data analysts, and data owners want to run even more complex queries to detect data quality issues. They could copy SQL queries from dashboards and want to run them every day to detect data quality issues. However, a more straightforward use case is more likely. You have data dictionaries of accepted values for columns such as department names. Some columns must comply with a well-known pattern, such as account or invoice numbers. The best way to approach this requirement is by defining a custom data quality check that is not a hardcoded SQL query. You need a data quality check that you name validate_account_name. It should be defined as a bug-free templated query. The data quality platform should conveniently show it in the user interface, validating all parameters. That could even be desired by a data governance committee in your organization.
- Data operations teams want to be informed about anomalies, even various types of anomalies. They need a simple way to change the configuration of data quality checks that raise too many false positive data quality issues or even update the definition of a rule. That is not all. Over time, the data volume in the data platform will grow significantly. The SQL queries run by a data quality platform daily will substantially impact the database engine and decrease the performance of other queries, affecting end users. You will face a tough choice between running some data quality checks or disabling them to save some computing costs. There is a solution for that, and DQOps addresses it. You need incremental data quality monitoring that analyzes data quality at a partition level. With that approach in the past, I could monitor petabyte scale tables on BigQuery, keeping the BigQuery bill under control.
The transition from development through testing to operations has existed for a while. It is a standard model for custom software development. Let’s see what quality assurance practices from custom software development can be applied to a data platform when we work with data.
Please read the following paragraphs to learn how to apply software testing practices to data management and how other vendors address data quality requirements.
Data Quality vs Software Quality Assurance
Data quality shares many similarities with software quality assurance, a crucial aspect of the software development process aimed at building and maintaining custom software. Let’s examine the similarities and differences between software development and data management processes.

The goal of software quality assurance is to assess a system’s functionality. Testers perform actions that mimic how users would interact with the application, making the tests invasive. For instance, a test could involve creating a new administrator account and verifying that it has all the necessary access rights. For apparent reasons, you can’t do that on a production system daily.
Data quality is different. We are noninvasively testing the data that flows into and out of the data platform, validating it against the constraints and data contracts. We are not trying to replace the source data with fake values to validate all possible transformation outcomes. Every data platform has enough real data that we can use, so preparing mock data is unnecessary.
We can notice that developing software and building data platforms are pretty similar. Quality assurance can be applied during development, testing, and monitoring for problems affecting the solution.
- Tests executed inside data pipelines are similar to unit tests.
- Data quality checks are similar to performing system tests.
- Data observability is similar to infrastructure monitoring platforms.
One significant advantage of data quality over software quality assurance is its noninvasive nature. It allows us to run the entire suite of data quality checks on production data platforms daily. The data quality checks chosen by data engineers during the development phase transition into data observability checks, executed daily or after each data load operation.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
Introducing DQOps Data Quality Operations Center
DQOps is my second data quality platform, designed on the experience gained during that journey. I am not afraid to call it a true second-generation data quality platform because no other data quality vendor claims they redesigned their solution from scratch.
We named it DQOps Data Quality Operations Center because, like DevOps and DataOps, DQOps focuses on automating data quality. The Operation Center stands for the user interface for all users who work with data quality and want the work done quickly. That is our approach to a smooth transition from development to operations.
The main goal of DQOps is to facilitate the data quality process for the whole lifecycle.
- Data profiling: Data-literate users can profile data sources such as relational databases, data lakes, or flat files (CSV, JSON, Parquet). We implemented a library of over 150 data quality checks that cover all the most common issues.
- Data monitoring: After data profiling, pick the trustworthy data quality checks and run them daily as part of the Data Observability test suite.
- Data operation: Get notifications of data quality incidents and assign them to the right team. Validate the conformance to Data Contracts and data quality KPIs on data quality dashboards.
We wanted to build a platform that would quickly adapt to all stages of the data platform maturity. That means providing value for technical users and data consumers who prefer no-code data quality solutions. The complete redesign allowed us to build a very flexible solution.
- Multiple interfaces: To configure data quality checks, you can use any approach that suits you. You can manage checks from a user interface, configure them in YAML, automate with a Python client, or use a command-line interface.
- Flexible deployment: You can start DQOps locally on your laptop in 5 seconds to quickly profile a new CSV file. Alternatively, you can run the DQOps as a server that the whole team can reuse.
- Fully extensible: We divided data quality checks into two components: a sensor and a rule. A data quality sensor is an SQL query defined as a Jinja2 template that captures a measure such as a row count. A data quality rule written in Python validates the measure and can apply machine learning to detect anomalies.
