
A data incident is an unplanned disruption that affects data in terms of quality, security, availability, or integrity, making it unusable. In the realm of data management, a data incident is an unforeseen event that disrupts the normal operation of your data platform. It’s like a sudden storm hitting your data, potentially rendering it unusable or even leading to serious consequences like data leaks and compliance violations.
These incidents can stem from various sources, including:
- Server crashes: Hardware or software failures that cause your data platform to become unavailable.
- Data breaches: Unauthorized access to sensitive data, which can lead to financial losses, reputational damage, and legal repercussions.
- Data corruption: Errors or inconsistencies in your data that make it inaccurate or unusable.
- Data processing errors: Mistakes made during data processing that can lead to incorrect or incomplete data.
Data incidents can have a significant impact on your organization, causing:
- Data unavailability: Users may be unable to access the data they need to do their jobs.
- Data inaccuracy: Decisions may be made based on incorrect or incomplete data.
- Compliance violations: Your organization may be in violation of data privacy regulations.
- Reputational damage: A data incident can damage your organization’s reputation and lead to a loss of customer trust.
Therefore, it’s crucial to have a robust data incident management plan in place to identify, respond to, and resolve data incidents quickly and effectively.
What is a Hardware Incident
A hardware incident disrupts the physical components of a data infrastructure. This can include server crashes, hard drive failures, or network equipment problems. Such incidents lead to data inaccessibility, potential data loss, and communication disruptions between systems.
The consequences of hardware incidents can be severe, including unrecoverable data loss, system downtime, and financial losses for businesses. If systems lack adequate backups, data loss from hardware failures can be devastating, especially for data-reliant businesses. Downtime prevents access to critical data and applications, impacting productivity. The combined effects of data loss and downtime can lead to substantial financial losses.
To mitigate risks, businesses should implement robust backup and disaster recovery strategies. Critical systems should utilize clustering, enabling a secondary server to seamlessly take over in case of primary server failure, ensuring high availability and minimizing the impact of hardware incidents on business operations.
What is an Infrastructure Incident
An infrastructure incident arises from issues within the software or configuration of your data platform, rather than physical hardware failures. These incidents can stem from a variety of causes, such as misconfigurations of systems, incompatible versions of software components, or latent software bugs that surface when the data pipeline encounters unexpected data formats or volumes.
Unlike hardware incidents, infrastructure incidents typically do not cause servers to crash or become unresponsive. Instead, they manifest as errors or exceptions recorded in log files or dedicated error tables within the data processing system. These errors can disrupt data processing, leading to delays, incomplete or inaccurate results, or even a complete halt of the data pipeline.
Identifying and resolving infrastructure incidents often requires a deep understanding of the system’s architecture, configurations, and data flow. Careful analysis of log files and error tables is crucial to pinpoint the root cause of the problem and implement appropriate fixes. While infrastructure incidents might not be as immediately visible as hardware failures, their impact on data integrity and availability can be equally significant, underscoring the importance of proactive monitoring and robust incident response procedures.
What is a Data Quality Incident
A data quality incident refers to a problem within the data itself, rather than an issue with the infrastructure or hardware. This can include a variety of problems, such as missing records, missing values within records, duplicate records, or values that are in the wrong format – such as incorrect email addresses or invoice numbers. These errors can compromise the accuracy, completeness, and reliability of your data, leading to flawed analysis, incorrect reporting, and potentially poor decision-making.
If data is not actively monitored and tested with data quality checks, these issues often remain undetected until they are discovered by end-users who notice inconsistencies or inaccuracies in their reports or applications. This can lead to frustration, delays, and a loss of trust in the data.
To proactively prevent and address data quality incidents, organizations increasingly rely on data observability tools. These tools continuously monitor data platforms, running a variety of data quality checks designed to identify common types of issues. By catching these problems early, organizations can take corrective action before they impact downstream processes or users, ensuring the integrity and reliability of their data.
What is a Data Security Incident
A data security incident encompasses any event that threatens the confidentiality, integrity, or availability of your data. This includes unauthorized access attempts, where individuals or systems try to gain access to data they are not permitted to view or modify. It also covers a wide range of malicious activities, such as malware infections that attempt to compromise system integrity, denial-of-service attacks aimed at disrupting service availability, or brute-force login attempts by bots seeking to exploit vulnerabilities.
