
Data validity is a data quality dimension that verifies whether data adheres to predefined formats and constraints. This means ensuring data is in the correct format, such as phone numbers following a specific pattern, email addresses containing an “@” symbol, or dates falling within a valid range. Without data validity, data can be meaningless or misleading, leading to flawed analysis and poor decision-making.
To guarantee data validity, various techniques are employed. Data validity checks are crucial for detecting common data quality issues, such as values exceeding acceptable limits in an age column, dates formatted incorrectly, or invalid country names. These checks act as a first line of defense against inaccurate or inconsistent data. Further measures to ensure data validity include database constraints, which enforce data integrity at the database level by preventing the entry of invalid data. Data validation during data entry provides immediate feedback to users, prompting them to correct errors as they occur. Additionally, data contracts, which define the expected format and type of data received from various sources, play a key role in maintaining data validity across different systems and applications.
Table of Contents
You can monitor data validity for free
Before you continue reading, DQOps Data Quality Operations Center is a data observability platform designed to measure and improve data validity. Please refer to the DQOps documentation to learn how to get started.
What is data validity
Data validity tells us that data is correctly formatted and ready to use. This means dates are written in the expected way, quantities aren’t negative, and codes follow the correct patterns. Think of it like this: if you’re collecting customer information, a valid email address will have the “@” symbol and a valid phone number will follow a recognized structure. This kind of data is instantly usable for analysis, reporting, or can be safely stored in a database without needing any fixes.
Now, just because a phone number or email is correctly formatted doesn’t mean it’s accurate. Data accuracy is a different data quality dimension altogether. Accuracy measures whether the data reflects the real world. That phone number might be valid, but it could be an old number the customer no longer uses. Similarly, a valid email address might belong to someone else entirely. Even though it’s valid, it’s not accurate.
Valid data must meet certain rules to ensure it’s usable. Imagine you’re entering invoice data. A valid invoice date can’t be in the future, and it probably shouldn’t be older than the date your company was founded. These are examples of “out-of-range” errors. Another common issue is incorrect data formats. A typing mistake might add an extra letter to a number field, like “12.33x” instead of “12.33”. Sometimes, validity issues involve relationships between different pieces of data. For instance, the net price plus the tax amount should equal the gross price.
It’s also important to remember that data validity is just one aspect of data quality. If a required field is left blank, that’s not a validity issue; it’s a data completeness issue. Similarly, duplicate records point to data uniqueness problems. By clearly distinguishing between data validity, completeness, uniqueness, and other data quality dimensions, you can simplify error reporting and make it easier to address the root causes of data problems.
Examples of data validity issues
Understanding data validity often comes down to recognizing the common ways data can go wrong. Let’s explore some typical validity issues, grouped by category, to see how they can affect your data:
Incorrect Data Entry
Human error is a constant factor in data management. Typos, misunderstandings, or simple mistakes during data entry can lead to various validity problems. Imagine a customer database with email addresses like “john.doe@gnail.con” or phone numbers with missing digits. These errors might seem minor, but they can prevent you from contacting customers, sending updates, or conducting marketing campaigns. Similarly, incorrect zip codes can disrupt deliveries, and invalid UUIDs or IP addresses can cause problems with system integration and data analysis.
Inconsistent Value Formats
Data often comes from different sources, and those sources might have their own ways of doing things. This can lead to inconsistencies in how data is formatted. A classic example is date formats: one system might use “DD-MM-YYYY”, another “YYYY-MM-DD”, and yet another “Month Day, Year”. This makes it a nightmare to analyze data across different systems or time periods. The same applies to units of measurement (kilograms vs. pounds) or even naming conventions (e.g., “customer ID” vs. “client ID”). These inconsistencies hinder data integration and make it difficult to get a clear picture of your data.
