
A data quality issue happens when something goes wrong with the data itself. This could mean data is missing, outdated, or in the wrong format.
In the world of data, “quality” simply means that the information is reliable and useful. A data quality issue happens when something goes wrong with the data itself. This could mean data is missing altogether, like a customer record without a phone number. It might be duplicated, causing confusion. Sometimes, data gets old and outdated – think of product prices that haven’t changed in years. Other times, the problem is formatting: imagine a date written as “01/12/2023” – does that mean January 12th or December 1st?
These problems can pop up anywhere data is stored. Your company’s customer database, the big data warehouse that tracks sales, even the sprawling data lake where you keep all sorts of information – all these places can be affected by data quality issues.
Table of Contents
The cost of bad data
Bad data leads to bad decisions. Imagine a database where customer orders have incorrect quantities. The dashboard reporting sales figures will be wrong and might even show you’ve sold more products than you actually have in stock! Or, if financial data in your data warehouse has errors, your company might overestimate its budget for the next year. This can lead to overspending and potentially serious financial problems down the line.
Essentially, data quality issues make it hard to trust the information you’re working with, and that can have a big impact on your business.
The source of data quality issues
Data quality issues don’t just appear out of thin air. They often stem from two main sources: changes in business processes or technical glitches within your data platforms.
Business Process Changes: The Human Factor
When your company changes how it operates, your data can suffer. Imagine shifting who’s responsible for entering customer data. A new team, unfamiliar with the old way of doing things, might make mistakes or forget to enter key details. Or, let’s say you outsource a task to an external vendor. Their processes might differ, leading to inconsistencies or missing values. Even seemingly small changes, like moving a process to another department, can introduce errors if people aren’t properly trained.
Technical Issues: Behind the Scenes of Your Data
Data doesn’t just sit in one place. It often flows through multiple systems before reaching its final destination. For instance, customer data from your CRM system might be copied to a data lake, then moved to a data warehouse, and finally transformed into a data mart for reporting. Each step involves complex data processing code. If that code isn’t updated to reflect changes in the source system, you might end up with mismatched data or errors.
Even minor technical oversights can cause problems. For example, a data engineer might not account for very large values when designing a data table. If a huge sales figure comes in, it might get cut off, leading to inaccurate reporting. And let’s not forget testing! If you don’t thoroughly test your data transformations, unexpected errors can slip through the cracks.
Types of problems and errors affecting data
The world of data quality issues can seem vast, but luckily, there’s a handy way to categorize them: data quality dimensions. These dimensions are like different lenses through which you can view and understand data problems. Let’s take a look at some of the key dimensions:
Data Completeness: Is Anything Missing?
Imagine a customer record without an email address. That’s a completeness issue. This dimension focuses on whether all the essential information is present and accounted for. Missing values in required fields, like phone numbers or product IDs, can cause all sorts of problems, from inaccurate reports to failed marketing campaigns.
Data Uniqueness: Are We Seeing Double?
Ever received two copies of the same email from a company? That’s a uniqueness issue. Duplicate data clutters your systems, making it hard to identify the correct information. This dimension helps you spot and address situations where the same customer, product, or transaction appears multiple times.
Data Validity: Does This Make Sense?
An email address that looks like “johndoe@@example.com” is a validity issue. This dimension deals with whether data values follow the correct format or rules. Invalid phone numbers, incorrect dates, or addresses that don’t exist are all examples of validity problems.
Data Consistency: Do These Match Up?
Data consistency issues arise when information in different systems doesn’t agree. For example, your CRM system might show a customer’s address as “123 Main Street,” while your billing system has it as “123 Main St.” This mismatch can lead to confusion and errors, especially when data is used across multiple departments.
Understanding these data quality dimensions helps you pinpoint the specific types of problems you’re facing. Once you know what you’re dealing with, you can start implementing strategies to fix those issues and improve the overall quality of your data.
Data quality issues vs software bugs
It’s easy to lump data quality issues in with software bugs, but that’s a mistake. While both can cause headaches, they’re fundamentally different beasts.
A software bug happens when there’s a flaw in the code. Maybe a developer missed a scenario during testing, and now the software crashes when a user performs that action. Fix the bug, and the problem is solved – permanently.
Data quality issues are trickier. Bad data gets stored in your systems, and simply fixing the software won’t magically clean it up. You might need to manually scrub the data, a process that can be time-consuming and complex.
And that’s not all. Data quality issues can arise from sources outside your immediate control. A change in an upstream system, like your CRM, could introduce errors into your data warehouse. Even shifts in business processes can lead to new data problems. These issues are hard to predict and can resurface even after you’ve “fixed” them once.
This is where the comparison to software bugs breaks down. A well-maintained application should have fewer and fewer bugs over time. But data platforms, exposed to a constant stream of changes, can actually see an increase in data quality issues.
The takeaway? Don’t treat data quality issues as one-and-done problems. You need to be prepared for a long-term effort, constantly monitoring and fixing data problems as they arise.
The weight of business data quality issues is bigger than the technical issues.
