
Technical debt is a popular term in software engineering. It’s what turns modern solutions into legacy platforms that are hard to maintain and very sensitive to changes. Modern data engineering relies heavily on open-source tools and Big Data platforms, often involving custom solutions written in Python. This blurs the line between software engineering and data engineering.
Many software development best practices, which were difficult to apply to older ETL platforms, are now easily applied to modern data pipelines. We’re building more custom data transformations in code to handle growing data volumes. We’re also automating more tasks to manage the increasing number of datasets. Just like in regular applications, the code for data pipelines can accumulate technical debt over time.
What is Technical Debt
Technical debt is a general term for all the code that was written quickly to meet a deadline, without much thought about the long-term consequences. Sometimes, building software or data pipelines in a hurry is okay. For example, if you’re building a short-term solution or a prototype, it might make sense to move quickly and meet a deadline, or even get ahead of schedule to add more features later.
However, this approach becomes a problem when a quick-and-dirty solution, meant to be temporary, turns into a critical component or even a whole platform. Especially if that platform is going to be around for years and will handle important business processes.
The name “technical debt” comes from the idea of financial debt. Just like with a bank loan, technical debt must be “paid back” in the future, with “interest.” The “interest” on technical debt is the extra time and effort engineers spend making changes to a system (like a data pipeline or application) because of all the messy code that was written in a hurry. Every change becomes risky and takes much longer.
How Technical Debt is Accumulated in Data Engineering
Modern data architectures often use tools like Apache Airflow to orchestrate data pipelines. These tools use Python code to define data transformations and the order of processing, typically using Directed Acyclic Graphs (DAGs). Since DAGs are defined in code, data engineers sometimes create ad-hoc solutions to handle many similar tables with a single piece of code.
This is where technical debt can creep in. It’s tempting to just add more code to load and transform another table, without reusing existing infrastructure. This creates a patchwork of code that’s hard to maintain.
Data platforms are often more vulnerable to changes than regular business applications. If a business application works fine, there’s little need to change it. But data platforms constantly ingest data from various sources. A change in any source can trigger a cascade of changes in the pipeline, requiring urgent updates to handle new data formats or datasets. This constant change makes data pipelines particularly susceptible to accumulating technical debt.
How Technical Debt Affects Data Pipelines
Data pipelines are the backbone of any data platform. They ingest, transform, and load data into databases, data lakes, or data warehouses. They use various technologies, like ETL (Extract-Transform-Load) or ELT (Extract-Load-Transform). ELT often involves more coding because the pipeline handles data loading itself, rather than relying on an external ETL tool.
When a data platform has a lot of legacy code, making changes across multiple tables and transformations becomes a nightmare. For example, imagine a data source upgrades its server. Now, every pipeline that loads data from that source needs to be updated. If those pipelines use different methods to extract and load data, the effort to fix them multiplies.
Technical debt also rears its ugly head when tables are loaded and transformed using different approaches. Source data formats can change over time. If these changes aren’t consistently applied across all transformations, the pipeline can break and corrupt data.
That’s why it’s crucial to refactor data pipelines to use the same logic. It’s also essential to monitor the entire pipeline for anomalies and issues caused by legacy code. This is called data quality monitoring and often involves using data observability tools.
The following infographic lists the typical problems caused by technical debt in data pipelines.