Beyond that, DQOps is a fully distributed platform. Every DQOps instance maintains its local copy of the data quality results, which include the measures and data quality issues. The results are stored in an Apache Hive-compliant data lake. You can store the results locally or use a SaaS data quality data lake we set up for every user.
What is the purpose of the Data Quality Data Lake? When you set up your account, we create a private data warehouse for data quality results. DQOps has over 50 data quality dashboards that use that data. The dashboards will help you assess datasets’ data quality scores and investigate data quality issues. They calculate a data quality KPI score that you can share with your business sponsors to hold them accountable for data quality.
The following video shows how to register a new data source in DQOps, a CSV file, and run a standard set of data profiling checks. The default configuration of profiling checks identifies both empty columns and incomplete columns. The column in the video had some null values, so we changed the rule parameter to accept 20 null values, and the test passed.
DQOps YAML files as Data Contracts
DQOps stores the configuration of data sources and data quality checks in YAML files. You start DQOps in an empty folder, which becomes your DQOps user home folder. You can commit the files to a Git repository. The folder and file name structure follows the convention over configuration principle. You name the folder names as your data source names. The file names for every monitored table follow a naming convention: <schema_name>.<table_name>.dqotable.yaml. You can easily migrate the configuration of data quality checks between databases by copying the data source’s folder. You can register another table with the same schema as another table by copying the .dqotable.yaml file under a new name. Moving the configuration between development and production databases or following schema changes is simple.
We also simplified editing the configuration files in Visual Studio Code and many other code editors. Each DQOps YAML file has a reference to a YAML/JSON schema file, enabling an unprecedented editing experience in Visual Studio Code and preventing mistakes when editing the files manually.
- The code editor supports code completion for all configuration nodes and suggests the correct data quality check names and parameters.
- Invalid elements are highlighted at all levels.
- When putting a mouse pointer over any element, Visual Studio Code shows in-place documentation for all 600+ variants of data quality checks supported by DQOps.
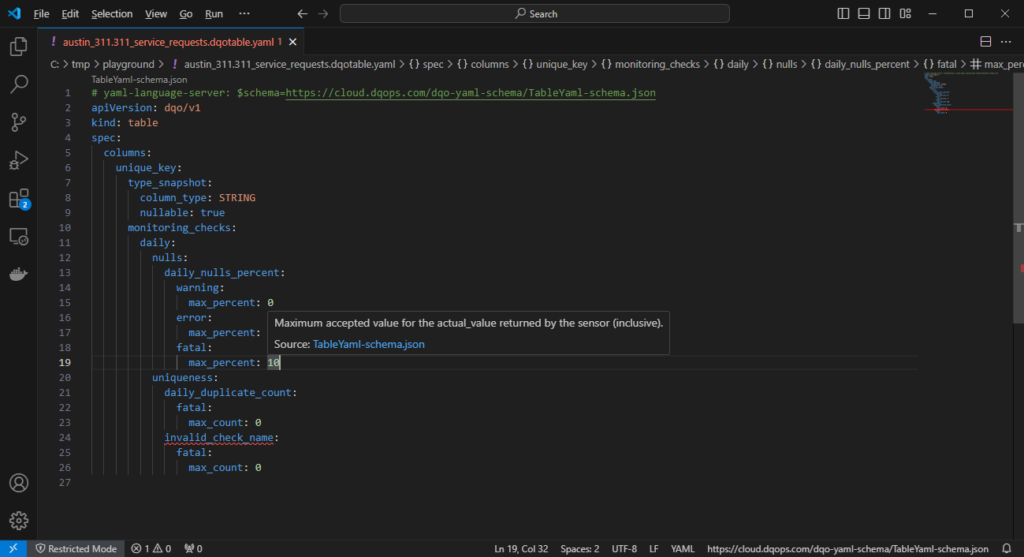
No-code editor for data quality checks
Managing the configuration of data quality checks in code may only work for technical users. As the data platform project transitions from development to operations, the support teams will eventually be responsible for monitoring the solution.
DQOps has a dynamic user interface for editing data quality checks. It shows both built-in data quality checks and your custom checks. The editor enables configuring data quality rules at three severity levels:
- Warning severity issues are used for anomaly detection or early warnings.
- Error severity issues identify real data quality issues that you want to fix. When errors are detected, DQOps decreases the data quality KPI score.
- Fatal error severity issues identify critical issues that should not affect downstream systems. You can use the DQOps Python client or the REST API from a data pipeline to ask DQOps for the table status. When a fatal issue is detected, you will stop the pipeline.