Outliers and Extreme Values
Sometimes, data values are simply too extreme to be believable. A customer age of 150 or a product price of -$100 immediately raises a red flag. These outliers can be caused by data entry errors, system glitches, or even deliberate manipulation. If left unchecked, they can skew your analysis and lead to incorrect conclusions. Imagine calculating the average customer age with that 150-year-old outlier – it would significantly distort the result.
Invalid Values
Certain data fields have inherent restrictions on the values they can hold. For example, a “profit margin” field shouldn’t contain negative values, and the “number of years of experience” for an employee can’t be a negative number. These invalid values often indicate errors in data collection, calculation, or entry. They can also highlight inconsistencies in your data model or business rules.
Invalid Reference Data
Many datasets rely on reference data – external lists or tables that provide valid values for specific fields. A “country code” field, for instance, might refer to a list of valid country codes. If this reference data is outdated or incorrect (e.g., using an old state abbreviation), it can lead to a cascade of problems. Imagine a marketing campaign targeting a non-existent country or a shipment being sent to an invalid address due to an outdated zip code.
Uncontrolled Text in Categorical Fields
Some fields are meant to have a limited set of possible values. A “department” field, for example, might have options like “Marketing”, “Sales”, and “Human Resources”. If users are allowed to enter free-form text in these fields, you’ll end up with inconsistencies. “Marketing Team”, “Marketing Dept”, and “Mktg” all refer to the same department, but they create separate categories in your data. This makes it difficult to aggregate data, generate reports, and maintain consistency.
Causes of data validity issues
Data validity issues can creep into your datasets from various sources. Here’s a breakdown of the main culprits:
Human Error in Data Entry
Typos happen. Whether it’s a misplaced keystroke or a misunderstanding of the required format, human error during data entry is a major source of data validity problems. This is especially true when application user interfaces lack robust validation checks. Without real-time feedback on the form, users can easily submit incorrect email addresses (like “john.doe@gnail.con”), phone numbers with missing digits, or dates in the wrong format. The problem is compounded when data is collected using tools like Excel, which offer limited validation capabilities.
Inconsistent Data Collection Processes
Even with well-designed forms, inconsistencies in how data is collected can lead to validity issues. Imagine a scenario where multiple users are responsible for entering customer information. If these users follow different conventions or lack proper training, discrepancies are inevitable. One user might diligently enter first and last names with proper capitalization (“John Smith”), while another might opt for lowercase (“john smith”). Or, consider a phone number field. One user might include the country code (+1-555-123-4567), another might omit it (555-123-4567), and yet another might add parentheses and hyphens ((555) 123-4567). These variations create inconsistencies and hinder data analysis.
Errors in Data Transfer and Transformation
Data often goes through multiple stages before it reaches its final destination. During these data transfer and transformation processes, things can go wrong. Incorrectly defined transformation rules can truncate or alter data, leading to invalid values. For instance, a rule designed to capture only the first 10 digits of a phone number might inadvertently truncate a valid international number like “+1 (123) 456-7890”, resulting in an invalid “+1 (123) 456-789”. Similarly, errors in data mapping or conversion can introduce inconsistencies and invalidate your data.
Consequences of data validity issues
Invalid data can have far-reaching consequences for your organization. Here’s a breakdown of the potential fallout:
- Poor Decision-Making: Inaccurate data can lead to misguided insights and flawed decisions. Imagine targeting the wrong age group in a marketing campaign due to invalid birthdate information, or delaying a product launch because of incorrect inventory figures. These decisions can result in wasted resources, missed opportunities, and damage to your organization’s reputation.
- Wasted Time and Resources: Data analysts often spend a significant amount of time cleaning and correcting invalid data. This time could be better spent on valuable analysis that drives business insights and innovation. Data validity issues essentially divert resources away from core activities and hinder overall productivity.
- Disrupted Workflows and Reduced Efficiency: Invalid data can throw a wrench into your operational processes. Consider a logistics department struggling to fulfill orders due to incorrect addresses, or a customer service team unable to resolve issues because of inaccurate customer information. Data validity is essential for smooth and efficient operations. When data is unreliable, your processes suffer.
