
Data engineers often face challenges with increasing volumes of data. Automated ETL data pipelines offer a solution by using metadata to manage and process this data efficiently. This automation reduces manual effort and allows for the processing of many data tables without changing the core code of the pipeline.
The key to automating ETL pipelines is separating the configuration from the code. This means storing information about data sources, transformations, and target tables in a separate location called “configuration metadata.” The ETL pipeline then reads this metadata and uses it to process the data. This approach allows you to add or modify data sources and processing steps by simply updating the metadata, without changing the underlying code. This makes the process more flexible and easier to manage.
When ETL Data Pipeline Should be Automated
Traditional ETL tools often require manual configuration for each data source and transformation. This can be time-consuming, especially when dealing with hundreds or thousands of tables. While manual configuration might be necessary for critical tables with complex transformations, many situations benefit from automation.
Consider these scenarios where automating your ETL pipeline is beneficial:
- High Volume of Similar Tables: If you have many tables with the same structure, automating the process can save significant time and effort. For example, a retail company with hundreds of stores might receive a separate data file for each store. Automating the loading process for these files eliminates the need for manual configuration for each store.
- Frequent Changes in Data Sources: If your data sources change frequently, automation provides the flexibility to adapt quickly. When new sources are added or removed, the automated pipeline can adjust without manual intervention. This is crucial for businesses that constantly evolve and add new data sources.
- Data Replication: When replicating data across different platforms, such as from a database to a data lake, automation simplifies the process. The automated pipeline can use metadata to identify and replicate new tables automatically, reducing manual effort and ensuring data consistency.
In essence, automating ETL pipelines improves efficiency, reduces manual errors, and provides greater flexibility in managing your data infrastructure.
