
Data quality and software quality assurance serve a similar purpose: they ensure the reliability of platforms by testing to find errors. The difference lies in the components they test. Software quality assurance tests the behavior of applications to ensure that software behaves according to requirements. Data quality analyzes the health of data to detect missing or invalid data.
A key distinction is that a fully tested application, having passed all tests and released to users, will work correctly almost forever. Data quality is very different. Data pipelines and data transformation code are tested on fake data or data samples. However, when the data platform runs on real data, data sources can be updated and send data in a different format or stop sending required information. Data quality must be tested at regular intervals to notice when the data structure or distribution changes.
Table of Contents
What is Data Quality
Data quality refers to the overall reliability and fitness of data for its intended use. High-quality data is accurate, complete, consistent, timely, and valid. It’s essential for making informed decisions, ensuring accurate analyses, and maintaining the integrity of business processes. Poor data quality, on the other hand, can lead to flawed insights, operational inefficiencies, and even financial losses.
Various factors can contribute to data quality issues. These include:
- Inconsistent Data: Data discrepancies across different systems or databases, such as variations in customer names or addresses.
- Incomplete Data: Missing values or incomplete records, like a customer record missing a phone number or address.
- Inaccurate Data: Errors in data entry or data migration, leading to incorrect values.
- Outdated Data: Data that is not current, such as using old customer contact information.
- Invalid Data: Data that does not conform to predefined standards or constraints, for example, an invalid email address format.
These issues can arise from various sources, including human error during data entry, system glitches, integration challenges between different systems, or changes in source systems. For example, a data source owner might change the schema of a database table without notifying downstream consumers, leading to data integration failures and data quality issues. Therefore, organizations need to implement robust data quality management practices to proactively identify and address these issues. This often involves data profiling, cleansing, validation, and ongoing monitoring to ensure data remains reliable and fit for purpose.
What is Software Quality Assurance
Software Quality Assurance (SQA) is a systematic process that ensures software applications meet predefined quality standards and function as intended. It involves a series of activities performed throughout the software development lifecycle, from requirements gathering to deployment and maintenance. SQA focuses on preventing defects, identifying and resolving issues early on, and ultimately delivering a reliable and high-quality product to users.
SQA teams play a crucial role in this process. They are responsible for:
- Understanding and translating software requirements: This involves analyzing user needs and functional specifications to define clear and testable criteria.
- Developing comprehensive test suites: These suites consist of individual test cases designed to verify specific functionalities and aspects of the software. Each test case outlines a series of actions to perform on the application and defines the expected results.
- Executing tests and analyzing results: SQA teams conduct various types of testing, such as unit testing, integration testing, system testing, and user acceptance testing. They meticulously document test results and report any deviations from expected behavior.
- Collaborating with development teams: SQA professionals work closely with developers to identify the root cause of defects and ensure timely resolution. They also provide feedback on software design and implementation to improve overall quality.
The SQA process requires close coordination with product managers, project managers, and software developers. SQA teams participate in design reviews, code inspections, and testing phases to ensure alignment between requirements, development activities, and quality goals. By adhering to established processes and best practices, SQA helps mitigate risks, reduce development costs, and enhance user satisfaction.
Data Quality vs Software Quality Assurance
In assessing the similarities and differences between software development and data management, one can’t ignore the parallels between data quality and software quality assurance. Both data quality and software quality assurance constitute fundamental aspects of their respective processes, and share crucial similarities.

Software quality assurance aims to evaluate a system’s functionality through invasive testing. Testers mimic user interactions with the application, such as creating an administrator account and verifying its access rights. However, due to potential disruptions, performing such tests on a production system regularly is impractical.
Data quality varies. Instead of generating fake data to validate all potential transformation outcomes, we noninvasively test real data flowing into and out of the data platform against constraints and data contracts. Since every data platform possesses sufficient real data, creating mock data is superfluous.
There are noticeable similarities in the processes of developing software and building data platforms. Quality assurance can be implemented during these processes to identify and address issues that may arise during development, testing, and monitoring, ensuring the overall quality and reliability of the solution.
- Tests executed inside data pipelines are similar to unit tests.
- Data quality checks are similar to performing system tests.
- Data observability is similar to infrastructure monitoring platforms.