Detecting and responding to data security incidents requires a multi-layered approach. This involves analyzing patterns in log files to identify suspicious activity, implementing robust access controls and authentication mechanisms, and deploying additional security measures such as firewalls and intrusion detection systems. By actively monitoring for potential threats and responding swiftly to any breaches, organizations can protect their sensitive data and maintain the trust of their customers and stakeholders.
What is a Data Breach Incident
A data breach incident represents a severe security lapse where sensitive or personal information is accessed, stolen, or exposed without authorization. This could involve customer data, employee records, financial information, or any other confidential information that an organization stores. Such incidents can have devastating consequences, including financial losses, reputational damage, legal penalties, and a loss of customer trust.
The data organizations store about their customers is a prime target for hackers, who seek to exploit this information for financial gain or other malicious purposes. They may demand ransom in exchange for not exposing the stolen data, or sell it on the dark web to other criminals. In the European Union, all data breaches must be reported to the regulatory institutions responsible for data privacy, as mandated by the GDPR law. Failure to comply can result in hefty fines and further damage to an organization’s reputation.
Detecting and preventing data breaches requires a proactive approach to data security. This includes implementing strong access controls, encrypting sensitive data, and regularly monitoring for suspicious activity. Data Loss Prevention (DLP) platforms play a crucial role in this process, monitoring all outbound data transfers to identify and block any potential leaks of sensitive or personal information. Data breach incidents, while closely related to data security incidents, represent a successful attempt to access and retrieve secured data at a large volume, underscoring the importance of robust data security measures.