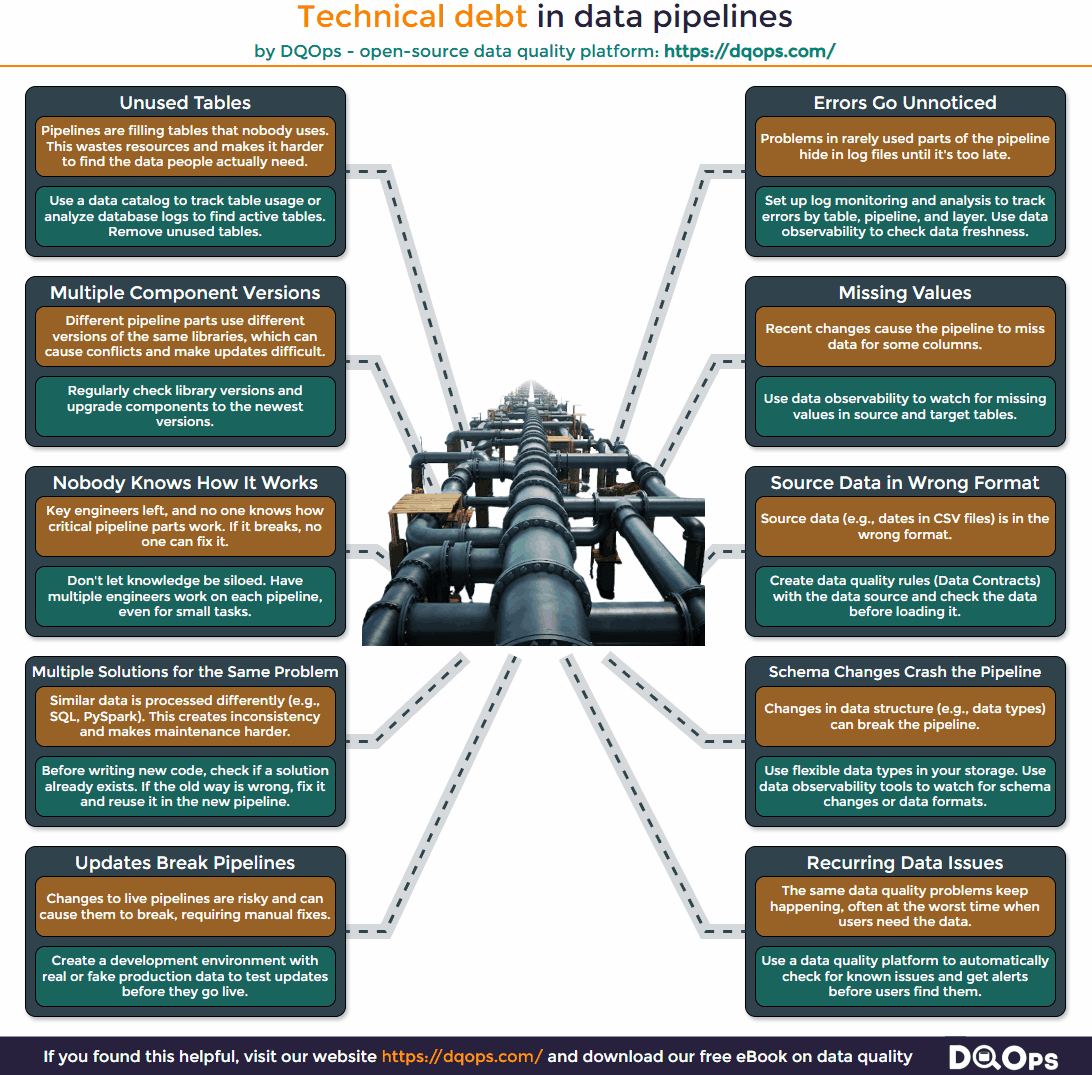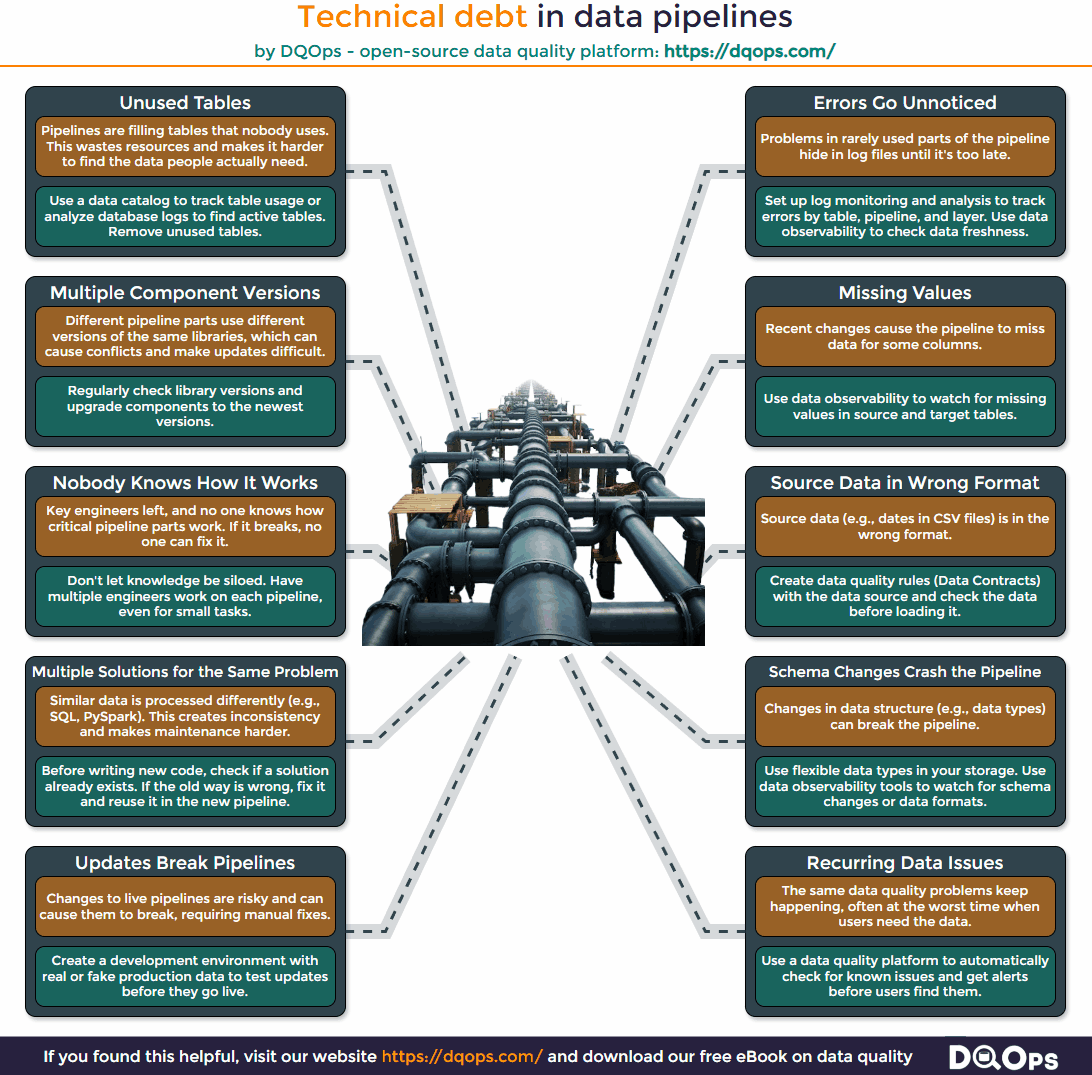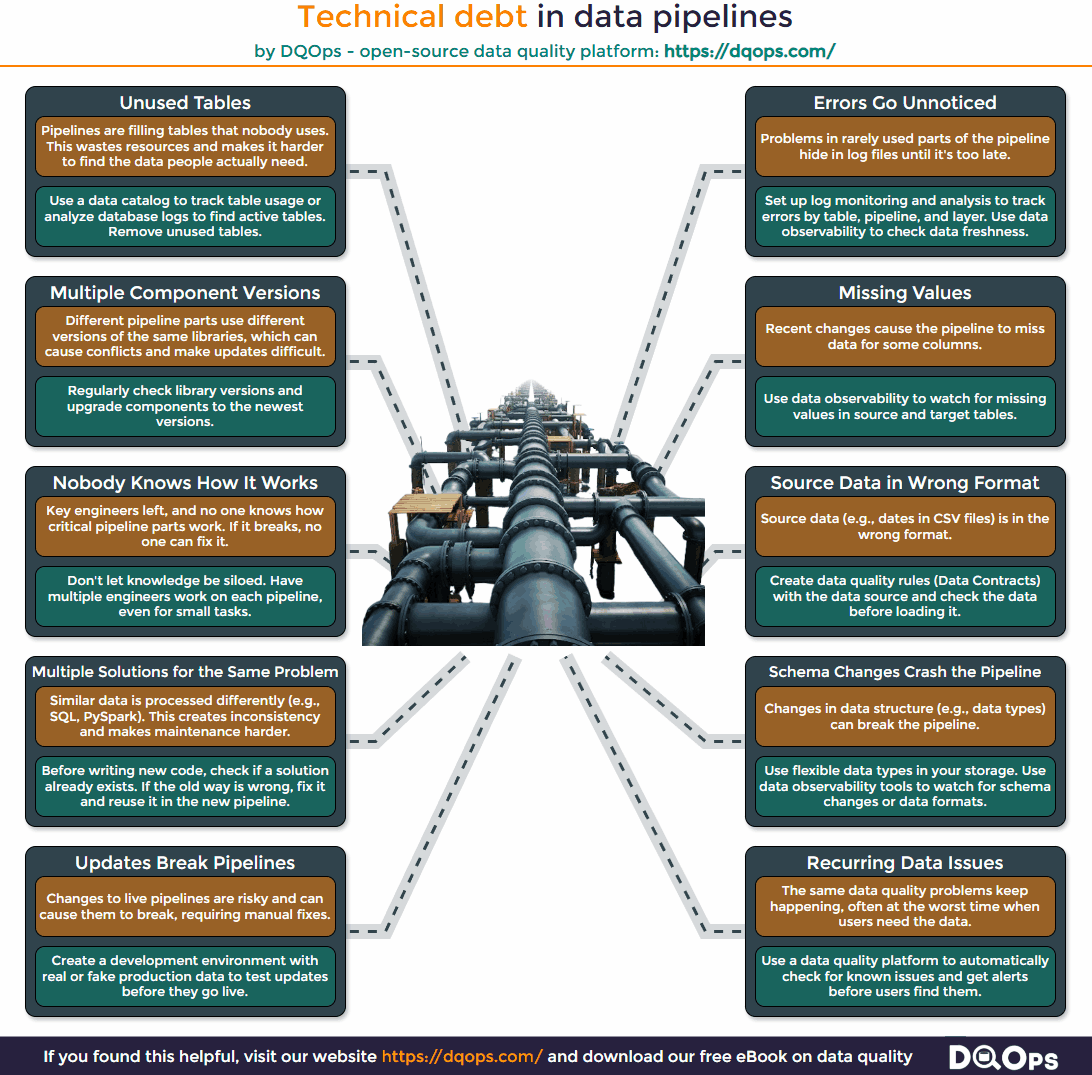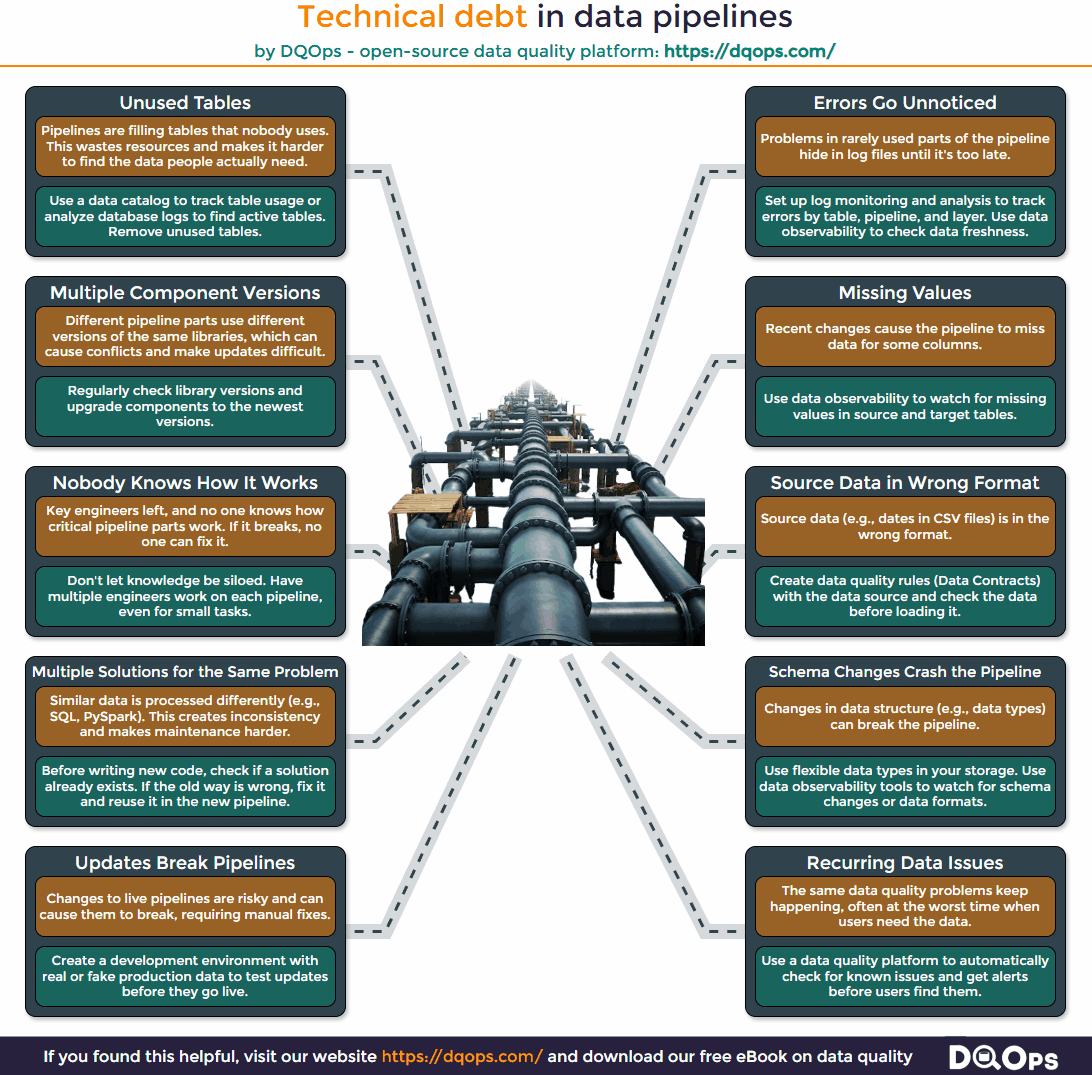
Technical Debt Caused by Improper Maintenance
Technical debt caused by incorrect maintenance and upgrades to data pipelines often manifests as multiple solutions for the same problem scattered throughout the code. This increases the cost of maintenance when updates are needed, whether it’s adding new tables, reflecting schema changes in data transformations, or incorporating new transformations to extract valuable insights from existing data.
Here are some of the most common problems stemming from technical debt in data pipelines, along with suggestions for addressing them:
Multiple Component Versions
Different parts of the pipeline might be using different versions of the same libraries. This can lead to conflicts and cause a headache to update the pipeline. To avoid this, make it a habit to regularly check library versions and keep all components updated to the latest versions. This ensures compatibility and simplifies future upgrades.
Nobody Knows How It Works
Sometimes, key developers leave the team, taking valuable knowledge about critical parts of the pipeline with them. If something breaks, no one knows how to fix it. This is a dangerous situation. To prevent this, avoid knowledge silos. Encourage multiple engineers to work on each pipeline, even for small tasks. This spreads the knowledge and ensures the pipeline’s continued maintainability.