Data quality possesses a substantial advantage over software quality assurance: its noninvasive character. This permits daily execution of the entire data quality checks suite on production data platforms. The data quality checks selected by data engineers during the development phase transform into data observability checks conducted daily or after each data load operation.
Let’s explore how the data quality vendors address these stages.
Roles across data platform lifecycle
As the data platform continues to evolve, various roles emerge, assuming leadership positions to drive its progress and advancement.
Development
At the outset of a data engineering project, data engineers primarily focus on constructing data pipelines and delivering the initial dataset. Their main objective revolves around the coding aspect of the project, which involves employing a wide range of tools and technologies.
Data engineers can choose a popular data transformation dbt (Data Build Tool) or build custom data pipelines from the ground up. This approach can be more time-consuming and complex, but it gives them more control over the data transformation process. Custom data pipelines can be built using a variety of programming languages and tools, such as Python, Java, and Apache Airflow.
Once the data pipelines have been constructed and the initial dataset has been delivered, data engineers typically shift their focus to other tasks, such as data quality monitoring, data governance, and data security.
Testing
As the data pipelines are successfully established, the platform transitions from the hands of data engineers to data consumers. This diverse group includes data scientists, data analysts, and individuals well-versed in data manipulation. These professionals assume the critical role of “Data Quality Engineers” or, in simpler terms, data platform testers. Their primary focus shifts from constructing the platform to testing whether it satisfies their needs.
A company may also have a dedicated data quality team. The role of Data Quality Engineers involves rigorous testing and evaluation of the data pipelines, data integrity, and system performance. They employ a systematic approach to identify and address any data quality issues that may arise, ensuring that the data provided by the platform is trustworthy and reliable. This includes testing the data for accuracy, consistency, completeness, and validity and assessing the platform’s performance under various conditions.
By adopting this role, data consumers become the gatekeepers of data quality, safeguarding the platform’s credibility and enabling accurate and reliable decision-making based on the data it provides. They work closely with data producers and data engineers to ensure that the data pipelines are designed and implemented to minimize the risk of data quality issues. They also establish and enforce data quality standards, policies, and procedures to ensure the data is handled and processed consistently and reliably.
The role of Data Quality Engineers is becoming increasingly critical as organizations become more data-driven and rely on data to make informed decisions. By ensuring the quality and reliability of the data, Data Quality Engineers play a vital role in supporting data-driven initiatives and enabling organizations to achieve their business objectives.
Your organization does not require a dedicated data quality team. Every data-literate user who wants to find and assess a dataset’s quality becomes a data quality tester for a while. All data scientists and data analysts are your data consumers. They need an effective and reliable way to profile external data sources, flat files on data lakes, or look up the data quality score of a dataset that somebody else has already profiled.
A slight difference exists between testing external data sources and already ingested datasets.
- When you profile external datasets, you assess their quality and usability before ingesting them into the data platform. This requires a tool to analyze new data sources quickly.
- When you profile the data you have ingested, you are a data quality tester. The additional data quality checks that you activate will accumulate. The data quality platform should evaluate the data quality checks every day to detect when the data is no longer usable. It is called Data Observability.
Operations
Once the platform has been successfully completed and deployed, the focus shifts from development to operations. During the operations phase, the primary objective is to ensure the platform’s smooth and efficient functioning. This involves various activities, such as monitoring system performance, resolving technical issues, and implementing updates and enhancements.
Whether an organization chooses to manage operations internally or outsource them, the ultimate goal is to maintain a high level of service quality and ensure the platform meets the needs of its users. By implementing effective operational practices and continuously monitoring and improving the platform, organizations can maximize the value and longevity of their investment.
How data quality platforms map to test stages
Most existing data quality vendors focus solely on a specific user group, and their platforms are limited to addressing a single aspect, disregarding the natural progression from development to operations.
Development stage platforms
Data engineers can utilize code-based tools, implemented as Python libraries, for data quality solutions. These libraries can be directly integrated into data pipeline code. Data quality checks can be configured in the source code or defined in YAML files.
When integrated into the data pipeline, data quality checks become part of the data platform solution. These checks offer an efficient method for monitoring data quality in the development mainly because they require minimal setup. Data quality tools can be employed directly on data engineers’ computers, enabling them to test code changes promptly.
Pros
- Easy to set up.
- They run directly on the data engineer’s machines
- They are tightly integrated into the data pipeline.
Cons
- Reconfiguring the data quality checks requires a code change to be deployed as part of the data platform.