- Erosion of Trust: Trust is essential in any business. Customers who receive incorrect information or experience issues due to bad data will quickly lose faith in your brand. Similarly, shareholders and investors may question the reliability of your decision-making if data integrity is compromised. Invalid data can damage your reputation and undermine your credibility.
- Regulatory Compliance Issues: In many industries, data regulations mandate specific data quality standards. Failing to maintain valid data can result in hefty fines and penalties. Compliance with regulations like GDPR or HIPAA often hinges on the accuracy and validity of your data. Ignoring data validity can have serious legal and financial ramifications.
How to check data validity
Detecting data validity errors requires specialized tools and a systematic approach to ensure that errors are reproducible. Here’s how to ensure your data meets the required standards:
Utilize Data Quality Tools
Data quality tools are essential for efficient data validity checks. These tools come equipped with a range of pre-built checks that analyze your dataset and flag potential validity issues. For instance, they can detect dates stored in incorrect formats, invalid email addresses, or values that fall outside acceptable ranges. Tools like DQOps offer a comprehensive suite of checks to identify the most common data validity errors.
Conduct a Data Quality Assessment
If you’re dealing with a new dataset that hasn’t been previously validated, a thorough data quality assessment is necessary. This involves several key steps:
- Profile the Data: Use a data profiler to scan your dataset, collect sample values, and calculate metrics about the data distribution. This helps identify inconsistencies and potential validity issues. For example, a profiler might reveal that a “Country” column contains values like “USA”, “Canada”, and “usa”, highlighting an inconsistency in capitalization.
- Configure Data Quality Checks: Define specific data quality checks tailored to your data and business rules. These checks are essentially tests that verify the validity of values in each record. For instance, a check for a valid age might require values to fall between 18 and 100 years.
- Run Data Quality Checks: Execute the configured checks using your data quality tool. The tool will scan your data and pinpoint records that violate the defined rules.
- Review Data Validity Errors: Carefully examine the flagged errors. Sometimes, these might be false positives due to errors in configuring the checks themselves. For example, you might have accidentally set the valid age range to 28-100 instead of 18-100. However, if the checks are correctly configured, the detected errors are likely genuine validity issues.
Assess Data Quality Error Importance
Not all data validity errors are created equal. Some might have a negligible impact on your business, while others can cause significant disruption. It’s crucial to assess the severity of each error and prioritize accordingly. Errors in comment fields, for example, might be less critical than errors in customer addresses or financial data. For those errors that require attention, a data cleansing project may be necessary to identify the root cause, eliminate the source of invalid values, and correct existing errors.
The difference between data integrity and data validity
While often used interchangeably, data validity and data integrity are distinct concepts that operate at different levels. Understanding their nuances is crucial for maintaining high-quality data.
Data Integrity: Enforcing Validity at the Database Level
Data integrity focuses on maintaining the consistency and accuracy of data within the database itself. It ensures that data remains valid throughout its lifecycle by enforcing rules and constraints. Think of database constraints as guardians at the gate, preventing invalid data from entering in the first place. These constraints can ensure that required fields are not missing, unique values remain unique (often enforced by unique indexes), and data conforms to predefined rules.
Data Validity: A Broader Perspective
Data validity, on the other hand, has a broader scope. It’s about ensuring data is correct and meaningful regardless of where it resides. While data integrity mechanisms built into databases can contribute to data validity, they are not always sufficient. Data validity must be actively checked and tested using dedicated data quality tools and processes.
Limitations of Database Constraints
While database constraints are powerful tools for enforcing data integrity, they have limitations:
- Not Always Supported: Many modern analytics platforms, especially those dealing with big data and formats like Parquet, lack robust support for database constraints. This means data validity cannot be fully guaranteed at the database level.
