
Data quality principles are straightforward: define what constitutes bad data, detect data issues, and remediate those issues. These three principles might seem intuitive, yet many data teams find it challenging to implement them effectively. The core difficulties often stem from a lack of shared understanding regarding the definition of data quality and the practical application of improvement processes.
Poor data creates extra work for both data teams and data consumers, such as business analysts, data scientists, or business users who leverage data for insights and decision-making. Even with sophisticated data monitoring tools implemented by data engineering teams, a disconnect between business users and technical teams can lead to the neglect of critical data quality problems that significantly impact business operations and outcomes.
Bridging this communication gap is crucial. It can be achieved by establishing a common ground on the most impactful data flaws, the methodologies for issue discovery, and the established processes for flaw remediation. This shared understanding empowers everyone to contribute to and benefit from higher quality data.
Table of Contents
What is Data Quality
At its core, good quality data effectively fits its intended purpose. To truly understand this purpose, we must first identify all data stakeholders and thoroughly learn how each of them interacts with the data. This involves understanding their specific needs, workflows, and the questions they aim to answer using the data.
Defining “good data quality” requires a deep dive into the challenges faced by each data consumer. For instance, data scientists might struggle with discovering datasets that are immediately fit-for-purpose for training machine learning models, encountering issues like inconsistent formatting or a lack of necessary features. Ultimately, data quality is the ongoing process of ensuring data is usable and reliable for all its consumers. This involves establishing clear quality goals based on user needs, proactively identifying data issues, and implementing effective remediation strategies to resolve them.
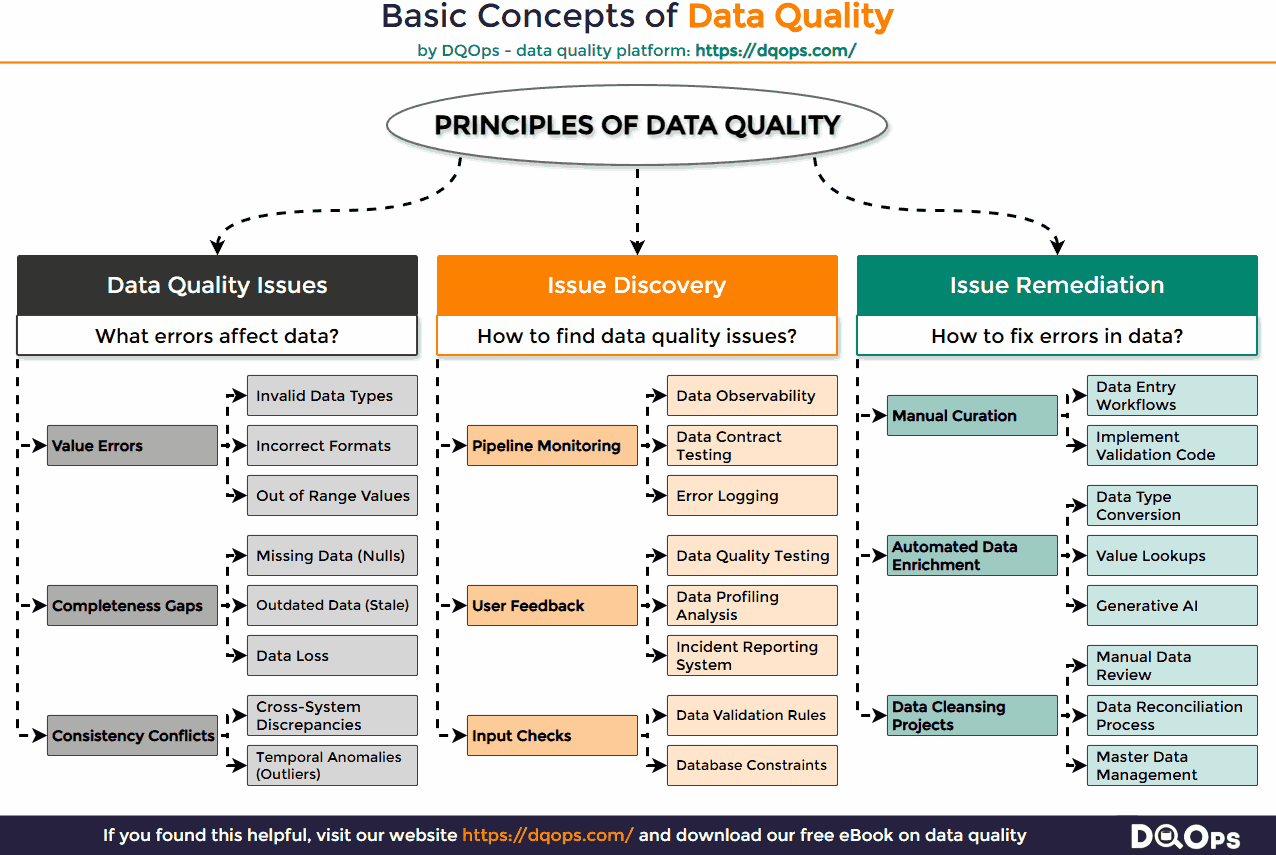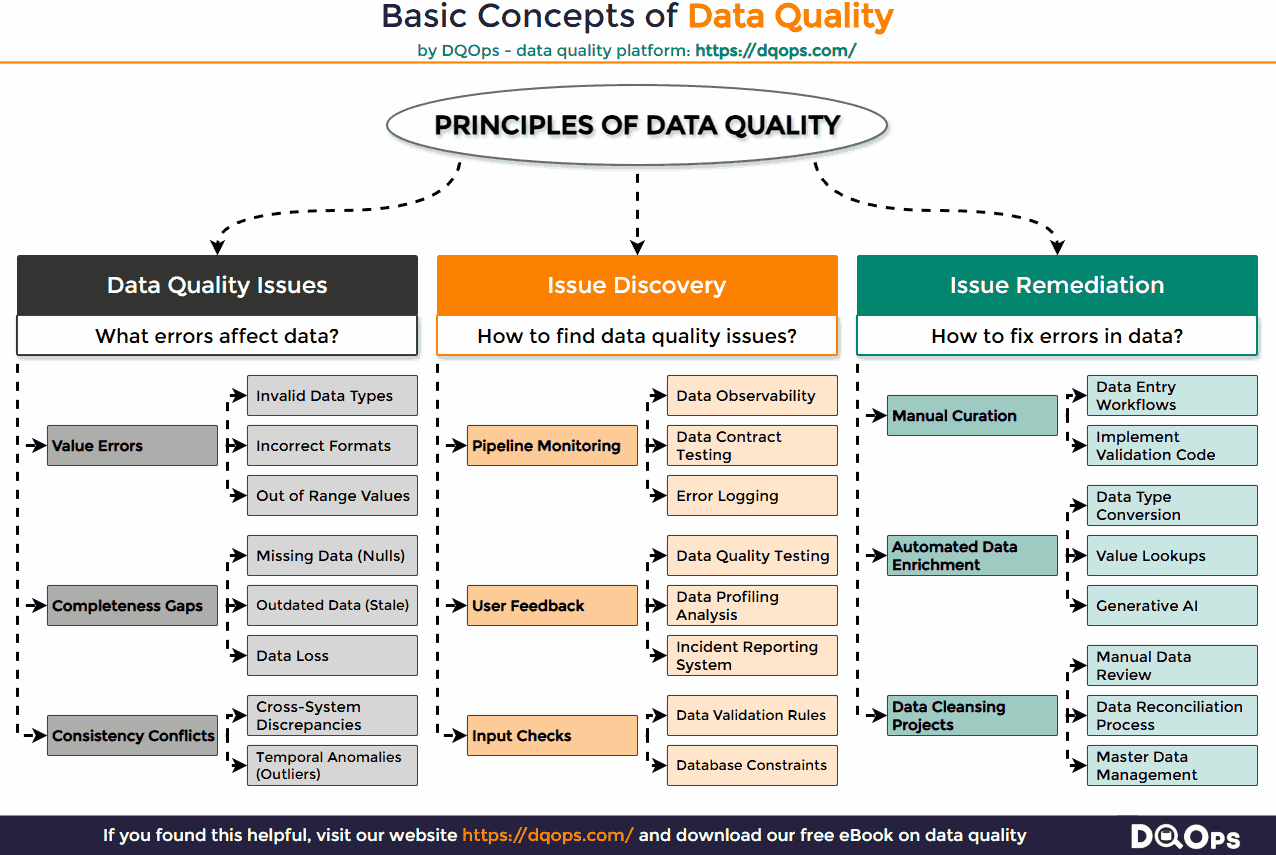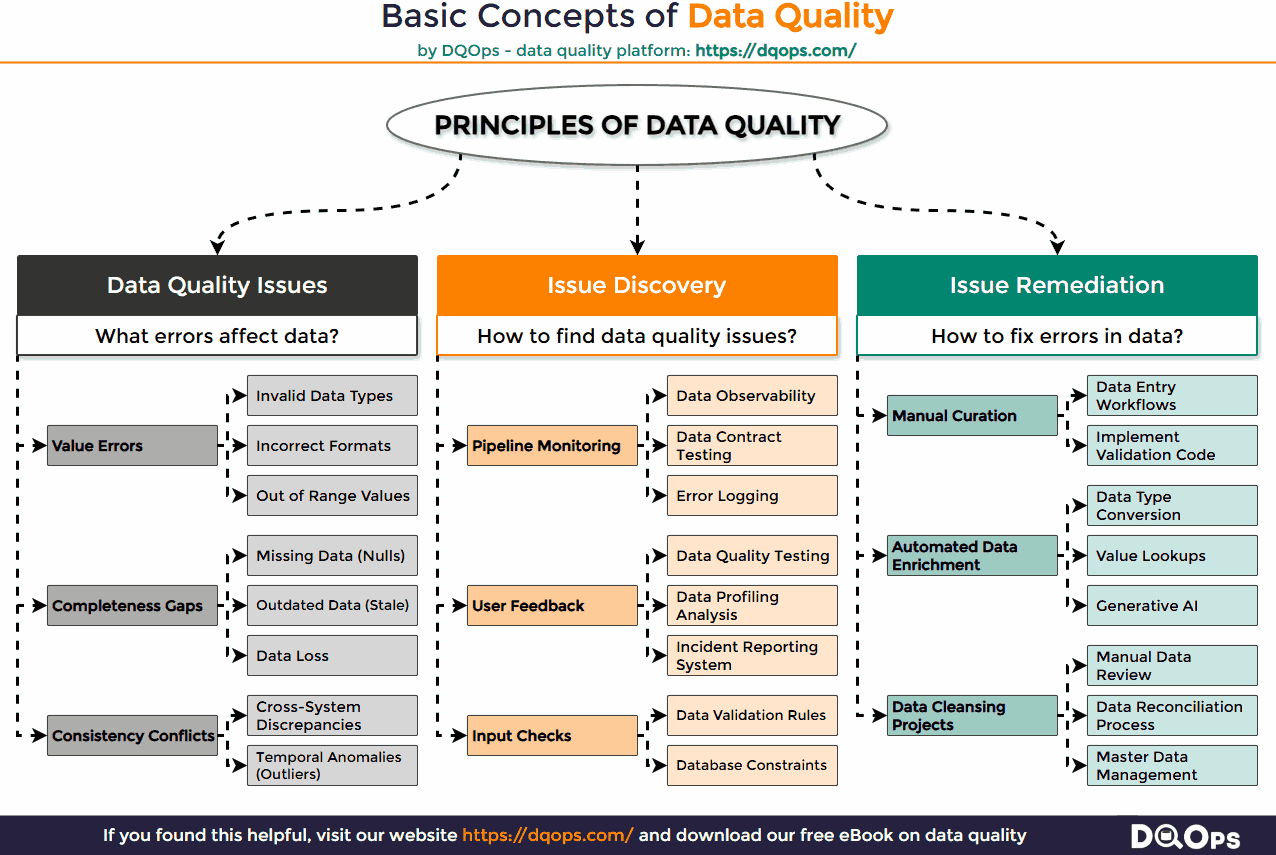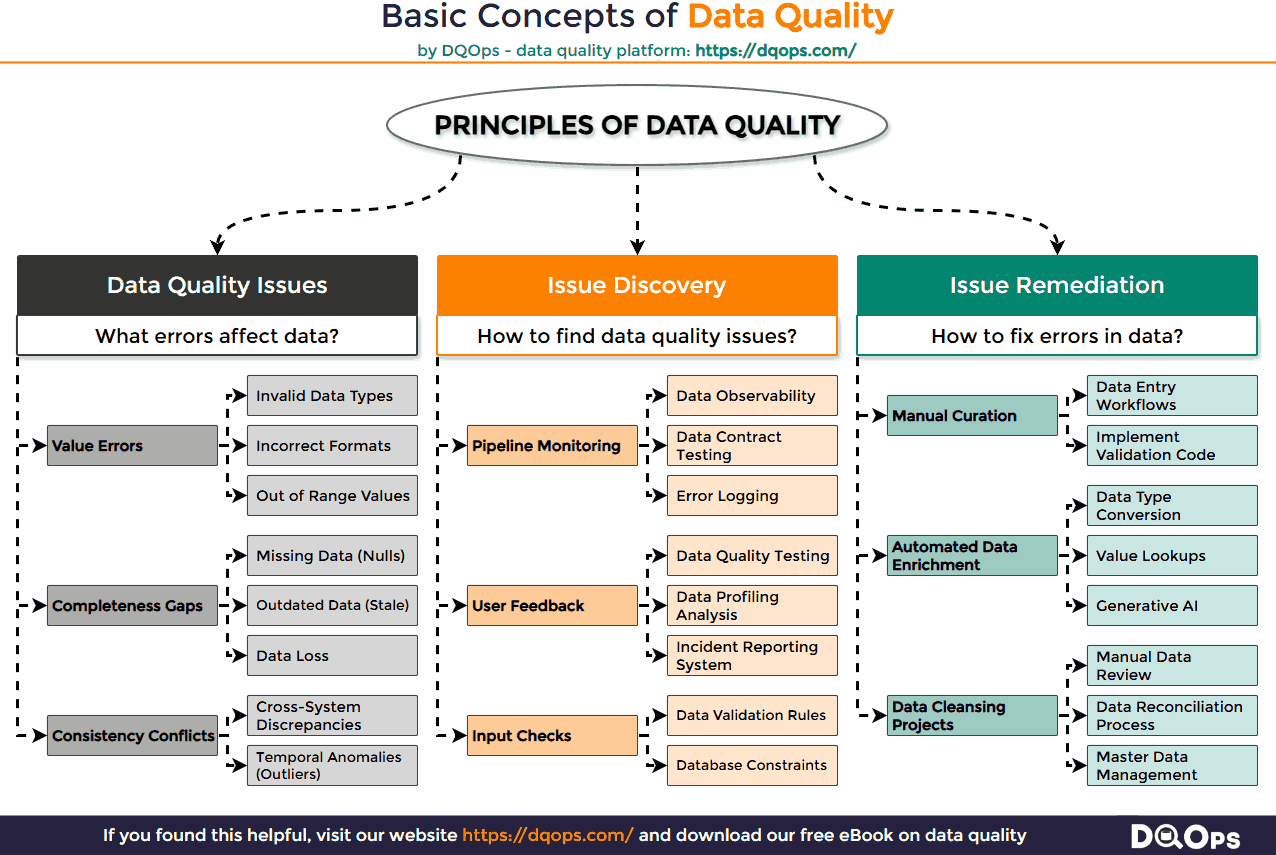
Examples of Data Quality Issues
Problems with missing data, incorrect data, or inconsistent data are three major factors that can render data unusable. While numerous other data quality issues exist, such as data duplication or integration errors, these three categories are particularly prevalent and impactful.
These three most common types of data quality issues are described below.
- Value Errors: These issues relate to the accuracy and validity of individual data points.
- Invalid Data Types: A date field containing text instead of a valid date format (e.g., “Hello” in a date column).
- Incorrect Formats: A phone number stored without the country code or with inconsistent separators (e.g., “1234567890” vs. “+48 123-456-789”).
- Out of Range Values: An age field containing a value of “200” or “-5”, which are illogical within the expected domain.
- Completeness Gaps: These issues involve the absence or lack of necessary data.
- Missing Data (Nulls): A customer’s email address is left blank in a record where it is a required field for communication.
- Outdated Data (Stale): Product pricing information in a database hasn’t been updated for several months, reflecting old prices.
