
Data quality is an important topic that must be handled as early as possible to prevent the spread of bad data across downstream systems. The data pipelines are the first component that has access to corrupted source data, and the data pipelines are the first component that can potentially load bad data to a target table. Integrating a data quality validation process into a data pipeline can serve as the first line of defense from data quality issues.
By implementing data quality checks throughout the pipeline, organizations can prevent the loading of bad data into target tables and detect any data quality issues early on. This can save time and resources spent debugging and fixing data discrepancies and ensure that downstream processes are operating with high-quality data.
Table of Contents
You can have a data observability for free
Before you keep reading, DQOps Data Quality Operations Center is a data quality and observability platform that can be easily integrated into data pipelines. Please refer to the DQOps documentation to learn how to get started.
Benefits of testing data quality at data loading
Integrating data quality checks into a data pipeline has several important benefits. It can improve the overall data management process and ensure that the data being processed is reliable and accurate.
Here are some key benefits:
- Prevention of loading bad data: By implementing data quality checks before data is loaded into target tables, organizations can prevent invalid or erroneous data from entering the system. This proactive approach safeguards the integrity and trustworthiness of the data being processed, minimizing the risk of downstream processes being affected by bad data.
- Early detection of data quality issues: Continuous data quality monitoring throughout the pipeline allows organizations to promptly identify any issues. This enables swift corrective action before the issues escalate and cause substantial disruptions or inaccuracies in the data. Early detection of data quality problems minimizes downstream impacts and facilitates timely resolution.
- Improved data lineage and traceability: Integrating data quality checks into the pipeline enhances data lineage and traceability. Organizations can track the origin and transformation history of their data, facilitating easier debugging and troubleshooting of issues. This comprehensive understanding of the data’s journey helps ensure data integrity and enables effective data management.
- Improved compliance and regulatory requirements: Organizations subject to compliance or regulatory requirements can leverage data quality checks to demonstrate adherence to the required standards. By implementing robust data quality measures, organizations can provide evidence of their commitment to data accuracy and compliance, mitigating the risk of legal or reputational issues.
Data Quality vs Data Observability
Before discussing the integration points between a data pipeline and a data quality platform, we must understand what type of data quality platform will be used.
Data quality is a very old topic that has been widely discussed for decades. Traditional data quality platforms are focused on testing data assets such as tables and columns using data quality checks. Data quality platforms can work as standalone solutions used by data quality specialists. We can envision them as a particular type of business intelligence suite designed to analyze data assets from the data quality perspective. Many data quality platforms also support integration points to schedule data quality checks using a client interface. However, remote access to a data quality platform is impossible for data quality libraries implemented as embeddable Python functions.
Data observability is a new concept related to improving data quality through automation. Data observability platforms are standalone solutions that use their own job scheduler to run a basic set of data quality checks on monitored data assets at regular intervals. They are designed to detect table scheme changes and significant volume changes, monitor the availability of data sources, and detect data anomalies. The most significant difference between data quality and observability platforms is the ability to detect anomalies.
Anomaly detection can provide an early warning sign that the dataset’s dynamics have changed, leading to data drift. It is essential for data warehouses hosted in the cloud because it can have financial consequences due to an increased cost of data storage and computing resources. Data drifts are also the biggest problem in machine learning, decreasing the model performance over time.