- Limited Expressiveness: Database constraints are typically expressed as SQL expressions, limiting their complexity and flexibility. They might not be able to handle intricate validation rules, especially those requiring lookups in external databases or complex calculations.
- Real-time Enforcement: Database constraints operate in real-time, rejecting invalid records during data insertion. This can be problematic if the application or data pipeline loading the data cannot handle these rejections gracefully. Invalid records might be lost, and users might not receive immediate feedback to correct errors.
The Advantages of Data Validity Checks
Data validity checks offer greater flexibility and control:
- Validate Anytime, Anywhere: You can perform data validity checks at any point in the data lifecycle, not just during data entry. This allows for more comprehensive data quality monitoring and remediation.
- Handle Errors Gracefully: Data validity checks provide a list of invalid records, allowing data stewards or engineers to decide how to handle them. This might involve correcting the data, investigating the source of errors, or implementing preventive measures.
In essence, while data integrity mechanisms contribute to data validity, they are not a replacement for dedicated data validity checks. A comprehensive data quality strategy incorporates both to ensure data accuracy and reliability
How to achieve data reliability with data validity and integrity testing
Data reliability is the holy grail of data management. It signifies a state where your data is consistently accurate, valid, and trustworthy. Achieving this requires a multi-faceted approach that combines data validity testing with data integrity constraints.
The Power of Combining Validity and Integrity Testing
Think of data integrity constraints as your first line of defense. By implementing constraints within your database, you prevent invalid data from being stored in the first place. This ensures that applications and data pipelines cannot introduce inconsistencies or errors at the source.
However, database constraints alone are not enough. Data validity testing adds an extra layer of protection by actively monitoring your data for potential issues. Data quality tools can run as independent components within your data platform, continuously scanning for validity errors. When a problem is detected, these tools trigger a data quality incident workflow, notifying data operations teams or data stewards who can then investigate and address the issue.
Data Cleaning: Automated Remediation
To further enhance data reliability, consider incorporating data cleaning techniques into your data pipelines. Data cleaning automates the process of identifying and correcting invalid data. By understanding the root causes of data errors, you can implement data transformations that fix incorrect values or enrich data with information from trusted sources. For instance, a data cleaning script could standardize phone number formats or correct invalid dates.
Benefits of this Combined Approach
By combining data integrity constraints, data validity testing, and data cleaning, you create a robust system for ensuring data reliability. This approach offers several benefits:
- Proactive Prevention: Database constraints prevent invalid data from entering your systems.
- Continuous Monitoring: Data validity testing identifies potential issues before they escalate.
- Automated Remediation: Data cleaning automatically corrects invalid data, reducing manual effort.
- Improved Trust and Confidence: Reliable data fosters trust among users and stakeholders.
- Enhanced Decision-Making: Accurate and consistent data leads to better informed decisions.
In conclusion, achieving data reliability requires a holistic strategy that leverages both data validity and data integrity mechanisms. By implementing a combination of preventive measures, continuous monitoring, and automated remediation, you can ensure your data remains a trustworthy asset for your organization.
Data validity testing techniques
Ensuring data validity requires a multi-pronged approach that incorporates various testing techniques at different stages of the data lifecycle. Here’s a breakdown of common methods:
Data Validation at Data Entry
This technique aims to prevent invalid data from entering your systems in the first place. By implementing validation rules directly within data entry forms or as database constraints, you can provide immediate feedback to users and prevent incorrect data from being submitted. This approach is most effective in controlled environments where you have full control over the application and its user interface. Some SaaS and PaaS platforms, like Salesforce, also offer features for defining custom data validation rules.
Batch Data Validation
Batch data validation involves periodically scanning your data for validity errors using a data quality tool or custom scripts. This is particularly useful for identifying and correcting existing errors in large datasets. You can schedule these validation checks to run at regular intervals, ensuring ongoing data quality monitoring.