Define custom data quality checks
Extensibility is crucial for long-term data strategy. You will start your data quality journey by setting up Data Observability to detect the most common issues. It will detect anomalies, schema changes, missing rows, and null values. After that initial step, your users will ask to detect more complex data quality issues by running custom SQL queries. Do you remember when I wrote that you could migrate data quality checks between tables by simply renaming or making a copy of a DQOps YAML file a while ago? Hardcoded table and column names in custom SQL queries will make the migration challenging. It affects all data quality platforms that allow custom checks defined as in-place SQL queries.
DQOps has a different concept of creating custom data quality checks. You define custom data quality checks as templated queries defined as Jinja2 templates. DQOps replaces the table and column tokens with the fully qualified table and column names on which the check was activated.
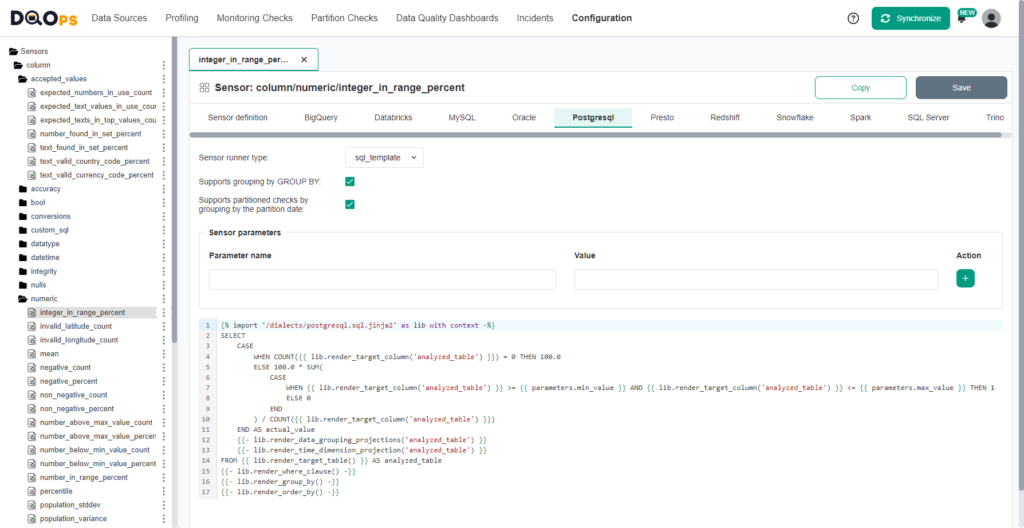
You can notice that the query template calls DQOps library functions to render the table name, filters, and groupings. All DQOps data quality check templates follow the same SQL query convention, making them very similar. This feature allows DQOps to combine multiple SQL queries generated for different data quality checks and activated on different columns. If you configure five data quality checks on 20 columns, DQOps will run only one SQL query instead of 100 small queries that would affect the performance of the monitored data platform.
Data quality automation
Modern DataOps teams focus on automation, turning data management orchestration platforms such as Apache Airflow into a centralized place for running and monitoring all data pipelines. Of course, the data pipeline can run data quality checks before or after loading the data. You just start a “run data quality checks” job from the pipeline by calling DQOps to run the checks.
DQOps provides a REST API and a typed Python client to run checks, import new tables, or ask DQOps about the table quality status. We extended the client beyond providing just the basic features. The Python client also supports all operations available on the DQOps user interface. The DQOps Python client’s documentation shows code samples you can copy-paste for all operations. No more guessing how to automate an operation.
The following example shows a call to run a subset of data quality checks that match a filter. We are running completeness checks on all fact_* tables. They are defined in the nulls category.
from dqops import client
from dqops.client.api.jobs import run_checks
from dqops.client.models import CheckSearchFilters, \
RunChecksParameters
api_key = 's4mp13_4u7h_70k3n'
dqops_client = client.AuthenticatedClient(
'http://localhost:8888/',
token=api_key
)
request_body = RunChecksParameters(
check_search_filters=CheckSearchFilters(
connection='sample_connection',
full_table_name='public.fact_*',
check_category="nulls",
enabled=True
),
dummy_execution=False
)
call_result = run_checks.sync(
client=dqops_client,
json_body=request_body
)
Anomaly detection
You don’t need to configure data quality checks on new data sources. DQOps applies a standard set of checks to all columns. The default checks detect schema changes, such as adding or removing a column, reordering columns, or changing data types. DQOps monitors volume changes and outliers in numeric columns.
The following example shows a chart for anomalies detected by DQOps.