- The support team must be proficient in coding to activate additional data quality checks. They can also break the data pipeline code by mistake.
- Embedded libraries do not store historical results that are required for anomaly detection.
- Data customers without technical knowledge face challenges managing data quality because there is no user-friendly interface for configuring data quality checks.
Testing stage platforms
It’s disappointing that the majority of popular Data Quality platforms for data quality engineers are large-scale Data Governance solutions. Data Quality is not a key component of these comprehensive solutions, and they focus primarily on data discovery and data cataloging. These platforms typically offer a limited number of data quality checks, around 20-50. Contrastingly, DQOps prioritizes data quality as its core feature, providing over 150 data quality checks.
Pros
- You are getting a complete Data Governance solution.
- You can improve the organization’s data governance process by implementing these platforms.
Cons
- If you choose these platforms, you must also implement their vision of Data Governance.
- They do not integrate well into the data pipelines because you cannot run them anywhere you want.
- The configuration of data quality checks is stored in the platform’s database, making migration between environments a nightmare.
- You need the vendor’s assistance to set up.
- You cannot easily set up a local development instance to perform data profiling and validate new data quality checks.
- They are costly because it is always a packaged deal.
Operations stage platforms
Data observability solutions are the data quality platforms for data operations. They provide a quick way to activate essential volume, completeness, schema change, and anomaly detection for existing data platforms. You set them up, register the data sources, and await notifications
They can detect changes in stable datasets that are in production. However, they need more coverage for the development and testing phases. Suppose you connect them to a data source that is still under development and actively evolving. In that case, you will get lots of alerts—alerts that are obvious because of the schema changes that are happening.
Another limitation of pure Data Observability tools is the number of data quality dimensions they can measure. They do not offer an extensive list of data quality checks. Custom checks must be implemented as SQL queries with hardcoded table and column names.
Pros
- It’s very easy to activate. Just register the data sources.
- The benefits are instant, even without any work on your side.
Cons
- They need a centralized database to store historical data for anomaly detection.
- You cannot run them on a data engineer’s laptop. Do you want to experiment with new data quality checks? Forget it.
- They have a limited list of built-in data quality checks.
- The user interface of many of these tools is not designed for productivity. Configuring 100 similar checks across different tables and columns takes a lot of effort.
- If you need to create custom data quality checks requested by business users, you must hardcode table and column names in the SQL query. Let’s skip discussing the effort required to migrate and rename tables when you have to reconfigure data quality checks.
Data quality software
Effective data quality management requires specialized tools to automate and streamline the process of checking and improving data. Data quality software provides the functionality to connect to various data sources, execute data quality checks, and monitor data health over time.
These data quality checks are analogous to test cases in software quality assurance. Each check focuses on a specific quality aspect of the data, such as completeness, accuracy, consistency, or validity. They operate by performing actions on the data and comparing the results against expected values.
For example, a data quality check might validate that a table has at least 100 records. This check would execute a query to count the rows in the table and then compare the result against the expected minimum value of 100. Another check might verify that all email addresses in a customer database conform to a valid format.
Data quality checks are defined within these tools in various ways. Some open-source tools require users to code checks in languages like Python, YAML, or JSON. This approach offers flexibility but demands technical expertise. Other tools, such as DQOps, provide user-friendly interfaces to activate pre-built or custom data quality checks, enabling users to test data from their laptops or a central server without extensive coding.
Choosing the right data quality software depends on your specific needs and technical capabilities. You can explore an article comparing various open-source data quality tools to help you find the best fit.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
How DQOps supports all data quality use cases
DQOps Data Quality Operations Center is a data quality platform designed to follow the data platform along its maturity stages. It is named DQOps Data Quality Operations Center because, like DevOps and DataOps, DQOps focuses on automating data quality. The Operation Center stands for the user interface for all users who work with data quality and want the work done quickly. That is the approach to a smooth transition from development to operations.
The main goal of DQOps is to facilitate the data quality process for the whole lifecycle.
- Data profiling: Data-literate users can profile data sources such as relational databases, data lakes, or flat files (CSV, JSON, Parquet). It supports over 150 data quality checks that cover all the most common issues.
- Data monitoring: After data profiling, you can pick the trustworthy data quality checks and run them daily as part of the Data Observability test suite.