Real-time Data Validation
For systems that rely on real-time data streams, such as IoT data collectors or financial trading platforms, real-time data validation is essential. This involves validating data as it arrives, either within the API used by data publishers or through a dedicated validation component in the data stream. Invalid records can be routed to a separate stream for manual review or automatically corrected using predefined rules.
Choosing the Right Technique
The most suitable data validity testing technique depends on your specific needs and context:
- Data criticality: For highly critical data, a combination of data entry validation and real-time validation might be necessary.
- Data volume: Batch validation is often more efficient for large datasets.
- System architecture: Real-time validation is crucial for systems that rely on continuous data streams.
- Resource constraints: Data entry validation might require more upfront development effort but can save time and resources in the long run.
By strategically implementing these techniques, you can establish a robust data validation framework that ensures the accuracy and reliability of your data throughout its lifecycle.
Strategies for ensuring data validity
Data validity is crucial to any successful data-driven initiative. To maintain high-quality, trustworthy data, consider these essential strategies:
- Implement Data Validation Rules: Establish data validation rules within your systems to catch invalid entries at the point of capture. This could involve configuring input fields to accept only specific types of data (e.g., numbers for a phone number field) or setting constraints on acceptable values (e.g., disallowing ages below 18). These rules act as gatekeepers, ensuring that only valid information enters your systems from the outset.
- Regularly Clean and Standardize Data: Even with robust validation, errors can still slip through. Regular data cleansing is crucial to identify and rectify inaccurate or inconsistent data. This might involve correcting typos, standardizing formats, or removing duplicates. Data standardization ensures consistency across your datasets. For example, enforcing a specific format for addresses (street address, city, state, zip code) simplifies analysis and reduces errors.
- Maintain Accurate Reference Data: Data validity often hinges on the accuracy of reference datasets. These datasets provide the valid values for specific fields, such as country codes or product categories. Keeping these reference datasets accurate and up-to-date is vital for ensuring the validity of dependent fields.
- Profile Your Data: Data profiling helps uncover hidden patterns and potential validity issues. By analyzing data distribution, identifying outliers, and examining data patterns, you can pinpoint areas that require closer scrutiny. For example, a high number of negative values in a “profit margin” field could signal data errors.
- Continuously Monitor Data Quality: Proactive data quality monitoring is essential for maintaining data validity. Leverage automated data quality platforms that continuously monitor data sources, evaluate data quality rules, detect issues, and manage resolution workflows. More advanced solutions, such as DQOps (Data Quality Operations Center), provide comprehensive monitoring capabilities. This allows you to identify and address validity issues before they impact your business operations.
By incorporating these strategies into your data management practices, you can establish a robust framework for ensuring data validity and maintaining the integrity of your data assets.
How to define data validity checks in data contracts
Data contracts are a powerful tool for ensuring data validity, especially when data is exchanged between different systems or organizations. They act as agreements between data producers (those who create and share data) and data consumers (those who receive and use the data), establishing clear expectations about the data’s format, content, and quality.
Data Contracts: A Formal Agreement for Data Quality
Imagine a business application (the data producer) that collects customer information. This application might have robust data validation rules in place to ensure data accuracy. On the other side, we have a data lake (the data consumer) that wants to receive this customer data but prefers to avoid the cost and effort of extensive data cleansing. This is where data contracts come in to ensure data validity.
Data contracts are typically defined in machine-readable formats like YAML. They provide comprehensive documentation of a dataset, including:
- Ownership and Purpose: Information about the data owner and the intended use of the data.
- Schema Definition: A detailed description of the dataset’s structure, listing all columns, their data types, and any relevant metadata.
Embedding Data Validity Checks
Crucially, data contracts can also include data validity rules. By specifying these rules within the contract, the data producer can clearly communicate the validation checks that have already been applied to the data. This provides valuable information to the data consumer, assuring them of the data’s quality and reliability.