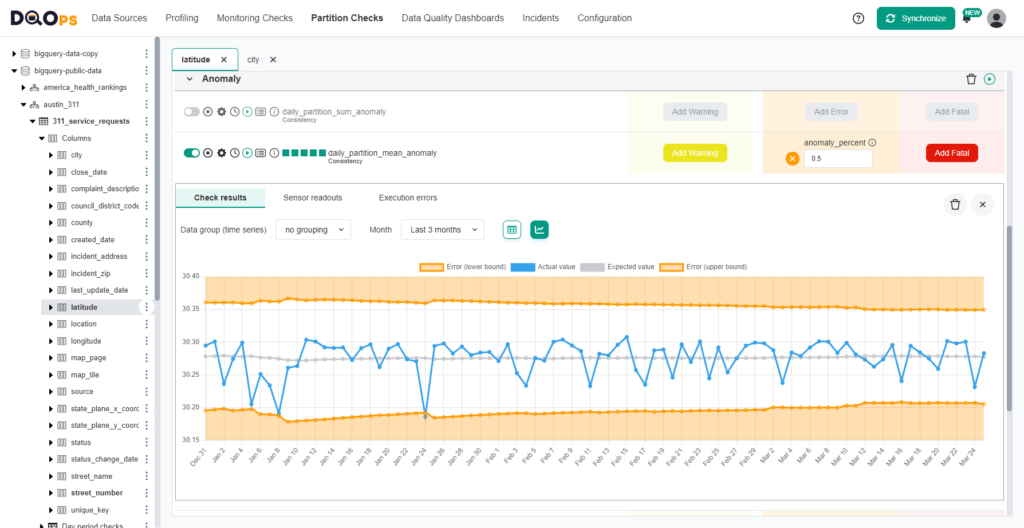
The list of default checks that DQOps runs on columns is configurable. DQOps stores the configuration of default data quality checks in “data quality check pattern” files. These files contain a customized configuration for all tables and columns that match a pattern. Suppose your database model follows a convention that every table contains an “inserted_at” column. In that case, you can define a pattern for all “inserted_at” columns that activates a data quality check that validates that the timestamps in that column will not be in the future.
Analyze huge tables incrementally
Detecting data quality issues in terabyte and petabyte scale tables cannot scale without partitioning. Such huge tables are time partitioned, and only new records are updated. Testing data quality for old records makes no sense because nobody would fix the issues. Also, running queries on big tables that contain a lot of historical data puts a lot of load on the database engine.
DQOps supports running data quality checks incrementally, grouping the data by day or month. DQOps’s daily partition checks analyze data partition by partition, generating separate data quality results for each daily partition. It is possible to run data quality checks in a time range to examine selected partitions.
The following screen shows the row counts of daily partitions captured by DQOps.
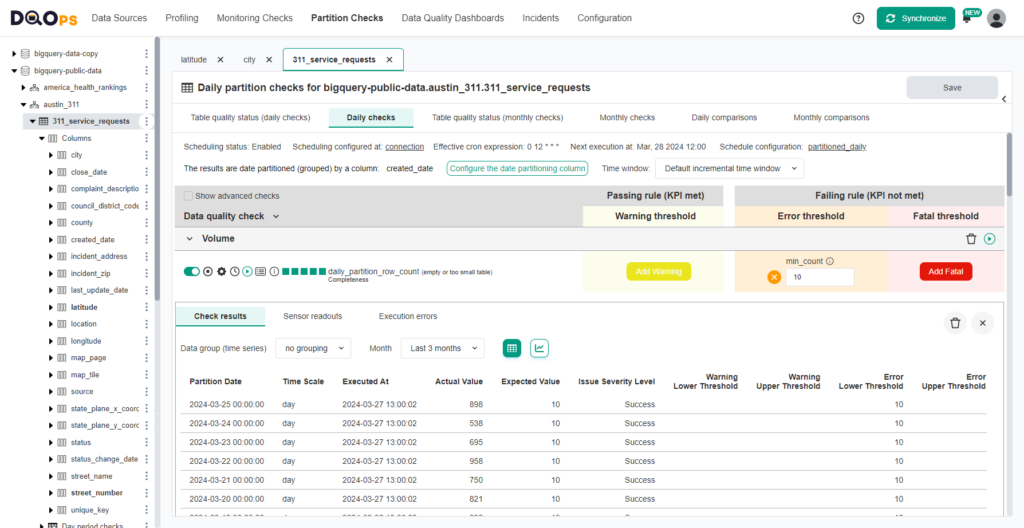
Data quality dashboards
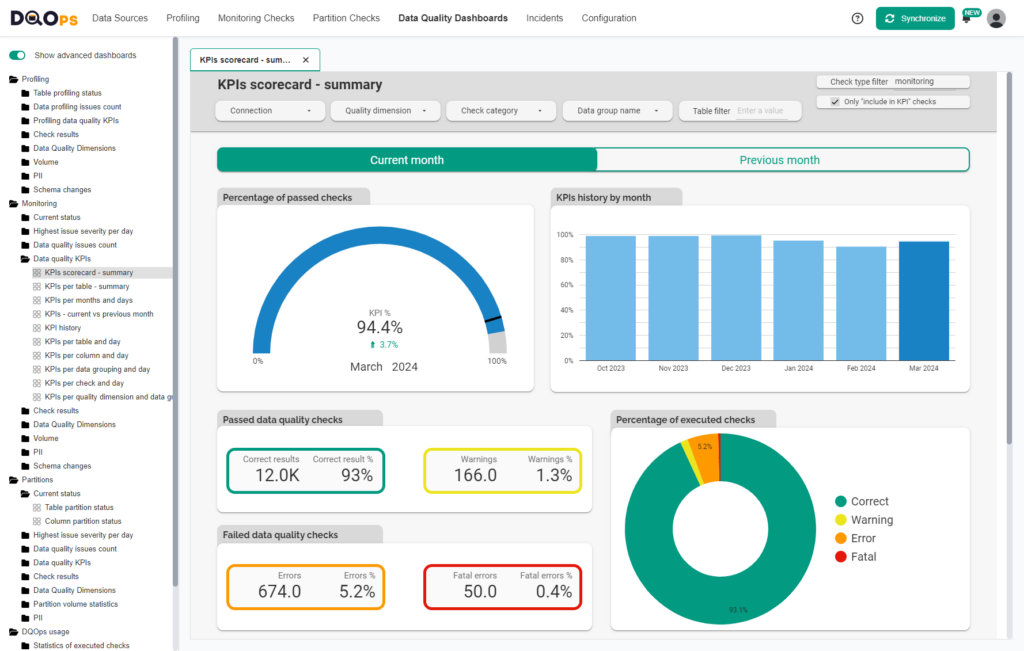
Data management initiatives yield better results when they gain support from top management. Business sponsors are not interested in technical details. They expect visibility of the whole process, proven with numbers.
DQOps provides a complementary SaaS data quality data warehouse for all users. The warehouse is accessed by data quality dashboards. These dashboards serve three purposes:
- Show the current data quality status for all data sources, tables, and columns.
- Provide a detailed view of various data quality metrics, such as timeliness or schema changes.
- Calculate a data quality KPI score for all data elements to identify the trend in the data quality improvement.
The following screen shows a Data Quality KPI scorecard dashboard that shows the progress in stabilizing data quality over the following months. The dashboards are implemented in Looker Studio and are fully customizable if you need to adapt an existing dashboard to show different results.
