
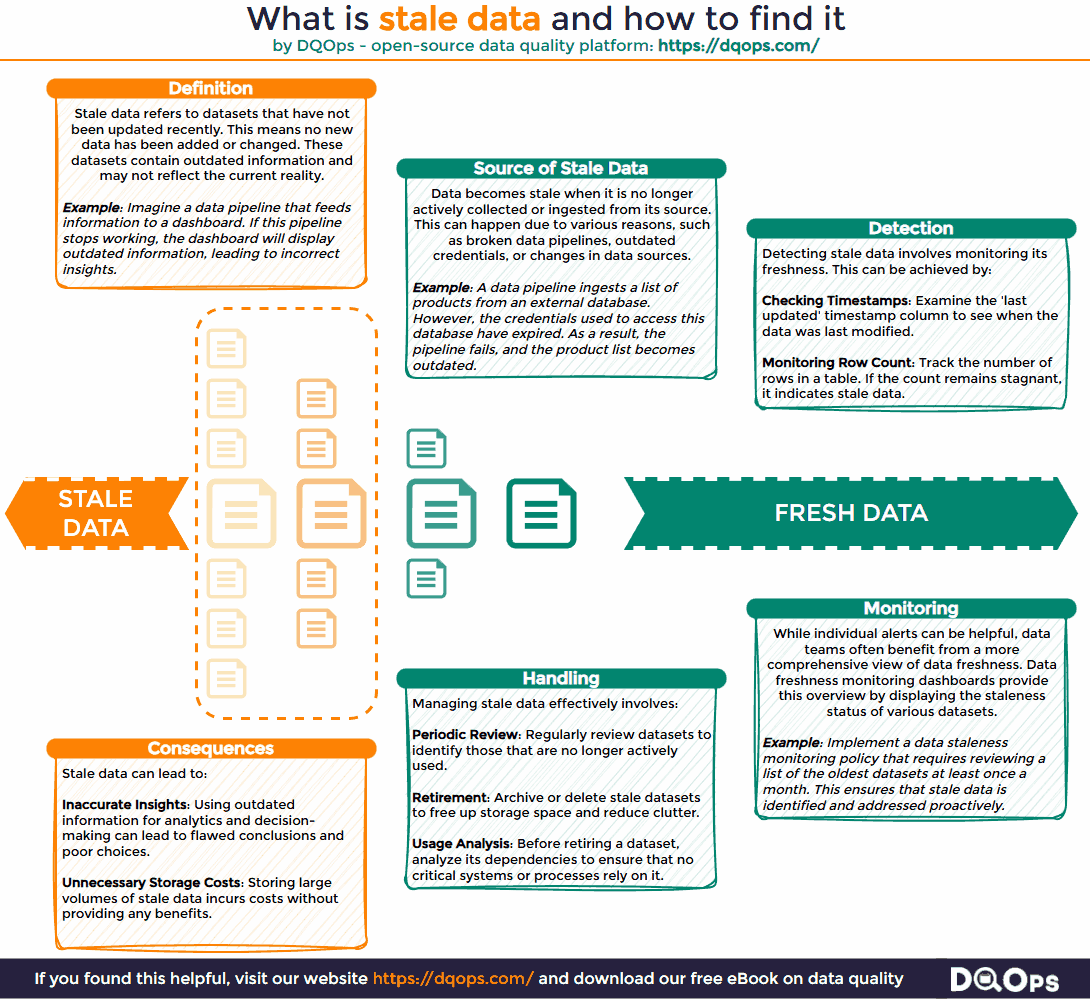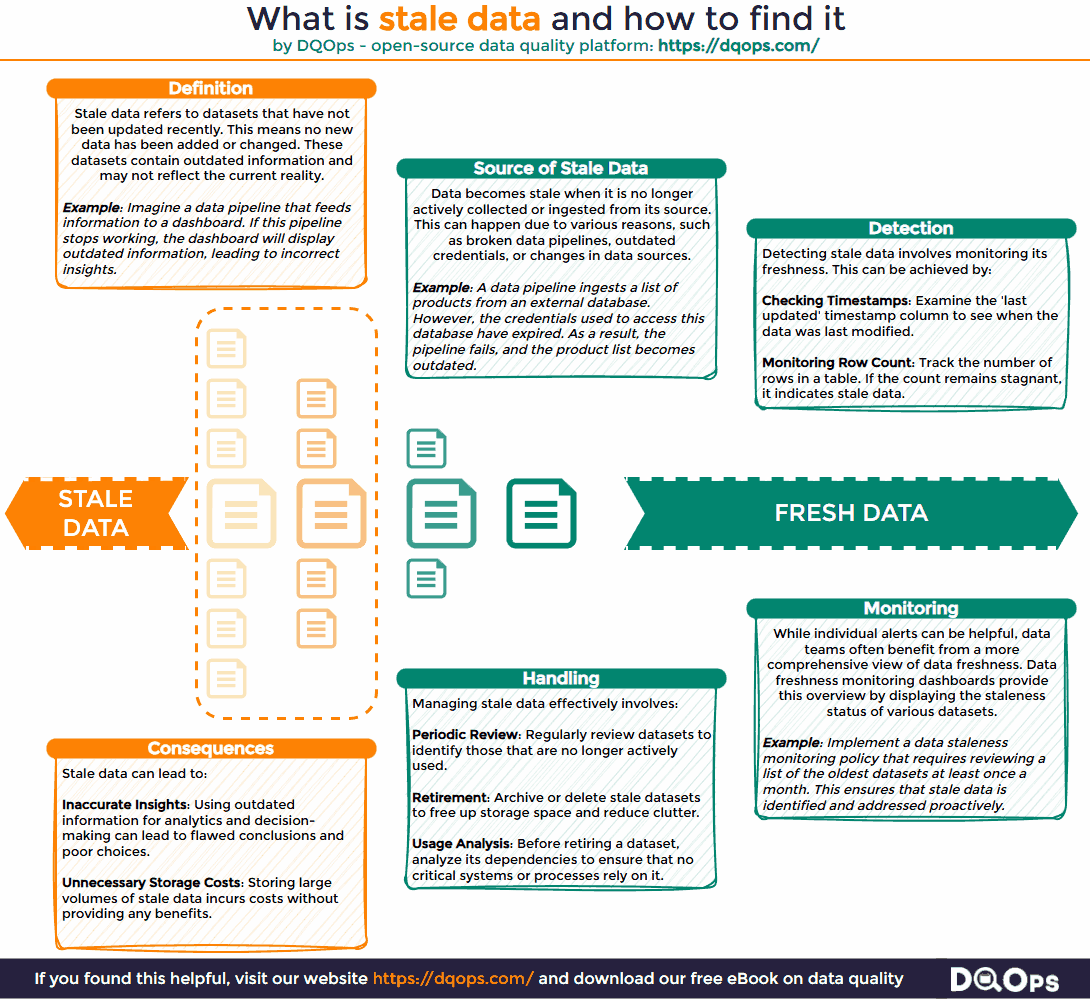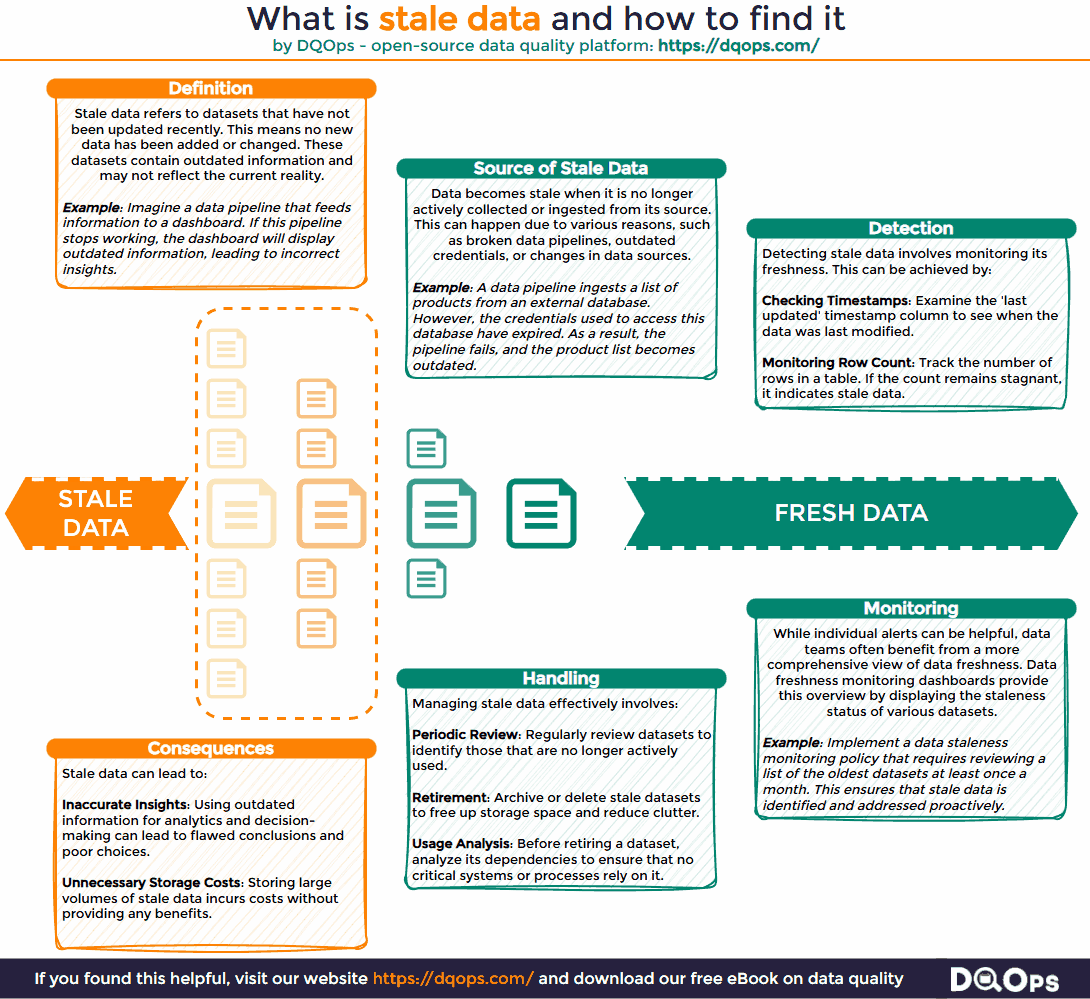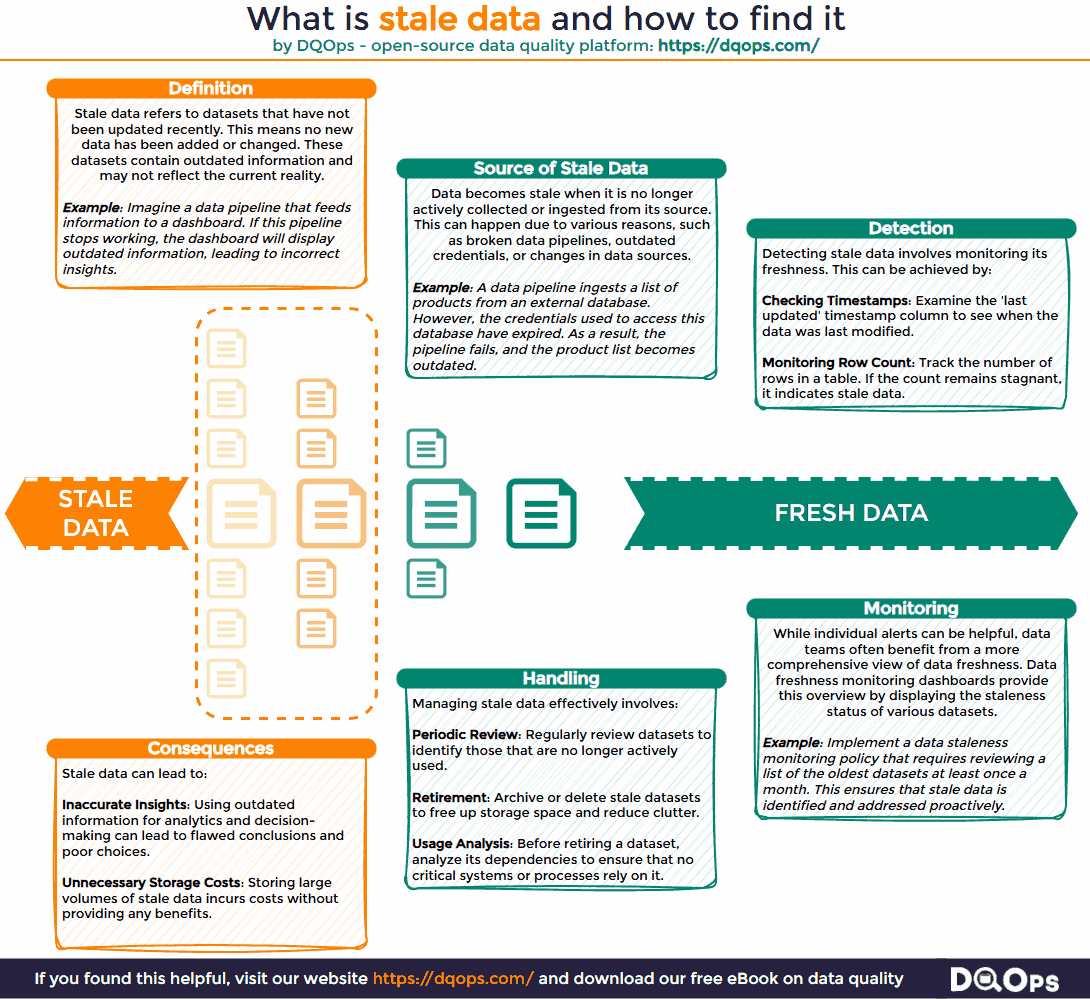
Organizations accumulate vast amounts of data, but not all datasets are actively maintained. When it is not regularly updated, it becomes stale data. This seemingly minor issue can create significant challenges for data teams and hinder an organization’s ability to extract value from its data assets.
Outdated datasets introduce numerous problems in data management. For instance, a data analyst might encounter a table named “all_customers” that appears to contain all the necessary information, including a “status” field. However, upon closer inspection, the analyst discovers that the table has not been updated recently. Consequently, the “status” field and potentially other columns contain outdated information. This can lead to erroneous analysis and reporting, such as dashboards that fail to display the most recent customers or reports that misclassify former customers as active. Such inaccuracies undermine the reliability of data-driven insights and can lead to wasted time and resources.
Moreover, stale data contributes to unnecessary storage costs. Because disk space is a finite resource, identifying and decommissioning unused tables can result in significant cost savings.
Table of Contents
What is Stale Data
Stale data is a state of data that is outdated and no longer maintained because the process of collecting or ingesting new data has stopped. It is a common problem, particularly in complex data environments managed by multiple teams where data pipelines may break or become neglected.
It’s important to distinguish between data that is not updated and data that is truly stale. While the absence of updates might indicate staleness, it’s not always the case. For example, append-only tables that receive new records regularly are not considered stale, even if existing records are not modified. Similarly, small static tables containing reference data, such as lists of countries or business units, remain accurate over long periods and are not classified as stale. Staleness implies that the data no longer reflects the current state of reality and is therefore unreliable for analysis or decision-making.