For example, if the data producer has enforced database constraints to ensure all email addresses are correctly formatted, they can include a corresponding validity rule in the data contract. This tells the data consumer that they can rely on the email addresses being valid and don’t need to perform additional checks.
Benefits of Using Data Contracts for Data Validity
- Improved Communication: Data contracts foster clear communication between data producers and consumers, ensuring everyone is on the same page regarding data quality expectations.
- Reduced Data Cleansing Effort: By specifying pre-validated data, data contracts minimize the need for extensive data cleansing on the consumer side.
- Increased Trust and Reliability: Data contracts provide assurance that the data meets agreed-upon quality standards.
- Streamlined Data Integration: Well-defined data contracts simplify data integration processes, reducing errors and inconsistencies.
By incorporating data validity checks into data contracts, you create a robust framework for ensuring data quality throughout the data exchange process. This leads to more efficient data pipelines, improved data governance, and ultimately, better business outcomes.
How to test data validity with data quality checks
Data validity testing relies on specialized data quality checks designed to identify potential errors and inconsistencies. Data quality tools like DQOps provide a comprehensive suite of these checks, enabling you to thoroughly assess the validity of your data. Let’s explore some common types of data validity checks:
- Valid Range Checks: These checks verify that numeric values fall within an acceptable range. For instance, you might check that the “age” column contains values between 18 and 100, or that transaction dates fall within a specific timeframe, such as after the company’s founding date.
- Numeric Checks: Numeric checks can identify invalid values within numeric columns. A common check is to detect the presence of negative values in fields where they are not allowed, such as a “tax rate” column.
- Pattern Validation Checks: Many data fields adhere to specific formats or patterns. This includes tax identifiers, invoice numbers, department codes, product codes, cost center codes, and even phone numbers. Pattern validation checks, often using regular expressions, ensure that these values conform to the expected format.
- Profile Your Data: Data profiling helps uncover hidden patterns and potential validity issues. By analyzing data distribution, identifying outliers, and examining data patterns, you can pinpoint areas that require closer scrutiny. For example, a high number of negative values in a “profit margin” field could signal data errors.
- Valid Dates Checks: Valid date checks go beyond simply verifying that dates fall within a specific range. They can also detect dates in the future, which might be invalid in certain contexts (e.g., an invoice cannot have a sales date in the future due to regulatory reasons). Additionally, these checks can combine pattern matching with date validation to ensure that dates or timestamps provided in text format adhere to the correct format (e.g., “YYYY-MM-DD”).
- Dictionary Checks: Dictionary checks ensure that column values match one of the accepted values from a predefined list. This list can be embedded within the check itself (useful for small, fixed lists like status codes) or stored in an external data dictionary managed by a master data management team. This ensures consistency and accuracy across your data
By utilizing these checks, DQOps ensures that your data adheres to defined formats, contains expected values within specified ranges, and avoids nonsensical entries. This promotes data accuracy and overall data quality. Be sure to check our documentation for a complete list of data quality checks measuring data validity.
How to report data validity errors
Effective communication is crucial when it comes to addressing data validity issues. Once errors are identified, it’s essential to report them to the appropriate data owner, whether it’s the person who provided the dataset or the owner of the business application that collected the incorrect data.
A best practice is to leverage a data quality tool to define and execute your data validity checks. These tools often include a feature called “data quality error sampling,” which allows you to extract a subset of records flagged as invalid. Exporting these errors into a CSV file provides a convenient way to share them with data owners. These files can be easily opened in Microsoft Excel or other tools for review and analysis. Data owners can then confirm the existence of the errors and take appropriate action to correct them.
A key advantage of using a data quality tool for this process is the ability to store and maintain your data validity checks. Once the data is corrected, you can re-run the same checks to verify that the issues have been resolved. This ensures ongoing data quality and prevents recurring errors.
Clear and concise reporting of data validity errors facilitates collaboration between data stakeholders, promotes accountability, and ultimately leads to improved data quality across your organization.
