
Data availability refers to the accessibility, usability, and integrity of data for various purposes. It encompasses the practices, technologies, and policies that ensure data is readily available when needed and can be easily understood, interpreted, and utilized. Data availability is a fundamental aspect of data management and analytics, as it directly impacts the reliability, accuracy, and effectiveness of data-driven insights and decision-making processes.
However, availability can be affected by various technical issues, including problems with infrastructure, access rights, and other technical problems that cause downtime. These issues can result in data being temporarily or permanently unavailable, hindering the ability of users to access and utilize data effectively.
Table of Contents
You can monitor data availability for free
Before you keep reading, DQOps Data Quality Operations Center is a data observability platform that measures and improves data availability. Please refer to the DQOps documentation to learn how to get started.
Types of availability problems
The data may be unavailable temporarily or permanently. The temporarily unavailable data is still present, but some other obstacles prevent users from accessing the data assets. Once the problems are removed, access to the data is restored for users without significant long-term consequences.
Temporary availability issues are caused mainly by data access issues, such as expired credentials, reconfiguration of the authentication and authorization components, or networking issues, such as changes to the firewall rules. Even if the data asset is permanently corrupted due to a severe hardware failure, not all failures are permanent. A lightning strike could fry the disk array and all its hard disks. However, as long as there are other replicas of the data asset, we should still consider it a temporary availability issue that requires a longer time to restore the infrastructure to the original state.
Permanent issues are more severe and will have long-term consequences for the organization. This type of availability issue refers to problems with the master copy of the data that is not covered by an up-to-date backup, and either the whole data asset or a subset of data at the stage valid short before the incident cannot be restored.
The causes of availability issues
Data availability problems often affect data stored in actively used databases, data lakes, and data warehouses. Data availability issues come from the dynamic nature of data refreshes. The data assets, such as dictionary or fact tables, are continuously updated by data pipelines or ETL processes. Unattended data automation triggered at a scheduled time can fail due to outdated credentials, untested code changes, invalid data formats, or simply reaching out of disk space to process temporary data.
Many data assets are also updated manually because the cost of automation does not justify the investment in setting up a fully automated process. A human error could make these data assets unavailable during an update. The simplest type of such mistake is creating a new version of the data asset under a different name. The next problem is skipping required post processing steps, such as granting access rights to the data asset after recreating it.
Other types of data availability issues can also affect big datasets. Due to the data volume, tables stored in data lakes or on Hadoop clusters will be distributed not only across multiple disks but also across multiple machines that are storing selected partitions or data blocks. In that case, the table’s metadata is available, and we can read the definition of the data asset. However, running a query on a corrupted table will fail as soon as the database engine tries to read a corrupted data partition.
How to measure availability level with KPIs
Data availability can be measured as the percentage of time that a data asset is accessible and usable. It is typically expressed as a number of nines, where each nine represents 99.9% availability. For example, if a data asset has an availability of five nines, it means that it is accessible and usable 99.999% of the time. This level is considered to be very high and is often required for critical business applications. Organizations need to implement robust data management practices to achieve five-nines availability, including regular backups, disaster recovery plans, and high availability infrastructure.
How to detect availability and connectivity issues
Users who face issues when accessing data and report the problem are the ultimate source of detecting these problems, but an organization cannot depend on them because the goal of ensuring high availability is to prevent users from noticing any data quality issues before they are automatically detected.
Organizations must apply a proactive approach to data accessibility and reliability monitoring. It requires detecting and handling problems with data platforms that prevent users from accessing the platform before users can see them. Data platforms built according to a modern data architecture use data observability platforms that are responsible for continuous monitoring of data assets, detecting data unavailability and data quality issues from the business perspective.
Running an SQL query that reads all records is the most reliable way to measure the availability of data assets such as tables. This method will also detect corrupted data partitions but at the cost of adding a substantial load on the database server, which will impact the response time for other users.
An alternative option is to measure a data availability KPI across all data assets and run table scan queries on the tables less frequently. Availability is one of the data quality dimensions, which is a category of data quality issues that affect data accessibility and reliability. The data availability KPI is a percentage measure of accessibility checks passed for all monitored data assets. If 100 data assets are monitored ten times a day, and only one table is unavailable during one check, the data availability KPI would be 99.9%. Data observability platforms, such as DQOps, are designed to balance the additional load on databases and the agility to detect availability issues quickly.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
How to react to data reliability issues
Data availability incidents detected by automated continuous monitoring of data assets should be managed by a data incident resolution process that begins by detecting issues related to connectivity to the data platform by a data observability platform. The incident should be assigned to a data operations team for assessment. The data operations team should confirm the problem and assign it to the correct engineering team that can resolve it.
Because availability issues affect all users, they are usually a higher priority than other issues. The organization should have a process to measure the time spent resolving data availability issues from the time the issue was detected until the problem was resolved and the resolution was confirmed.