Getting started with DQOps
DQOps is a data quality and observability platform that you can use right now. Its installation options allow flexibility, and it supports multiple installation options. The supported operating systems are Linux, MacOS, and Microsoft Windows. The deployment architectures cover both a standalone local installation and a production setup on a server supporting multiple users.
The standalone deployment is compelling because DQOps can be downloaded as a PyPI package and started as a local data quality tool to empower data scientists with a data quality tool that profiles data sources. A standalone instance provides multiple interfaces to interact with the platform:
- User interface for managing data sources, profiling data, and running data quality checks.
- Command-line interface with autocompletion of data sources, tables, columns, and check names.
- Python client that can be used in a Notebook to perform data quality checks.
- YAML files that can be edited in Visual Studio Code and checked into a Git repository.
The installation options using pip and docker are summarized below.
Install DQOps locally in 30 seconds
DQOps is a data quality and observability platform that works both locally or as a SaaS platform.
Next steps
The best way to get familiar with DQOps is by reading our getting started tutorial in the DQOps documentation.
The other sections in DQOps documentation worth reading are:
- The DQOps concept describes all features.
- The installation guide provides detailed instructions for running DQOps as a PyPI package, docker image, or starting DQOps directly.
- The data sources section shows the steps to connect to all supported databases.
- The categories of checks section is a detailed guide to detecting common data quality issues.
- The use cases and examples section shows selected processes of working with DQOps.
You can also download my eBook, which shows a detailed process for improving data quality. This process uses data quality KPIs to prioritize tables and issues to be fixed. So far, we have managed to improve data quality for many projects, starting from a data quality KPI that was less than 50% and improving it to a score of around 99%. This eBook was written to describe that process step-by-step.