- Consistency Conflicts: These issues arise when the same piece of information differs across various parts of the data landscape.
- System Discrepancies: A customer’s address is recorded differently in the CRM system compared to the billing system.
- Temporal Anomalies (Outliers): A sudden and unexplained spike in website traffic data for a specific hour that doesn’t align with any known events.
How to Detect Data Quality Issues
Data quality issues can be identified through various methods, often involving an analysis of already collected data. This might involve running specific queries or implementing additional validation rules directly within data entry interfaces to prevent the initial input of invalid information. Furthermore, actively engaging data stakeholders in testing and evaluating whether the data meets their specific needs provides valuable insights into potential quality problems. Finally, a significant portion of the detection process can be automated through dedicated tools and processes.
The following detection methods are most commonly used:
- Input Checks: Implementing controls at the point of data entry is a proactive way to prevent many common data quality issues. This involves setting up data validation rules within applications and forms to ensure that the data entered adheres to predefined formats, types, and ranges. Database constraints, such as NOT NULL constraints or unique keys, further enforce data integrity at the database level, preventing the storage of incomplete or inconsistent records from the outset.
- Pipeline Monitoring: As data moves through data pipelines, various techniques can be employed to monitor its quality. Data observability platforms provide a comprehensive view of data health, tracking metrics like completeness, accuracy, and consistency over time. Data contract testing involves defining expectations for the structure and content of data at different stages of the pipeline and automatically verifying if these contracts are being met. Additionally, systematic error logging captures any exceptions or anomalies encountered during data processing, providing valuable information for diagnosing data quality problems.
- User Feedback: Engaging business users and other data consumers is crucial for identifying issues that might not be apparent through automated checks. Data quality testing involves users actively examining data samples to verify their accuracy and completeness against their business knowledge and requirements. Data profiling analysis provides summary statistics and insights into the characteristics of datasets, often revealing unexpected patterns or anomalies that could indicate quality problems. Finally, establishing a clear incident reporting system allows users to flag data issues they encounter in their daily work, providing valuable real-world feedback on data quality.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
Best Practices in Fixing Issues in Data
The process of resolving data quality issues is commonly referred to as data cleansing. It involves identifying the most effective strategies to rectify existing errors and enhance data usability. These methods can range from directly correcting data within the existing dataset, such as standardizing formats or converting data types, to leveraging external data sources to enrich incomplete records or validate existing information.
The following methods can be used to cleanse incorrect data.
- Manual Curation: In some cases, fixing data issues requires direct human intervention. Data entry workflows can be designed or modified to incorporate validation steps and reduce the introduction of errors during manual data input. When errors are identified, implementing validation code or scripts can help standardize data formats or correct simple inconsistencies across a dataset.
- Automated Enhancement: Many data quality issues can be addressed through automated processes. Data type conversion tools can automatically transform data into the correct formats required by downstream systems or analyses. Value lookups involve using reference tables or external databases to fill in missing information or standardize inconsistent entries. Increasingly, Generative AI for Data offers powerful capabilities for tasks like data imputation, anomaly detection, and intelligent data correction.
- Remediation Initiatives: For more systemic or widespread data quality problems, dedicated projects are often necessary. Manual data review involves subject matter experts examining data to identify and correct errors based on business rules and understanding. Data reconciliation processes compare and resolve discrepancies between different data sources to ensure consistency. Finally, Master Data Management (MDM) projects aim to create a single, consistent, and accurate view of critical business entities, which often involves extensive data cleansing and standardization efforts.
What is the DQOps Data Quality Operations Center
DQOps is a data quality and observability platform designed to monitor data and assess the data quality trust score with data quality KPIs. DQOps provides extensive support for configuring data quality checks, applying configuration by data quality policies, detecting anomalies, and automatically finding patterns using machine learning. DQOps supports over 150+ data quality checks, which cover all popular formats used in data conformance testing.
DQOps is a platform that combines the functionality of a data quality platform to perform the data quality assessment of data assets. It is also a complete data observability platform that can monitor data and measure data quality metrics at a table level to measure its health scores with data quality KPIs.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can monitor data sources and ensure data quality within a data platform. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time. This is a great resource to learn about data quality.