Challenges in data validity testing
Data validity testing, while crucial, comes with its own set of challenges, especially when dealing with large and complex datasets. One of the biggest hurdles is identifying all potential validity issues in massive datasets. When data spans various formats, involves multiple columns, and exhibits intricate relationships, pinpointing every inconsistency can be like finding a needle in a haystack. You might uncover and cleanse one type of error, only to discover another lurking beneath the surface. For example, you might fix dates formatted as “December 5th, 2024”, but then encounter another batch written as “Dec 5, 2024” and yet another as “2024-12-05”. This constant evolution of data errors can be time-consuming and resource-intensive.
Furthermore, data is dynamic, and its patterns can change over time. What was considered valid yesterday might be invalid today. This requires continuous adaptation and refinement of your data validity checks. New formats, evolving business rules, and unexpected data entry patterns can all introduce new validity challenges. Manually defining and maintaining data validity rules for these evolving scenarios can be tedious and error-prone.
Fortunately, advancements in data quality tools offer solutions to these challenges. Many tools now incorporate automation and machine learning to streamline data validity testing. For example, DQOps provides a data quality rule mining module that automates the process of defining data validity rules and configuring their parameters. It can analyze data patterns, identify common values, and automatically generate regular expressions or detect valid date formats. This significantly reduces the manual effort required and improves the accuracy of your data validity checks. By embracing automation and machine learning, you can overcome the challenges of data validity testing and ensure the ongoing accuracy and reliability of your data, even in the face of growing complexity and evolving data landscapes.
Data validation and business User engagement
Data validation is not solely a technical endeavor; it requires active collaboration and engagement with business users. Data specialists responsible for data validation and cleansing may not possess the domain expertise to understand all the nuances of the data and the processes that generate it. They need to consult with business users to interpret data anomalies, understand the context of errors, and determine the appropriate corrective actions.
For instance, if a data quality check flags a series of transactions with unusually high values, data specialists might need to consult with business users to determine if these transactions are legitimate outliers or indicative of data entry errors. Similarly, if a validation rule flags certain customer names as invalid, business users can provide insights into potential data entry conventions or cultural naming practices that might be influencing the data.
However, this collaboration can present challenges. Business users might be unable to dedicate the time required for training data specialists or reviewing flagged errors. This can hinder the validation process and delay the resolution of data quality issues.
Furthermore, addressing the root causes of data validity errors often requires changes to business processes or improved training for data entry personnel. This necessitates buy-in and support not only from business users but also from top management. For example, if invalid data is consistently entered due to an unclear or outdated business process, the process itself needs to be revised and aligned with IT practices.
Effective communication and collaboration between data specialists and business users are essential for successful data validation. Building strong relationships, fostering open communication channels, and securing support from top management are crucial for ensuring data validity and maintaining high-quality data throughout your organization.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
How to improve data validity
A data observability platform monitors data sources and identifies data quality incidents related to data validity. The platform notifies the respective data teams or data asset owners about the identified issues. It becomes the responsibility of the data team to fix the invalid data. Once the root cause of the problem is identified, the data teams can make corrections, reload the data, and revalidate its validity.
You can use a data observability platform to prevent data validity issues from spreading to downstream systems. For example, a data observability platform like DQOps can expose a REST API to execute data quality checks on the data source or request the current data validity status. This allows the data pipeline to verify the source data for any issues before processing it further.
By measuring data validity with data quality Key Performance Indicator (KPI) scores, the data teams can prioritize the affected dataset and focus on the most valuable data assets first. It is possible to remediate all sources of data validity issues within a few weeks and achieve almost 100% data completeness KPI score. DQOps platforms have dedicated built-in dashboards for monitoring dataset KPIs and specialized dashboards for data validity checks, like the “Current validity issues on columns ” dashboard shown below.