Examples of Stale Data
Understanding how data becomes stale is easier when we examine specific scenarios that lead to data obsolescence. The following examples illustrate common causes of data staleness in data management:
- Data No Longer Collected: An organization changes a business process or switches to a new tool for data collection. As a result, the old data source is no longer updated and becomes stale. For example, if a company replaces its CRM system, the data in the old CRM will quickly become outdated.
- Data Ingestion Stopped: An ETL (Extract, Transform, Load) pipeline responsible for copying data from source systems fails due to an error, such as outdated credentials or a change in the source system’s schema. Without proper data monitoring and error management, this failure can go unnoticed, leading to stale data in the target system. Users may only realize the information is outdated when discrepancies become apparent in reports.
- Temporary Datasets Used: Data teams often create numerous datasets within data warehouses and data lakes. However, users typically see only the final data, not the underlying data pipelines. This can make it difficult to distinguish between a table that is actively maintained by a data pipeline and a table created as a temporary solution. Consequently, data analysts and data scientists may inadvertently use unsupported datasets that are no longer being updated, leading to inaccurate results and wasted effort.
How to Detect and Monitor Stale Data
Outdated data can be readily detected by monitoring datasets for new or updated records. This allows you to identify datasets that are actively maintained and those that have become stagnant. One common method relies on monitoring data freshness. This involves tracking the age of data by calculating the time elapsed since the last update. This approach is particularly effective for datasets containing a date or timestamp column that indicates when a record was created or modified.
Stale data is the opposite of fresh data, so we need to look for the least “fresh” data to find stale datasets by measuring a data freshness value. Data freshness is a crucial data quality metric that helps identify potential staleness. Stale datasets exhibit a continuous increase in their data freshness metrics. For example, if the most recent record in a dataset was inserted two days ago, its freshness metric is two days. However, if no new records are added or updated, the data freshness metric will continue to increase. To proactively address staleness, data teams should establish a maximum data delay threshold. When a dataset’s freshness metric exceeds this threshold, it triggers an alert, signaling potential staleness.
Beyond data freshness monitoring, other valuable techniques for detecting stale data include:
- Data Staleness Reports: Data teams can implement dedicated monitoring dashboards that display data freshness metrics for various datasets. These dashboards can highlight tables with the oldest data, enabling efficient prioritization of stale data investigations.
- Data Usage Monitoring: Many databases provide detailed logs of data usage, capturing information about SQL queries that read or modify tables. These logs offer valuable insights into which tables are actively used. By analyzing these logs, data teams can identify tables with no recent activity, suggesting potential staleness. For example, a query that joins a list of all defined tables to the query log using an outer join can reveal tables without recent access.
Best Practices for Managing Outdated Datasets
Implementing robust data retention management practices can significantly reduce the number of outdated datasets containing stale data. Here are some key recommendations:
- Define a Data Retention Policy: A clear data retention policy, established by the data governance team, is crucial. This policy should mandate regular reviews of datasets to identify and archive outdated information. It should also specify criteria for determining when data is considered stale and outline procedures for data archival or deletion.
- Decommission Datasets Gracefully: Avoid abruptly deleting stale tables. Premature deletion can disrupt critical business processes that may still rely on the data, even if it appears unused. Instead, adopt a more gradual approach. First, revoke access permissions to the table. Then, wait for a defined period to allow any potential dependencies to surface. If no issues arise, proceed with archiving or deleting the data.
- Tag Active Tables: Maintain an up-to-date data catalog that clearly identifies active datasets. This reduces the likelihood of data analysts inadvertently using temporary or unsupported tables. When analysts can easily find well-documented, actively maintained datasets, they are more likely to use them in their reports and analyses, promoting data reliability and consistency.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
What is the DQOps Data Quality Operations Center
DQOps is a data observability platform designed to monitor data and assess the data quality trust score with data quality KPIs. DQOps provides extensive support for monitoring data freshness.
Its built-in data quality reports show the age of data for each table, which allows the teams to find stale datasets.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can monitor data sources and ensure data quality within a data platform. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time. This is a great resource to learn about data quality.