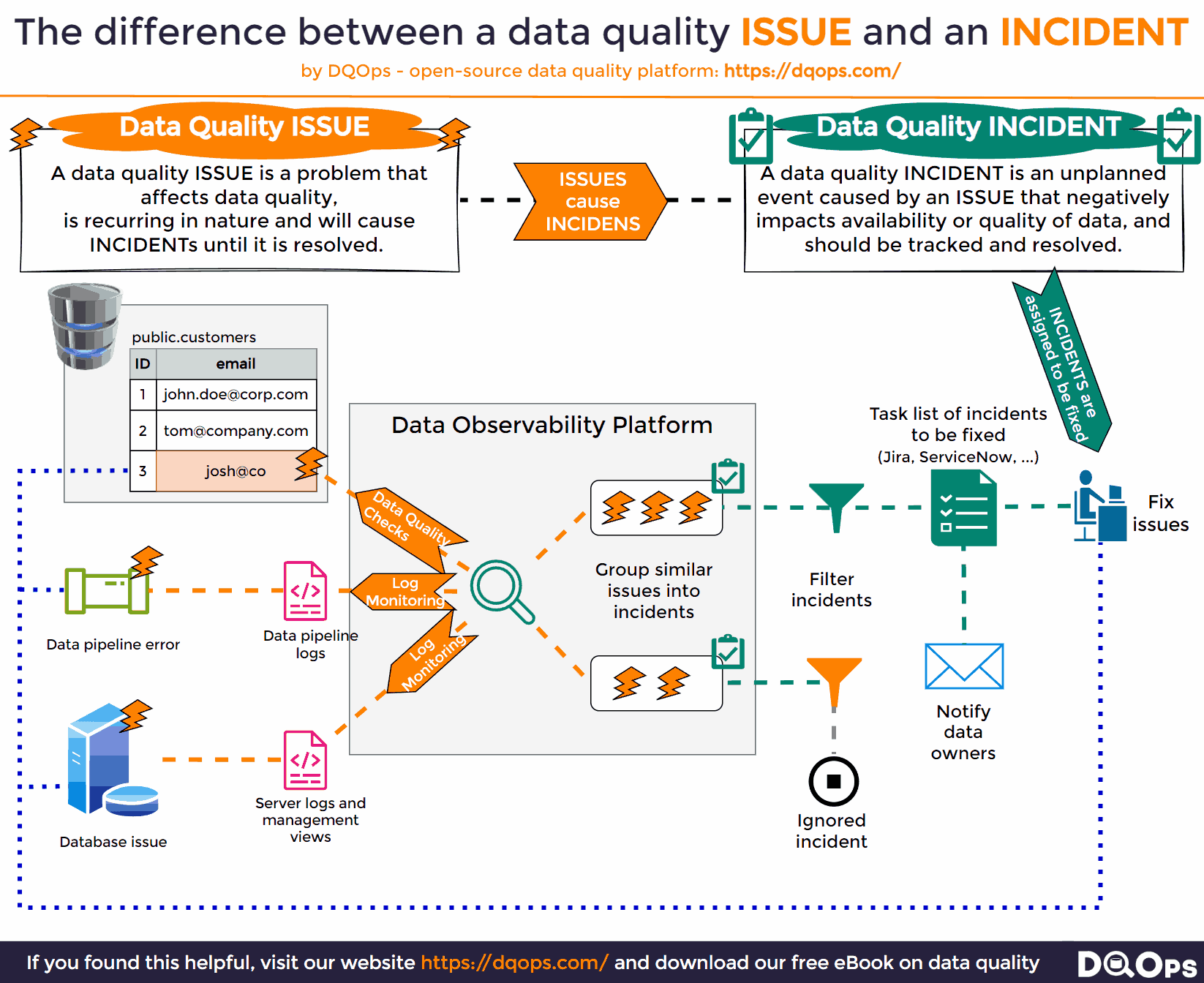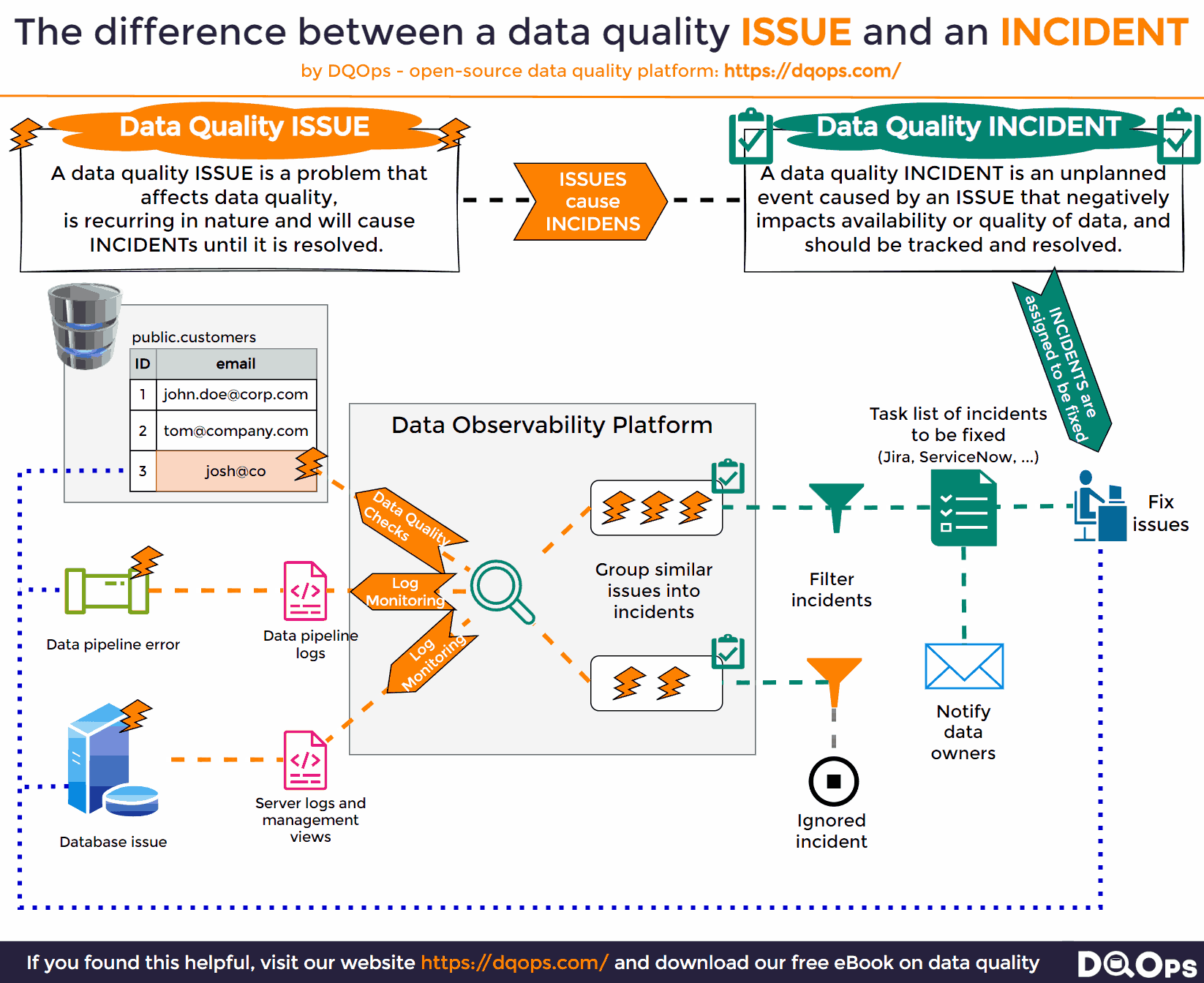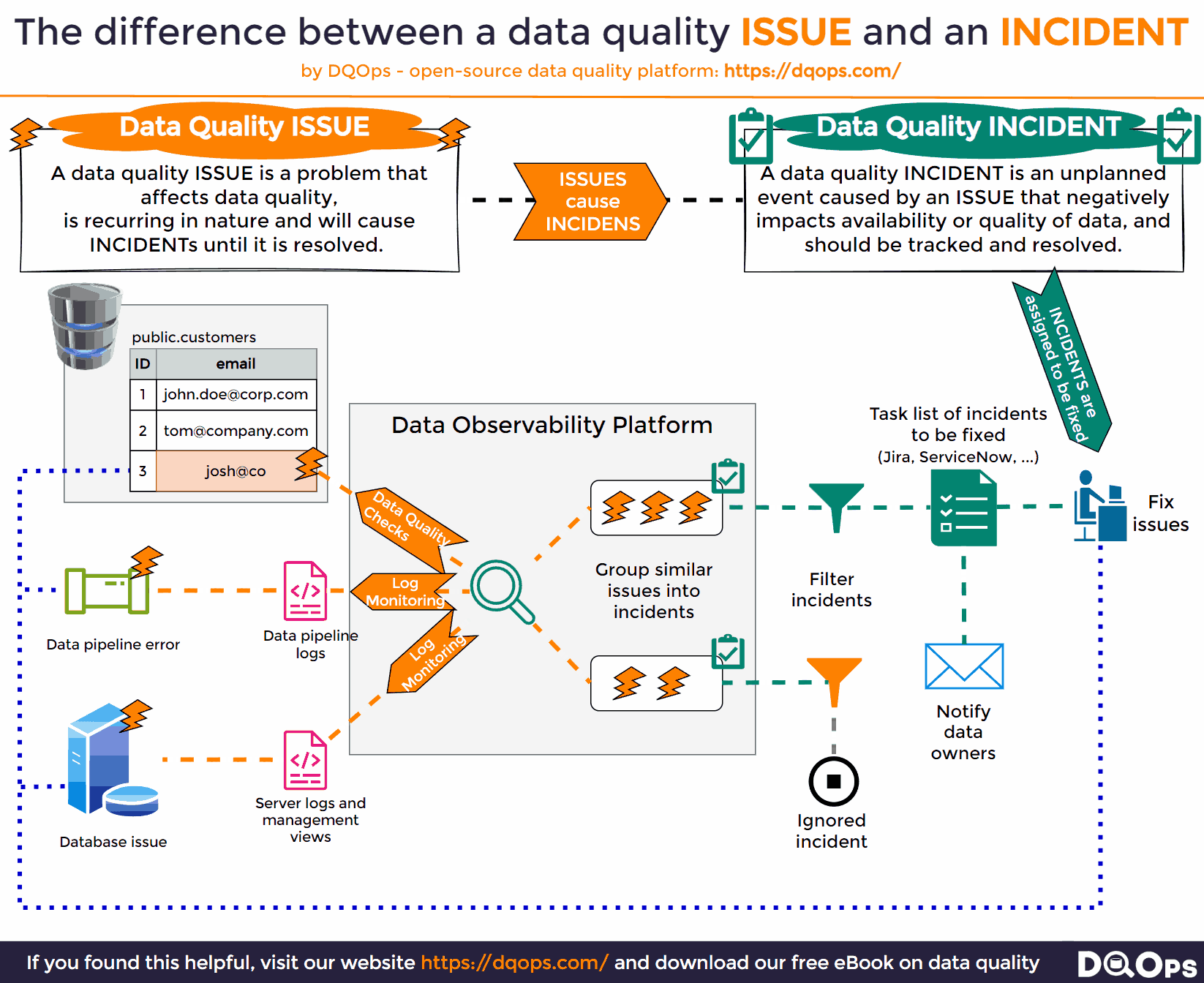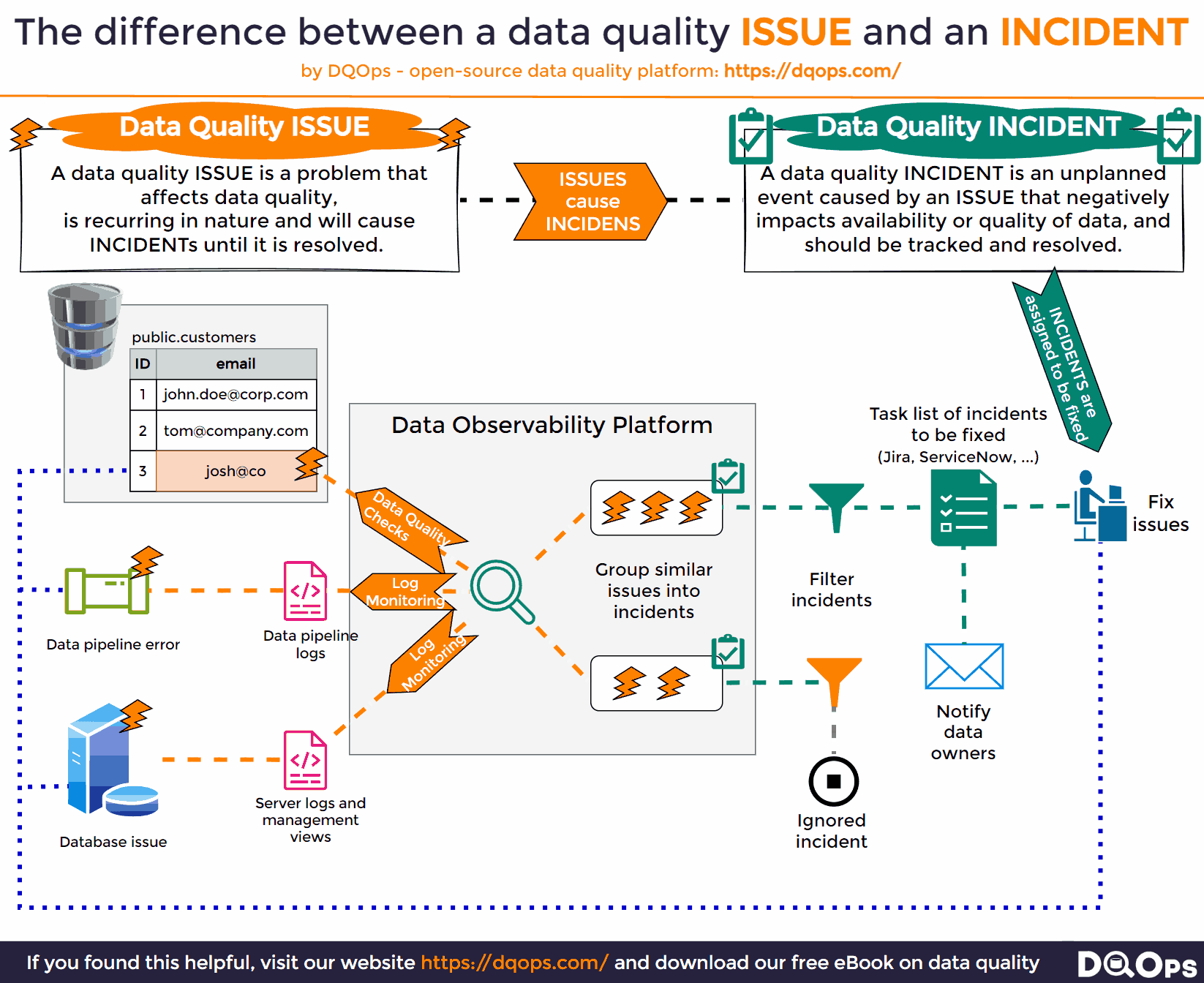
The Difference Between Issues and Incidents
In the context of data management, it’s crucial to distinguish between issues and incidents. An issue is the first detected instance of a problem, often flagged by data monitoring tools like data observability platforms. These tools continuously scan your data environment, reporting any anomalies or inconsistencies they encounter. However, not all issues warrant immediate attention. Some may be known problems, others might be trivial, and still, others might be duplicates.