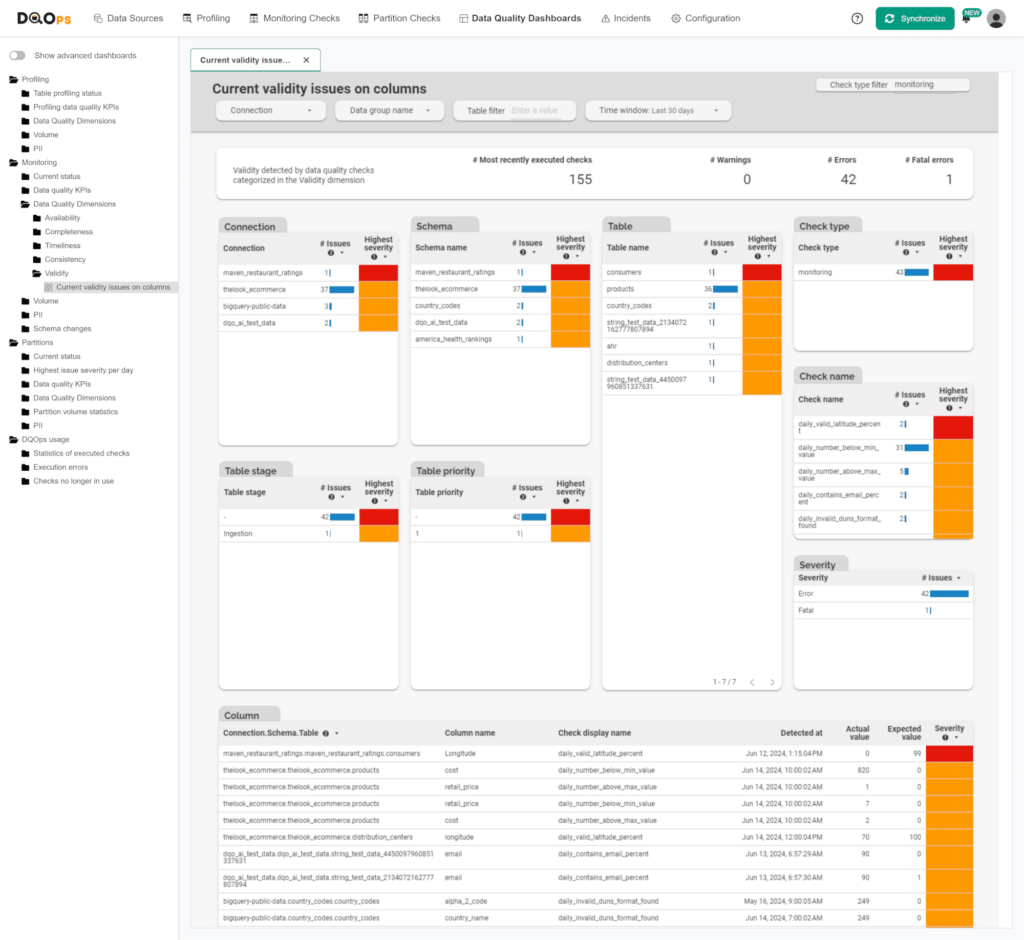
If you are interested in our experience of applying data observability across different data domains, you can download our free eBook, “A step-by-step guide to improve data quality.” This eBook is a reference for our business process, outlining how we clean data sources.
How to start
The Data Observability market is competitive, with many vendors offering closed-source SaaS platforms. You can start a trial period on these platforms and expose access to your data sources from the cloud to run data monitoring on your systems.
Another option is to try DQOps, our data quality platform, which provides a faster solution without exposing your data to a SaaS vendor. You can set up DQOps locally or in your on-premise environment to understand how data observability can help prevent data validity issues.
Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You can also download our free eBook “A Step-by-Step Guide to Improve Data Quality,” which describes our proven process for assessing data quality, monitoring it, and reacting to data quality issues.




