
A data asset is a collection of data that has value to an organization. This data can be structured, semi-structured, or unstructured.
Structured data is typically stored in relational databases, in tables with rows and columns. Examples include customer information, financial transactions, and inventory records.
Unstructured data is not organized in a predefined manner and includes formats like text documents, images, audio files, and video files. Think of things like emails, presentations, and social media posts. Even those Excel files that everyone uses and no one can ever find are considered data assets!
Semi-structured data has some internal organization but doesn’t adhere to the rigid structure of relational databases. Examples include JSON and XML files.
Proper data asset management enables organizations to track the type, format, location, owner, and purpose of each valuable data asset. Data-driven organizations achieve their competitive advantage by knowing which data assets are valuable and how to use data from these data assets to drive decisions.
Table of Contents
Types of data assets
Data assets come in various shapes and sizes. Here are a few common types you might encounter:
Structured Data: This is the most familiar type – think of neatly organized tables in a database or spreadsheet. It’s easy to analyze because it has a clear structure with rows and columns. Examples include customer records, financial transactions, and inventory data.
Unstructured Data: This is the wild west of data. It’s messy and doesn’t fit into a predefined format. Think emails, social media posts, images, videos, and even audio recordings. While it’s harder to analyze, it often contains valuable insights.
Semi-Structured Data: This is a hybrid. It has some structure but is not as rigid as structured data. Examples include JSON and XML files, which are often used to exchange data between systems.
The source of data assets
Data assets can be categorized as primary or secondary. Primary data assets contain the original information at the platform where the data record was initially created. Such assets are essential for retaining the authenticity and integrity of the data. On the other hand, secondary data assets are transformed copies of data assets, such as tables in landing zones, data lakes, data warehouses, or extracts generated for a specific use case. Secondary data assets are often used for various purposes, including data analysis, reporting, and machine learning. Some categories of data assets are well-known and commonly used in organizations.
Transactional data captures the details of specific events or interactions, such as sales transactions, website clicks, or call center interactions. It is valuable for understanding customer behavior and business processes.
Master data is the core business data, essential for running operations. It includes things like customer data, product data, and employee data. Accurate master data is crucial for making informed decisions.
Reference data is used to categorize or standardize other data. For example, a list of country codes or product categories would be considered reference data.
Big data refers to massive volumes of data that are too large or complex for traditional processing methods. Big data can be structured, unstructured, or semi-structured. Think of the endless stream of social media posts or the vast amounts of sensor data from IoT devices.
Assessing data assets
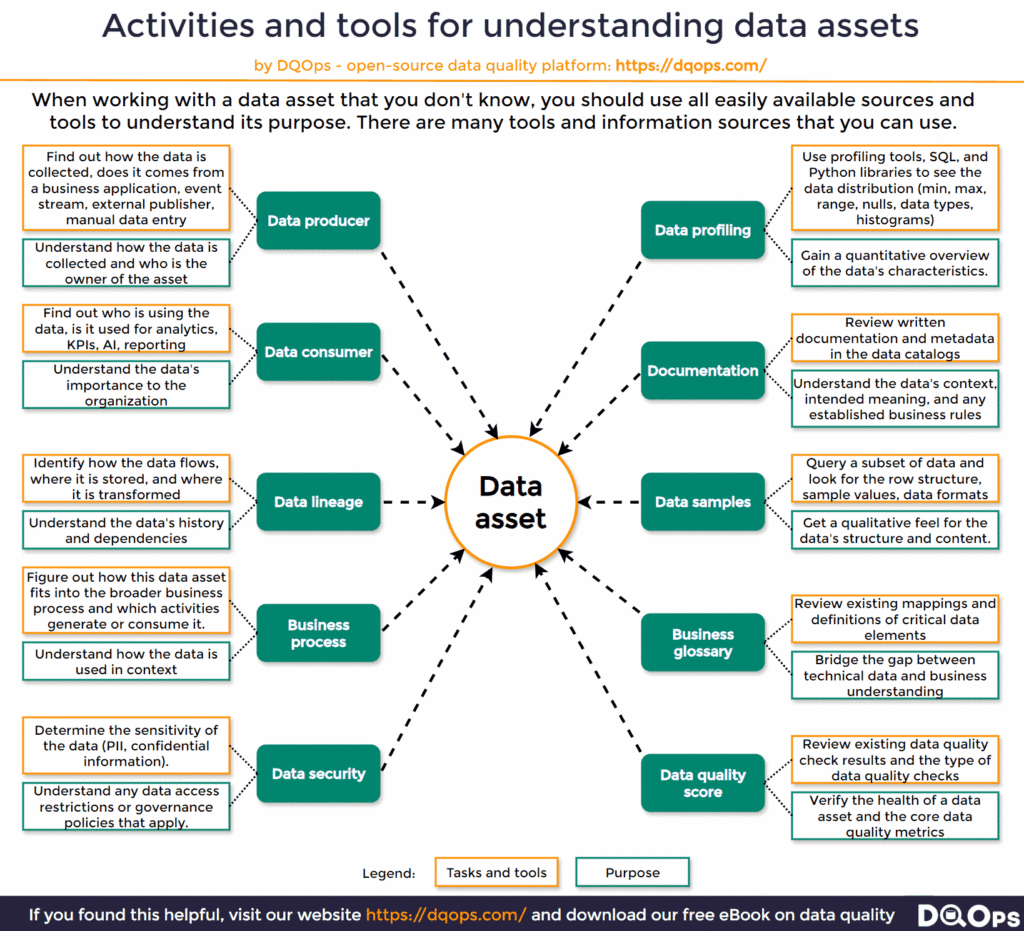
When we encounter a data asset, we should find out all available information about it that can help us decide whether to use it. The data asset could be a table that stores potentially very valuable information required for our use case. The data asset management process is divided into two areas. We need to understand the business purpose of the data asset and the physical structure of the data.