- Data operation: DQOps sends notifications of data quality incidents to the right team. You can also validate the conformance to Data Contracts and data quality KPIs on data quality dashboards.
The main competitive advantage of DQOps over other data quality platforms is how quickly it adapts to all stages of the data platform maturity. That means providing value for technical users and data consumers who prefer no-code data quality solutions.
- Multiple interfaces: Data quality checks can be configured using various approaches. You can either manage checks through a user interface, configure them in YAML format, automate the process with a Python client, or utilize a command-line interface. Your choice of approach depends on your preferences and your project’s specific requirements.
- Flexible deployment: Input Text: If you want to quickly analyze a new CSV file, you can set up DQOps locally on your laptop in just 5 seconds. This is a convenient way to get started with DQOps and explore its features.
- Fully extensible: The data quality checks are divided into two components: a sensor and a rule. A data quality sensor is an SQL query defined as a Jinja2 template that captures a measure such as a row count. A data quality rule written in Python validates the measure and can apply machine learning to detect anomalies.
DQOps YAML files as Data Contracts
DQOps stores the configuration of data sources and data quality checks in YAML files. These files define the data contract for the tables. By copying the folder of the data source, you can easily migrate the configuration between databases.
You start DQOps in an empty folder, which becomes your DQOps user home folder. You can commit the files to a Git repository. The folder and file name structure follows the convention over configuration principle.
- Folder names are named as your data source names
- File names for every monitored table follow the naming convention: “<schema_name>.<table_name>.dqotable.yaml”.
You can register another table with the same schema as another table by copying the .dqotable.yaml file under a new name. Moving the configuration between development and production databases or following schema changes is simple.
In Visual Studio Code and other code editors, we’ve made editing the configuration files much easier. Each DQOps YAML file now references a YAML/JSON schema file, which provides an unparalleled editing experience in Visual Studio Code and helps prevent errors when manually editing the files.
- The code editor offers completion suggestions for all configuration nodes, including the right names and parameters for data quality checks.
- Invalid elements are highlighted at all levels.
- When you hover over an element in Visual Studio Code, in-place documentation for all 600+ variants of data quality checks supported by DQOps is displayed.
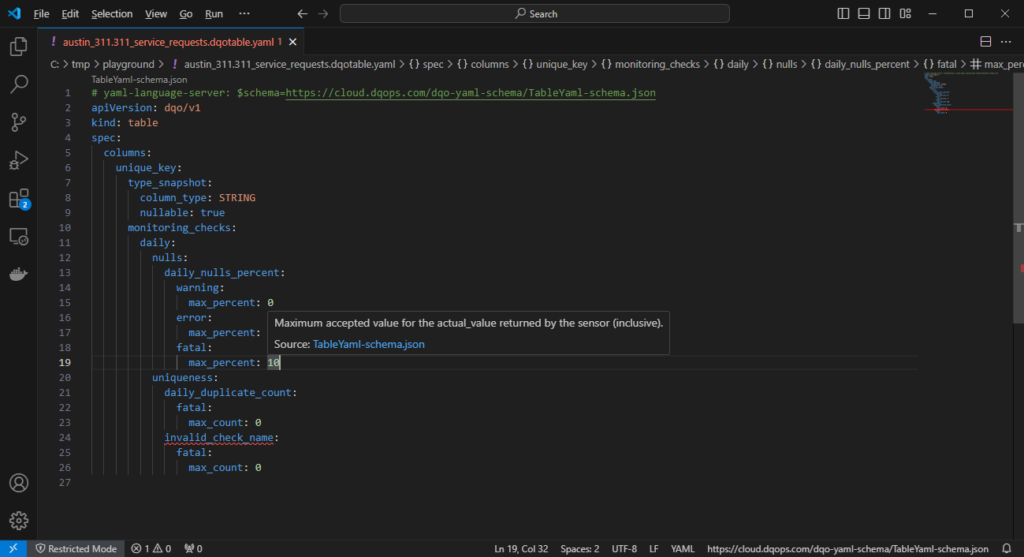
No-code editor for data quality checks
Handling data quality checks’ configuration in code might only be feasible for technically skilled individuals. As the data platform project switches from development to business operations, the responsibility for monitoring the solution will eventually fall to the support teams.
The user interface in DQOps for managing data quality checks is dynamic in nature. It allows users to edit and manage both built-in and custom data quality checks conveniently. Read more about the DQOps platform user interface.