What Is Metadata
In the context of ETL data pipelines, metadata is essentially any data that describes or supports the data processing, but is not the actual data being processed. Think of it as the “data about the data.” This includes information about the pipeline’s configuration, operation, and performance.
Metadata can be divided into two main categories:
- Input Metadata: This is the configuration data that instructs the ETL pipeline. It defines the source and target systems, the data transformations to be performed, and any other rules or settings for the pipeline. Input metadata allows the pipeline to be flexible and adaptable to different data sources and processing needs.
- Output Metadata: This type of metadata is generated by the ETL pipeline during its operation. It includes logs, performance metrics, error reports, and any other information that provides insights into the pipeline’s execution. Output metadata is crucial for monitoring, troubleshooting, and optimizing the pipeline’s performance.
The types of metadata used by ETL data pipelines are described in the following infographic.
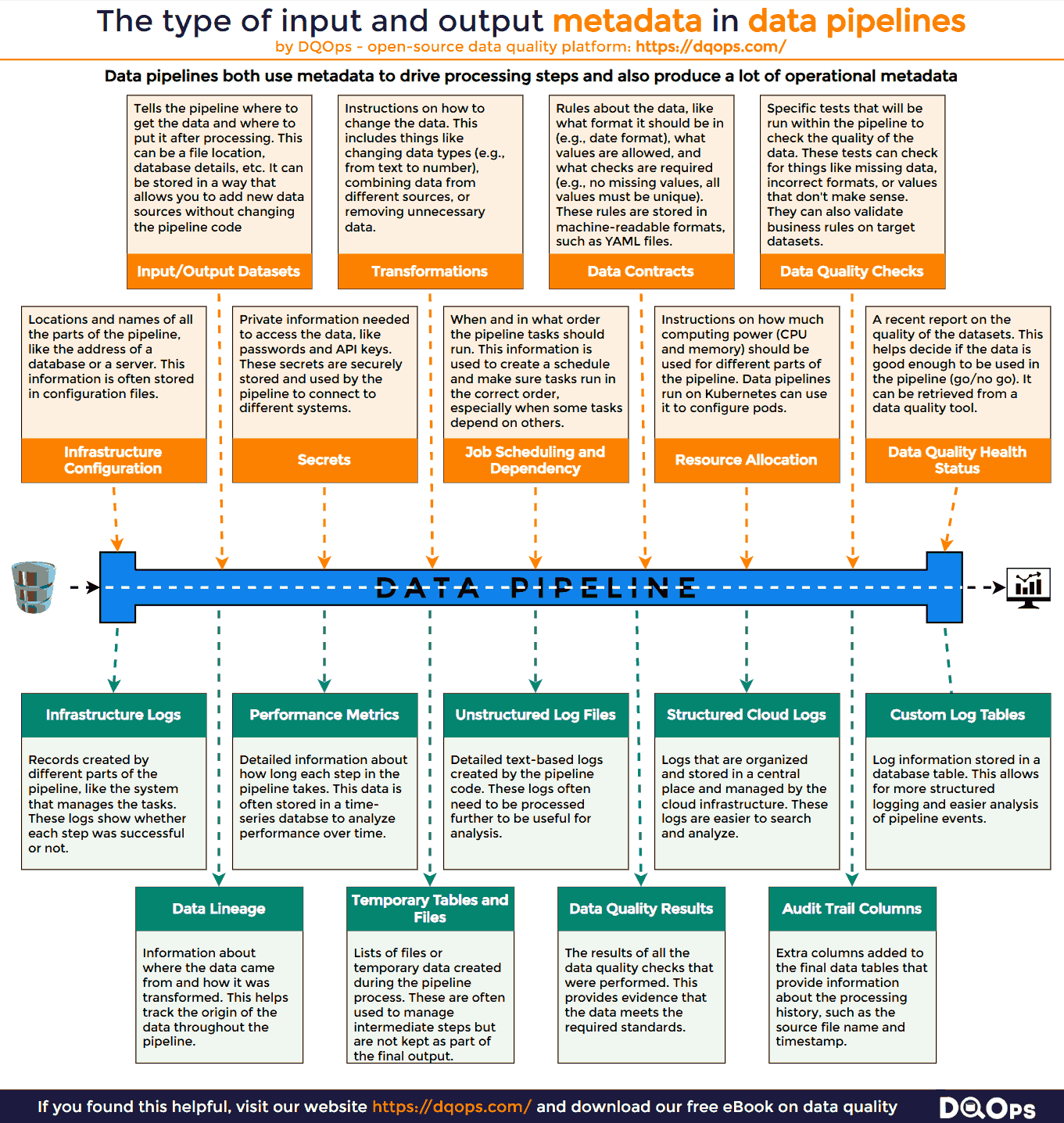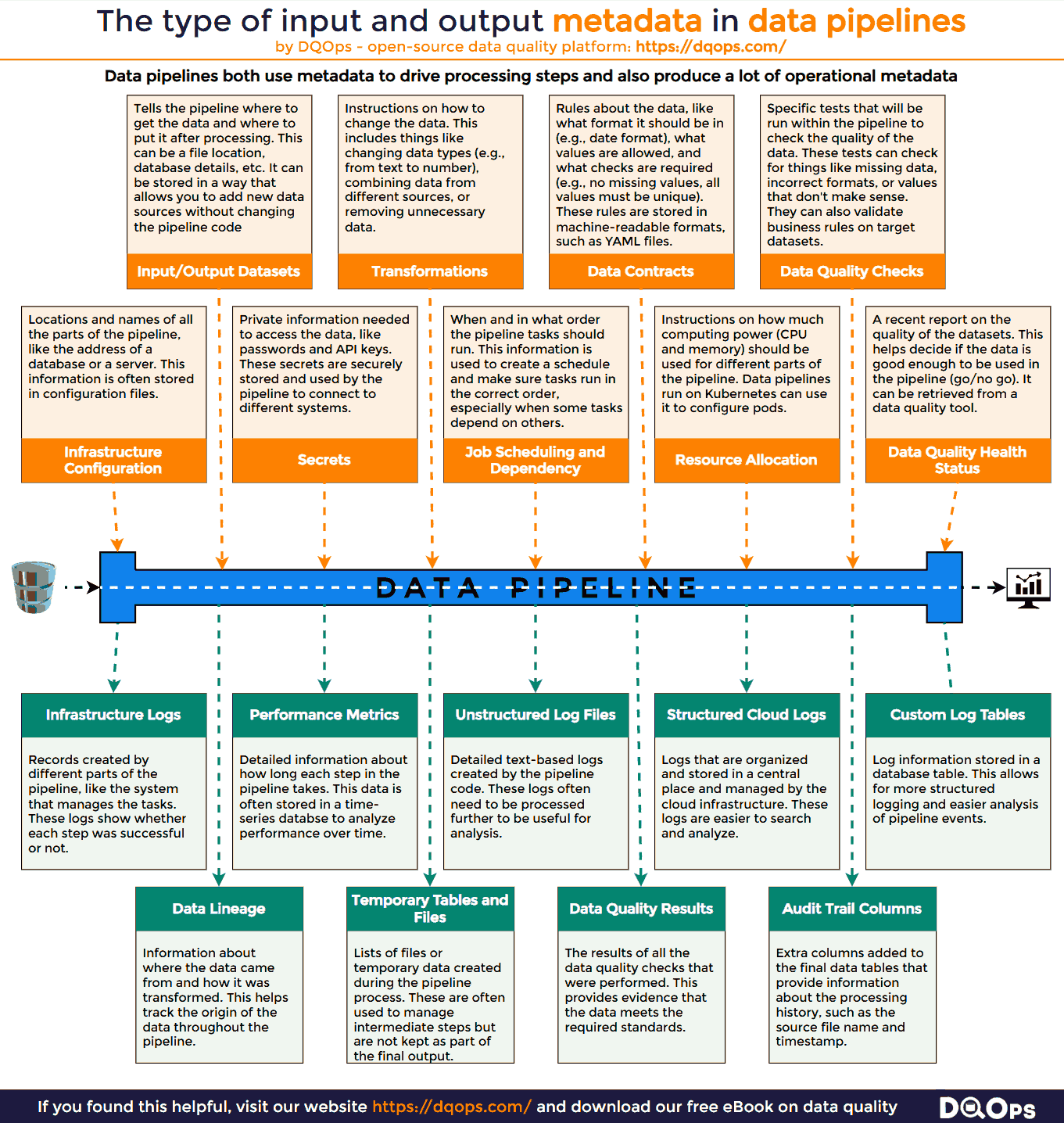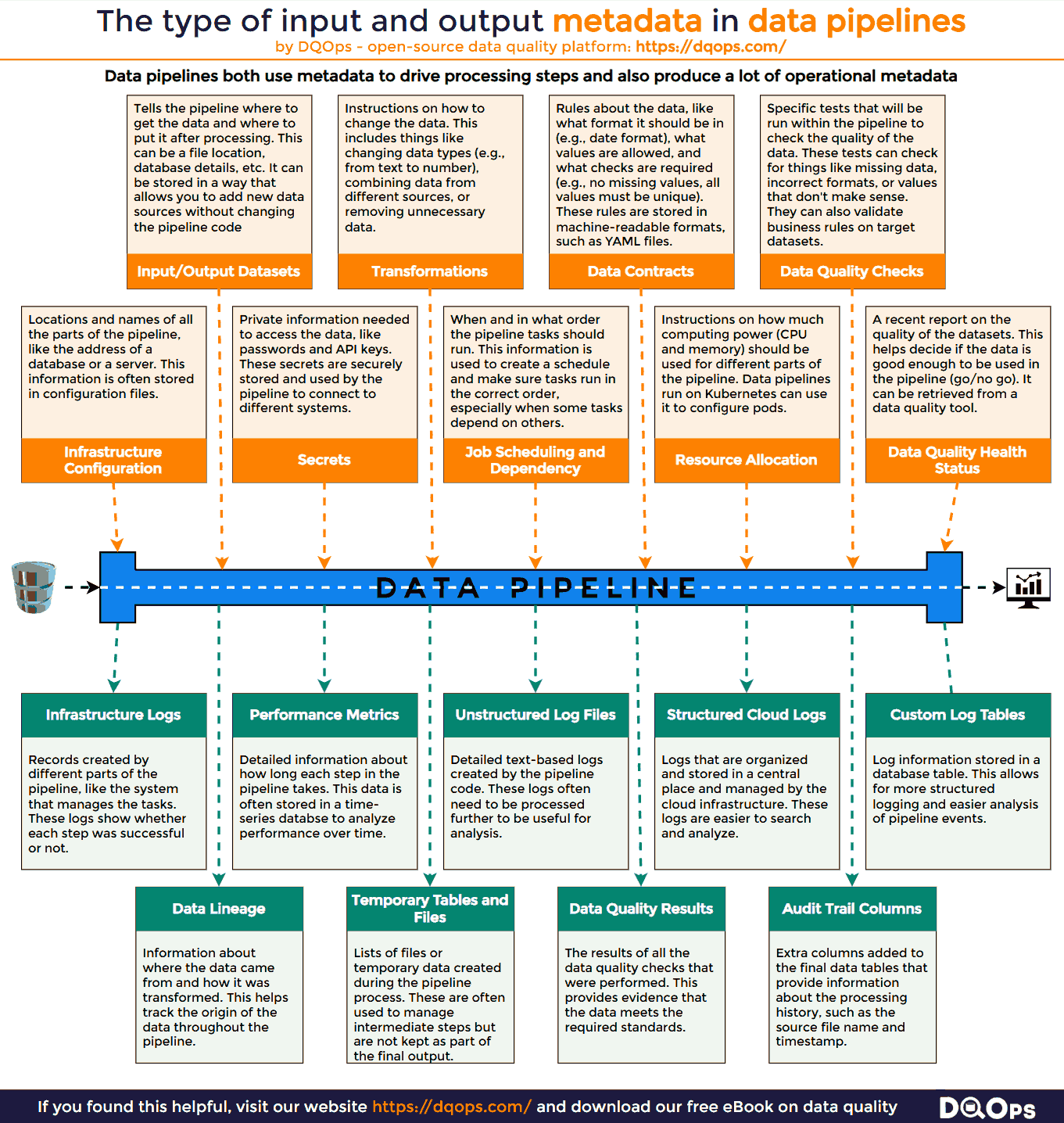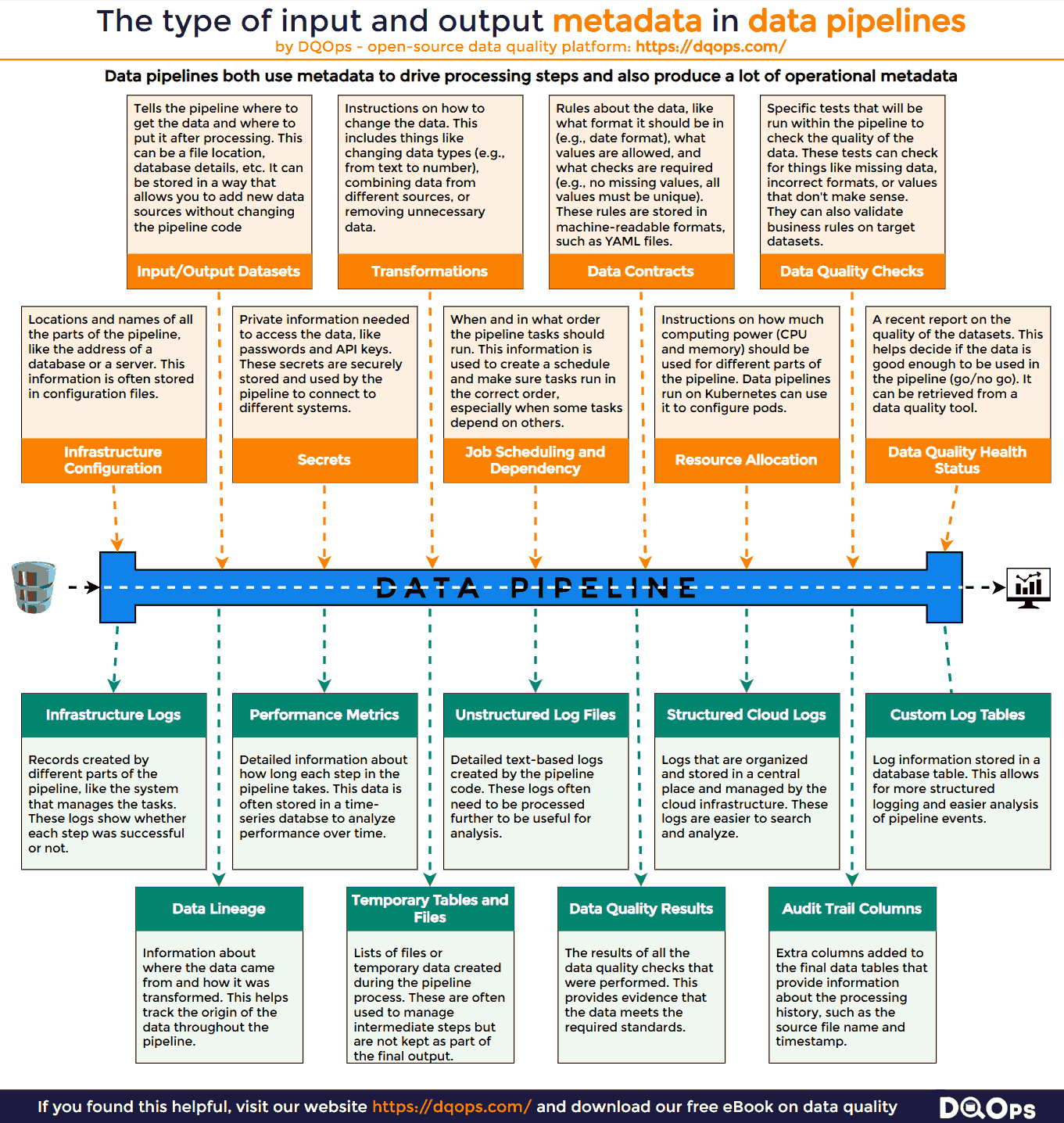
Configuring Automated ETL Data Pipelines
All ETL data pipelines, whether automated or manually coded, require configuration metadata. This metadata provides the instructions for the pipeline to connect to data sources, utilize necessary credentials, and manage computing resources.
Here are the key categories of configuration metadata:
- Infrastructure Configuration: Locations and names of all the parts of the data pipeline. This is like the address of a building where your data is processed. For example, this includes the address of a database used in the pipeline, or the server where a particular process runs.
- Secrets: Private information needed to access the data, like passwords and API keys. These credentials are securely stored and used by the pipeline to authenticate with various systems and access the required data.
- Job Scheduling and Dependency: When and in what order the pipeline tasks run. This ensures that tasks are executed in the correct sequence. For instance, extracting data from a source must occur before transforming and loading it into a target.
- Resource Allocation: How much computing power the pipeline needs. This includes the amount of memory and CPU required for each task. Proper resource allocation ensures that the pipeline runs efficiently and avoids overloading system resources.
- Data Quality Health Status: A report on the quality of the data before it’s used. This may include information about the completeness and accuracy of the data. This status helps determine if the data meets the minimum requirements for processing.
Metadata-Driven ETL Data Transformations
Automating ETL for a large number of similar tables requires a way to manage the processing logic externally. This is where metadata plays a crucial role. By extracting the list of tables and their processing details into a separate configuration, an automated ETL pipeline can efficiently handle numerous tables with consistent logic.
This approach allows for defining specific transformations for individual columns within those tables. For example, if a text column needs to be converted to a date or a number, this instruction can be included in the metadata.