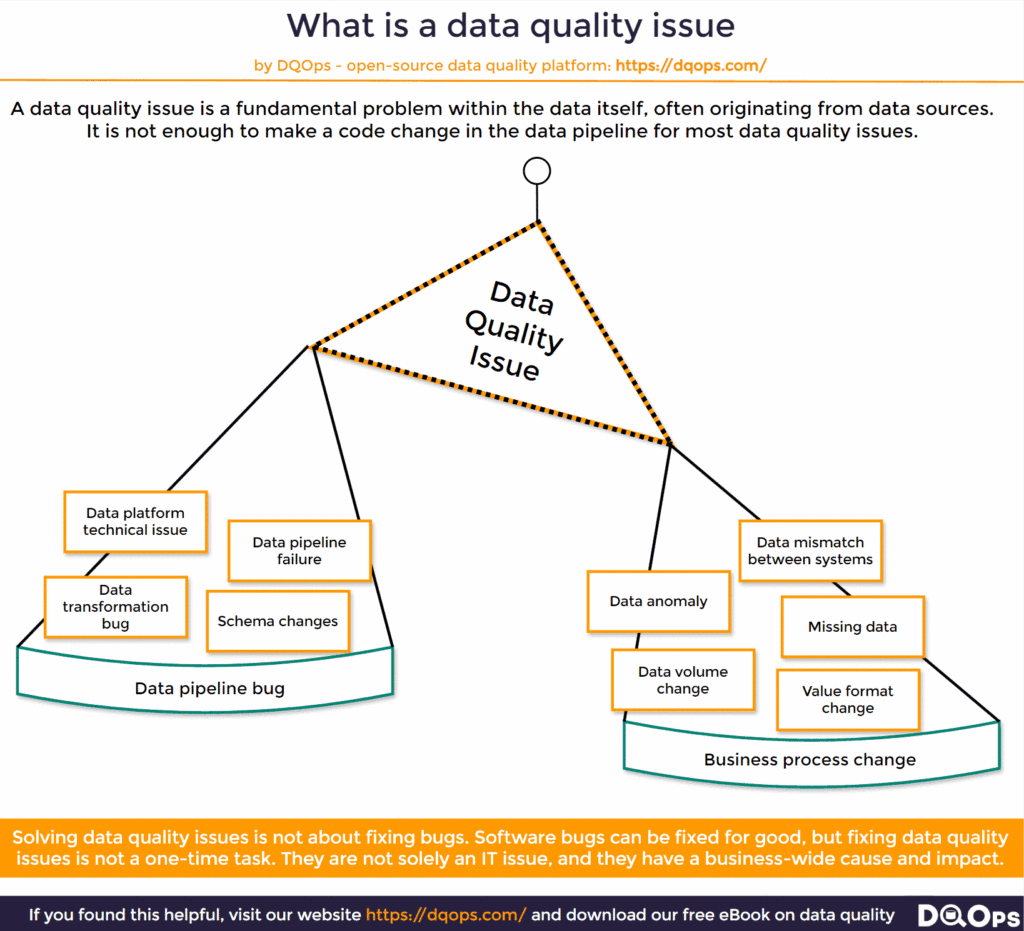
How to detect issues in data
Spotting data quality issues isn’t a one-time task. It requires ongoing vigilance. Thankfully, you don’t have to manually inspect your data every day to catch problems. This is where data observability platforms come in.
By connecting a data observability platform to your data environment, you gain a powerful ally in the fight for data quality. These platforms continuously monitor both your data sources (like CRM systems or databases) and the tables within your data platforms (data warehouses, data lakes).
Think of them as automated watchdogs, constantly running a series of data quality checks. These checks verify if any of the common issues related to data quality dimensions are creeping into your data. Are there missing values? Duplicates? Invalid formats? The platform will flag these problems, giving you an early warning system.
But data observability platforms go beyond simple checks. They leverage machine learning for anomaly detection. This means they can identify unexpected shifts in your data patterns. For example, a sudden spike in missing customer phone numbers might signal a change in how data is being collected in your CRM system.
By continuously monitoring and analyzing your data, these platforms help you detect problems before they escalate into major issues. They empower you to proactively address data quality concerns, ensuring your data remains reliable and trustworthy.
Fixing incorrect data
Data observability platforms are great at spotting problems, but a constant stream of alerts about individual issues can overwhelm your data operations team. That’s where data quality issue clustering comes in.
Think of it as a smart way to group similar issues together. Instead of getting bombarded with separate alerts for each missing value in multiple columns, a smart data observability platform will bundle them into a single, actionable incident. This approach reduces noise and helps your team prioritize their efforts.
But it doesn’t stop there. These platforms can also automate the process of assigning incidents to the right people. If a problem stems from a change in the business process, the platform might automatically route the incident to the relevant data owner. On the other hand, if the issue lies in a data pipeline, it could be assigned directly to the data engineering team responsible for fixing it.
This intelligent routing saves time and ensures that the right people are tackling the right problems. By streamlining the incident management process, data observability platforms empower your team to address data quality issues quickly and efficiently, minimizing their impact on your business.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
What is the DQOps Data Quality Operations Center
DQOps is a data quality platform designed to monitor data with both standard data observability checks and with custom data quality checks that can detect problems from the business perspective, validating the data as the user would see it. DQOps provides extensive support for configuring data quality checks, clustering issues into incidents, and managing the data quality incident workflow. Another strong point of DQOps is its approach to root cause analysis, allowing users to explore the data about recent data quality issues using over 50 data quality dashboards.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can be used to analyze data assets in a centralized or decentralized environment. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time.