The business purpose of the data is also related to the origins and usage of the data asset. We must understand where the data comes from, who is using it, and how it fits into the broader business context. By identifying the data producer, consumer, and lineage, we can gain a comprehensive view of the data’s journey, from creation to application. This knowledge is essential for assessing the data’s reliability, relevance, and potential impact on decision-making. Additionally, understanding how the data interacts with the business process sheds light on its significance within the organization, helping us prioritize data management efforts.
The next step is to understand the physical structure of the data, including its schema, data distribution, data format, typical values, and the relationship between values. We can use existing sources of information, such as an enterprise data catalog and statistics obtained by data profiling tools, and review the current data quality status of the data asset that is monitored by a data quality platform.
The tasks, tools, and the purpose of each step are described in the following diagram.
Centralizing data asset knowledge in the data catalog
Storing the documentation of a data asset within a data catalog is akin to creating a comprehensive library for your data. It’s a centralized repository where you can house everything from data dictionaries and ERDs to business glossaries and technical specifications. Doing so eliminates the scattered nature of information, making it easily accessible to all relevant stakeholders. The data catalog becomes the single source of truth for understanding your data assets, fostering collaboration, and ensuring consistency in interpretation and usage.
Moreover, a data catalog plays a pivotal role in knowledge sharing within an organization. It enables data consumers, whether they are analysts, data scientists, or business users, to quickly discover and understand the data assets available to them. The catalog serves as a bridge between technical and business domains, empowering users to make informed decisions based on reliable and well-documented data. By facilitating seamless access to information, the data catalog promotes data democratization and empowers individuals to unlock the full potential of data assets.
Mapping data assets to a business glossary
A business glossary complements the data catalog by providing a common language for understanding data. It’s a dictionary of business terms and their definitions, ensuring that everyone in the organization speaks the same language when discussing data. By clearly defining critical data elements, the business glossary eliminates ambiguity and confusion, fostering a shared understanding of the data’s meaning and context. This shared understanding is crucial for accurate analysis, effective communication, and successful decision-making. The business glossary, therefore, acts as a Rosetta Stone for data, bridging the gap between technical jargon and business terminology.
The importance of data quality
Leveraging a data quality platform for assessing data assets empowers organizations to establish a robust foundation for data-driven decision-making. By offering self-service profiling capabilities, these platforms democratize data exploration, allowing users to easily capture statistics and sample values, fostering a deeper understanding of their data assets. The collaborative nature of these platforms further amplifies this understanding, as users within the same business area can readily access and build upon the insights generated by their peers, saving valuable time and effort.
However, the true value of a data quality platform extends beyond initial assessment. It lies in its ability to continuously monitor data assets for potential quality issues and anomalies that might not be apparent from a superficial glance. By conducting comprehensive checks on the entire dataset, the platform can detect inconsistencies, errors, and deviations from expected patterns, ensuring the data remains reliable and fit for purpose. Moreover, with ongoing monitoring and automated alerts, the platform safeguards against data quality deterioration over time, enabling timely interventions and preventing costly mistakes. This proactive approach ensures that your data assets consistently meet your business needs, whether it’s powering critical decision-making or fueling machine learning models.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
What is the DQOps Data Quality Operations Center
DQOps is a data quality platform designed to empower users to profile data assets and validate data quality using data quality checks. DQOps provides extensive support for profiling data and validating hypotheses about the quality of data assets.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can be used to analyze data assets in a centralized or decentralized environment. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time.