Schema change detection and anomaly detection by data observability platforms are possible only because these platforms collect all data quality metrics in a data quality metrics database. The collected metrics include the historical data about the data volume (the table’s row count), data timeliness, and various statistics about all columns, such as a minimum, maximum, mean, or median value.
Using both a data observability platform to detect changes and anomalies and a data quality platform that can perform data validation and reconciliation checks is essential to covering all aspects of data quality. However, using two separate platforms is not required when a modern data quality platform that also includes all features of data observability is used, such as the DQOps Data Quality Operations Center. Modern data observability platforms expose client libraries for testing data quality. Data engineering teams can integrate these data quality libraries into data pipelines to verify data quality before loading source data or after updating target tables.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
Integrating data quality steps into ETL/ELT pipelines
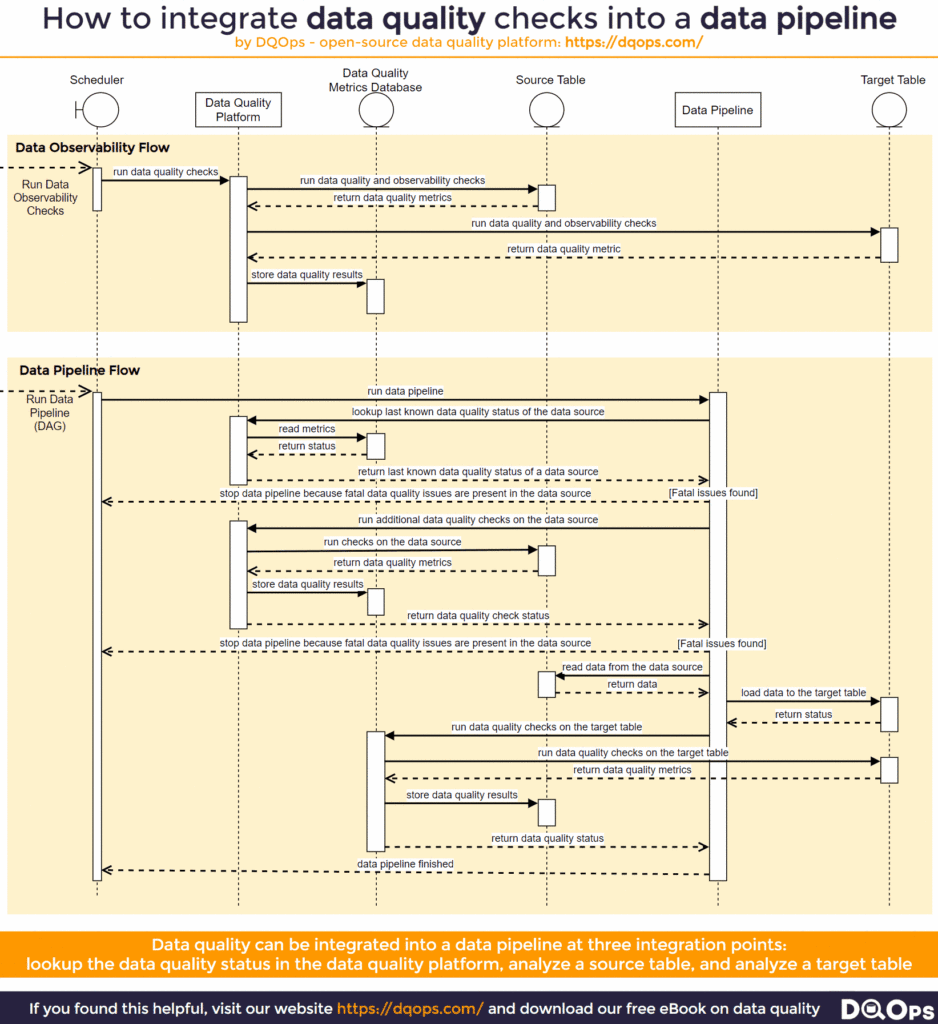
The data pipeline can validate data quality at three stages.
- Lookup the last known data quality status. The data pipeline can use a client API of the data observability platform to check the last known data quality status of a source table measured by data monitoring (observability). If a serious data quality issue has been detected, such as a breaking change to the table schema, the data pipeline can stop execution to prevent corrupting target tables.
- Run a complete test suite of data quality checks on the source table. Validating the table in the source table just before reading and transforming it into a target table is the last line of defense. It also ensures that no new data has appeared in the source table since the data observability platform has analyzed it. The data pipeline can continue or stop execution when a severe data quality issue is detected.
- Run a complete test suite of data quality checks on the target table. Because the target table is created or updated by the data pipeline, performing data quality checks at the end of a data pipeline is a wise idea. It is especially important if the scheduling platform (such as Airflow) will activate additional data pipelines that will transform the target table further. For example, the first data pipeline loads raw tables to a staging zone, performing an initial data conversion.
The whole process is described in the following sequence diagram. It shows the integration points between a data quality/observability platform, the data quality metrics database, the source and target tables, and the data pipeline that orchestrates the whole process.
The diagram is divided into two independent flows. The flow at the top shows how the data observability platform continuously analyzes the data assets. The flow at the bottom shows the internals of the data pipeline, starting with the data quality status lookup in the data quality metrics database and continuing through running data quality checks and transforming the tables.
Running data quality checks in Apache Airflow
DQOps provides a Python client library for use in Python code and an Apache Airflow operator for integration into a DAG flow.
The following example shows a DAG flow that executes data quality checks before running the data loading process. The DQOps operator stops the data pipeline when a fatal severity data quality issue is detected.
import datetime
import pendulum
from airflow import DAG
from dqops.airflow_operators.run_checks.dqops_run_profiling_checks_operator import DqopsRunProfilingChecksOperator
with DAG(
dag_id="my_connection_dqops_run_profiling_checks",
schedule=datetime.timedelta(hours=12),
start_date=pendulum.datetime(2023, 1, 1, tz="UTC"),
catchup=False,
) as dag:
run_checks_task = DqopsRunProfilingChecksOperator(
task_id="dqops_run_profiling_checks_operator_task",
base_url="http://host.docker.internal:8888",
connection="example_connection",
full_table_name="maven_restaurant_ratings.consumers"
)
If the data pipeline is not implemented as a Python code, DQOps provides a REST API with command-line samples using CURL. These examples can be easily copied and used in other data pipeline tools, such as traditional ETL platforms or Microsoft Azure Data Factory.
Getting started with DQOps Data Quality Operations Center
DQOps Data Quality Operations Center is a platform that can be used and integrated into data pipelines immediately. Please follow the gettings started section of the DQOps documentation to learn how to download and start a local DQOps instance. The manual for Apache Airflow integration provides additional code samples for detecting the data quality status of a source table.
We also suggest downloading our free eBook “A step-by-step guide to improve data quality” which provides proven practices for implementing data quality in an organization.