Multiple Solutions for the Same Problem
It’s not uncommon to find similar data being processed in different ways (e.g., using SQL in one place and PySpark in another). This inconsistency makes the pipeline harder to understand and maintain. Before writing new code, always check if a solution already exists. If the old way is flawed, fix it and reuse it in the new pipeline. This promotes consistency and reduces unnecessary complexity.
Updates Break Pipelines
Making changes to a live data pipeline is risky. Updates can easily cause parts of the pipeline to break, requiring manual intervention and data reloads. To mitigate this risk, create a development environment that mirrors the production environment. Use real or anonymized production data to test new updates before they go live. This allows you to catch and fix issues before they impact your users.
Technical Debt Sensitive to Data Drift
Data pipelines require far more changes than typical business applications. They’re responsible for generating output tables that often involve joining multiple tables and applying transformations to make the data easier for analysts and data scientists to use.
When changes are requested, data engineers modify the pipeline code. This is where they face the consequences of code written at different times, with different libraries and approaches to data processing. Updates to this legacy code can easily lead to data corruption in the target tables. These problems are known as data quality issues.
The good news is that we can validate data with data quality checks and use data observability platforms to detect anomalies or unexpected changes.
Here are some common data quality issues caused by technical debt in data pipelines:
Unused Tables
Pipelines sometimes populate tables that no one uses. This wastes resources and makes it harder for people to find the data they need. To address this, use a data catalog to track table usage or analyze database logs to identify active tables. Remove any tables that are no longer needed.
Schema Changes Crash the Pipeline
Changes in the structure of the source data (like data types) can break the pipeline. To make your pipeline more resilient, use flexible data types in your storage layer. Also, use data observability tools to monitor for schema changes and adapt accordingly.
Errors Go Unnoticed
Problems in rarely used parts of the pipeline can hide in log files, going unnoticed until they cause significant issues. Set up log monitoring and analysis to track errors by table, pipeline, and layer. Use data observability tools to keep an eye on data freshness and identify potential problems early on.
Missing Values
Recent changes to the pipeline can cause it to miss data for certain columns. Utilize data observability to monitor for anomalies in data completeness (like an increase in null values) in both source and target tables.
Source Data in the Wrong Format
Sometimes, the source data arrives in the wrong format (e.g., incorrect date formats in CSV files). Establish clear data quality rules (“data contracts”) with the data source, specifying the expected format and data types. Verify the data against these rules before loading it.
Recurring Data Quality Issues
The same data quality problems can keep popping up, often at the worst possible time. Use a data quality platform to automatically check for known issues and get alerts before they impact your users. This proactive approach helps to prevent recurring problems and maintain data integrity.
How to Control Technical Debt with Data Observability
Data observability platforms, such as DQOps, offer a modern way to monitor both data and data pipelines at scale. They can handle the demands of big data environments, monitoring thousands of tables and detecting subtle changes that might signal data quality issues caused by faulty or outdated code in the pipeline.
These platforms work by continuously capturing various metrics from your data and log files. For example, a data observability platform can track the total row count in a table. If a table that normally receives 10,000 rows per day suddenly stops growing, it could indicate a problem in the data pipeline, perhaps due to a schema change in the source table that wasn’t properly addressed in the pipeline code.
Data observability platforms leverage machine learning and advanced time-series analysis to identify anomalies in these metrics. When a potential issue is detected, the platform sends notifications to data engineers or operations teams, allowing them to investigate and address the problem. By using these platforms, data teams can ensure consistent data quality and prevent issues caused by outdated or overlooked legacy code.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
What is the DQOps Data Quality Operations Center
DQOps is a data observability platform designed to monitor data and assess the data quality trust score with data quality KPIs. DQOps provides extensive support for configuring data quality checks, applying configuration by data quality policies, detecting anomalies, and managing the data quality incident workflow.
DQOps is a platform that combines the functionality of a data quality platform to perform the data quality assessment of data assets. It is also a complete data observability platform that can monitor data and measure data quality metrics at table level to measure its health scores with data quality KPIs.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can monitor data sources and ensure data quality within a data platform. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time. This is a great resource to learn about data quality.