Data quality incident management
To ensure data quality and reliability for effective decision-making, incident management of data quality issues is crucial. It involves a structured approach to swiftly identify, address, and resolve inconsistencies or errors within datasets. Data engineers lead the technical investigation and remediation, while data owners provide insights into the data’s intended use and criticality. Data operations teams monitor the health of data systems. This collaborative effort minimizes the negative impact of data quality problems, maintaining a high level of data integrity throughout the organization.
DQOps manages the process by consolidating similar data quality issues into incidents related to data quality. Newly created incidents are forwarded to the operations team for assessment. Incidents that are confirmed are then assigned to data engineers or data owners to be resolved. Additionally, you have the option to mute positive incidents. Moreover, DQOps provides support for notifications through Slack. Alternatively, DQOps can make calls to webhooks, enabling synchronization of the incidents with external ticketing systems like ServiceNow. Learn more about incident management in the DQOps documentation.
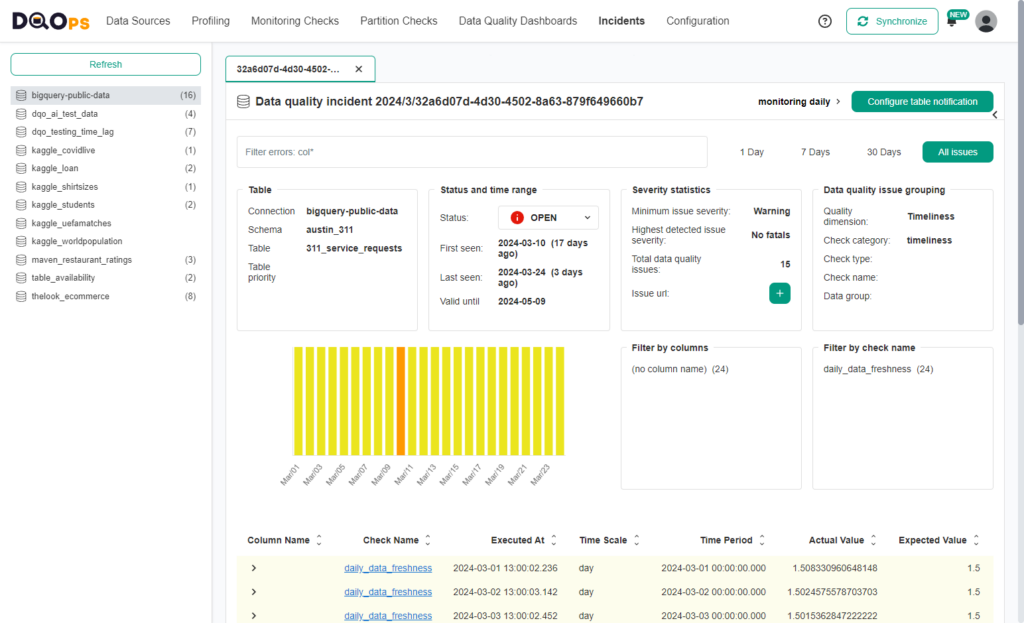
Getting started with DQOps
DQOps, a data quality and observability platform, offers immediate usability and flexibility through multiple installation options. It supports various operating systems, including Linux, MacOS, and Microsoft Windows. Deployment architectures range from standalone local installations to production setups on servers, enabling collaboration among numerous users. Learn more about DQOps architecture in the documentation.
DQOps, accessible as a downloadable PyPI package, allows for standalone deployment, making it a convenient data quality tool. Data scientists can harness the power of DQOps as a local tool to profile data sources, enhancing their data quality management capabilities. A standalone instance provides multiple interfaces to interact with the platform:
- Intuitive user interface that simplifies data management, offers data profiling capabilities, and enables efficient execution of data quality assessments. Explore more about the platform user interface.
- The command line interface seamlessly autocompletes data sources, tables, columns, and check names.
- A Python client that facilitates data quality checks within a Notebook environment. This client enables users to seamlessly perform these checks, enhancing the overall data analysis and validation process.
- YAML files which are intended for editing in Visual Studio Code and version control through a Git repository. Learn more about editing DQOps YAML files with with VS Code.
The following is a summary of the installation options available with pip and docker:
Install DQOps locally in 30 seconds
DQOps is a data quality and observability platform that works both locally or as a SaaS platform.