How to improve data availability
Improving the platform’s availability requires a combination of planning, infrastructure, and operational processes. Here are some key strategies for achieving long-term data availability:
- Implement a comprehensive strategy: Establish clear goals for ensuring uninterrupted operations, identify critical data assets, and develop a roadmap for achieving and maintaining high levels of availability.
- Invest in robust infrastructure: Utilize reliable hardware, redundant storage systems, and high-availability architectures to minimize the risk of data loss or downtime.
- Implement effective data backup and recovery solutions: Regularly back up data to secure locations, test recovery procedures, and ensure that backups can be restored quickly and reliably.
- Monitor availability metrics: Continuously monitor key metrics such as uptime, latency, and error rates to identify and resolve availability issues promptly.
- Implement automated incident response processes: Establish clear procedures for responding to data availability incidents, including notification, escalation, and resolution.
- Educate and train personnel: Ensure that IT staff, data engineers, and other stakeholders are well-trained in data operations best practices, including data protection, backup, and recovery procedures.
- Regularly review and update operations plans: Regularly assess historical availability metrics, identify areas for improvement, and update plans accordingly.
Once the processes are in place, the organizations should start monitoring raised issues and learning from past incidents. One option is to identify the data assets often affected by availability issues. These assets may not be managed correctly, or the data pipelines are not reliable enough, leaving the data asset in a corrupted state.
DQOps provides a set of data quality and data availability dashboards that show the data assets affected by availability problems. The following dashboard shows a list of tables that were affected by problems and a daily calendar to identify trends.
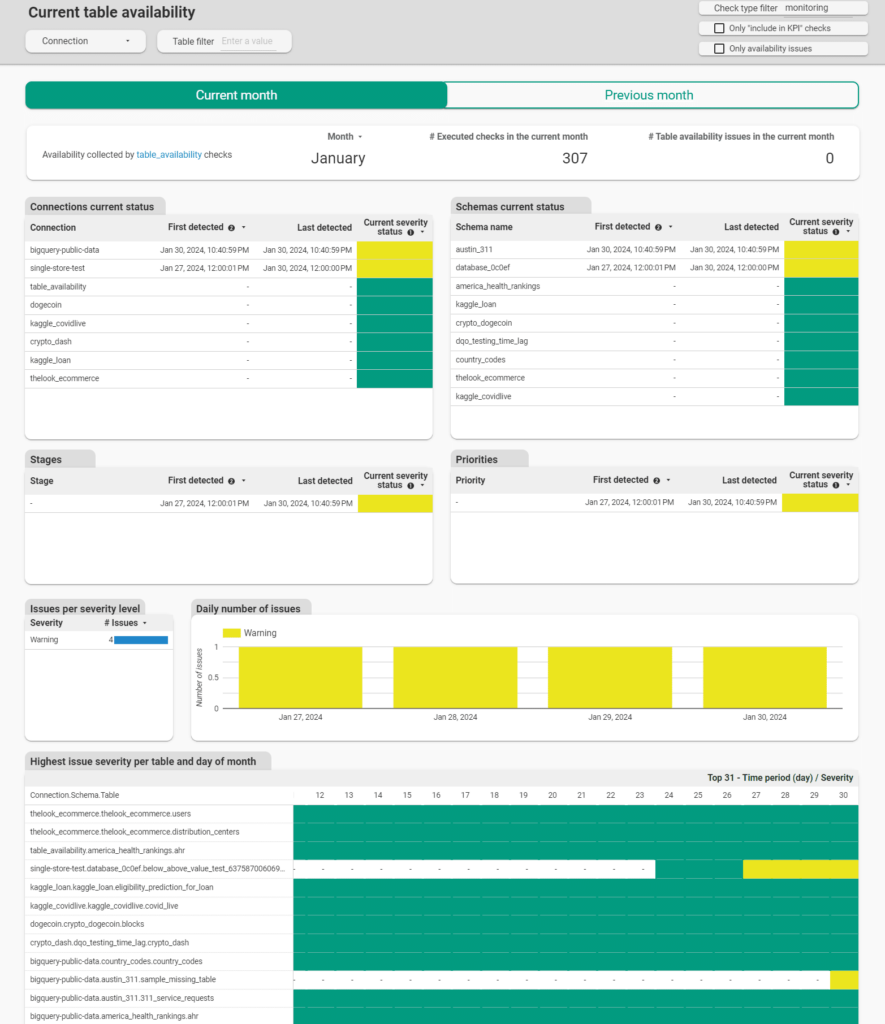
How to begin monitoring data platforms
The Data Observability market is occupied by many vendors, and most solutions are closed-source SaaS platforms. You can start a trial period on these platforms and expose access to your data sources from the cloud to run data monitoring on your systems.
Another option is faster and avoids exposing your data to a SaaS vendor. You can try DQOps, our source-available data quality platform. You can set up DQOps locally or in your on-premises environment to learn how data observability can help ensure a high reliability of data platforms.
Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You can also download or free eBook “A step-by-step guide to improve data quality” to learn the best practices of improving data quality.