The transition from an issue to an incident occurs when the problem is confirmed and deemed significant enough to require action. This is where incident tracking begins. Importantly, most incidents have multiple underlying causes. Therefore, limiting incident tracking to a single source can hinder the efforts of data teams working to resolve the problem.
To effectively manage incidents, it’s crucial to assign a unique identifier to each one and track it from the moment the first confirmed issue is detected. As data monitoring continues, any subsequent issues that match the characteristics of an existing incident should be linked to it, rather than creating new, duplicate incidents. This approach prevents overwhelming data teams with a flood of notifications while ensuring all relevant information is consolidated in one place, facilitating a more efficient and comprehensive resolution.
The Source of Data Issue Information
A data observability platform tasked with monitoring a data platform for new data incidents should employ a multi-pronged approach, continuously surveying all possible sources where potential problems might be reported. This includes:
- Log Files: A treasure trove of information about the system’s activities, log files often contain valuable clues about errors, warnings, or unusual events that could signal a developing issue.
- Management APIs: Many modern systems provide APIs that allow for real-time monitoring of the system’s health and performance. By regularly querying these APIs, a data observability platform can stay informed about any potential problems or failures.
- Query Management Views: Many database platforms offer specialized views that provide insights into query execution, performance bottlenecks, and potential failures. Monitoring these views can help identify issues related to data processing and access.
However, a truly comprehensive data observability platform goes beyond passive monitoring and adopts an active approach to issue detection. This involves:
- Data Quality Checks: Running regular data quality checks to detect all sorts of issues that may not be reported by other systems, such as inconsistencies, invalid data, or missing values. This proactive approach ensures that data quality problems are identified and addressed before they escalate into major incidents.
By combining all these sources, a data observability platform can provide a complete and up-to-date picture of the data landscape, empowering data teams to identify, respond to, and resolve data incidents quickly and effectively. This holistic approach ensures that potential problems are detected early, minimizing their impact and ensuring the integrity and availability of your data.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
Fixing Data Issues
A data observability platform, while adept at monitoring and detecting potential data incidents, must also facilitate their resolution. To achieve this, it needs to apply intelligent filtering to detected issues, ensuring that only new and potentially impactful incidents warrant attention. Once an issue is confirmed as an incident, the platform should automatically generate a task or ticket, assigning it to the relevant team or individual for resolution. This ensures that the incident is not overlooked and is actively being addressed. Furthermore, the platform should proactively notify the appropriate teams, such as data engineering or data security, about the incident, allowing for a swift and coordinated response.
The notified teams should then conduct a thorough assessment of the incident, including identifying the root cause, estimating the impact on other systems, and evaluating the potential consequences for the organization, especially in cases where the incident could have far-reaching implications. This comprehensive approach to fixing data issues ensures that problems are not just detected but also addressed promptly and effectively, minimizing their impact and safeguarding the integrity and availability of your data. By automating task creation and notifications, the platform streamlines the incident response process, allowing teams to focus on resolving the issue rather than getting bogged down in administrative tasks.
The whole process of monitoring data issues, raising a data incident, and assigning it to the data team is shown below.
What is the DQOps Data Quality Operations Center
DQOps is a data observability platform designed to monitor data and assess the data quality trust score with data quality KPIs. DQOps provides extensive support for configuring data quality checks, applying configuration by data quality policies, detecting anomalies, and managing the data quality incident workflow.
DQOps is an extensive data observability platform that can detect various types of data incidents. DQOps monitors data sources by running data quality checks, which validate problems with data. Its unique ability to define custom data quality checks makes it possible for DQOps to monitor various sources of issues, such as log tables. By filtering and combining similar issues into data incidents, DQOps can aggregate issues from many sources and inform the data team to handle the problem only once.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can monitor data sources and ensure data quality within a data platform. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time. This is a great resource to learn about data quality.