Here are the key types of input metadata used for automating data transformations:
- Input/Output Datasets: Details about where the data comes from (the source) and where it goes (the target). This can include the names and locations of files or databases. This information is often stored separately so you can easily add new data sources without changing the whole pipeline.
- Transformations: Instructions on how to change the data during the process. This includes things like changing data types (e.g., from text to number), combining data from different columns, or filtering data based on certain conditions. This information is often kept separate from the main code to make it easier to update.
- Data Contracts: Rules about the data, like what format it should be in (e.g., date format), what values are allowed, and what checks are required (e.g., no missing values, all values must be unique). These rules are often written in a standard format that can be understood by both humans and computers.
- Data Quality Checks: Specific tests and checks that will be performed on the data within the pipeline. This includes checking for things like missing values, incorrect formats, and inconsistencies.
By utilizing these types of metadata, ETL pipelines can be highly automated and adaptable, capable of handling large volumes of data with varying structures and transformation requirements.
Where to Store Data Pipeline Metadata
Automated ETL pipelines offer flexibility in how you store the metadata that drives their operation. The choice of storage depends on factors like the complexity of your pipeline, the frequency of changes, and who needs to access and update the metadata.
Here are some common options:
- Within the ETL Tool: For simpler pipelines with a limited number of data sources, storing configuration details directly within the ETL tool itself can be convenient. This is often suitable when the data sources are well-defined and don’t change frequently.
- Version Control Systems: Using version control systems like Git to store metadata in files (e.g., JSON or YAML) provides a robust way to track changes, collaborate, and revert to previous versions if needed. This is particularly useful when data engineers need to manage and update the metadata regularly.Dedicated Configuration Database: For more complex scenarios, especially when non-engineers need to interact with the metadata, a dedicated configuration database offers a structured and accessible solution. This allows for easier management, querying, and updating of metadata through interfaces like custom web applications.
Ultimately, the best storage option for your metadata depends on your specific needs and preferences. Consider factors like ease of use, security, versioning, and accessibility when making your decision.
Why Automated ETL Data Pipelines Must be Monitored
While automated ETL pipelines offer significant advantages, they still require careful monitoring. Even though they can handle large and complex datasets, unexpected issues can arise during processing. Monitoring helps ensure that the pipeline operates smoothly and efficiently.
It’s important to understand that automation doesn’t make pipelines more prone to failures. In fact, automated pipelines can incorporate comprehensive monitoring steps between each processing stage, which is often impractical in manually designed pipelines.
Monitoring provides several key benefits:
- Early Issue Detection: By tracking the pipeline’s execution, you can identify potential problems early on, before they escalate into major disruptions.
- Performance Optimization: Monitoring helps pinpoint bottlenecks and areas where the pipeline’s performance can be improved.
- Data Quality Assurance: Monitoring allows you to track data quality metrics and ensure that the processed data meets your standards.
- Troubleshooting and Debugging: In case of failures, monitoring data provides valuable insights for troubleshooting and identifying the root cause of the problem.
Effective monitoring is essential for maximizing the benefits of automated ETL pipelines and ensuring the reliable delivery of high-quality data.
The Usage of Output Metadata
An ETL data pipeline produces various types of output metadata. It is mostly related to reporting the progress of data processing. However, automated data pipelines can generate additional intermediate metadata, such as files containing a list of tables to process.
The output metadata becomes crucial to achieve resilient ETL data pipelines. Another step in the data pipeline can look up the status of the previous processing steps in the log files or custom log tables. For example, when the ETL processing jobs for different layers are separated, the jobs that load data to data marts would be triggered even when the jobs that load data into the cleansing stage have failed. The ETL data pipeline that refreshes the data marts can look up the status of the previous stage in the log files (the output metadata).
Types of Output Metadata
ETL data pipelines produce a variety of metadata that provides valuable insights into their operation and performance. Here are the main types of output metadata:
- Data Infrastructure Logs: Records produced by different parts of the pipeline, like the system that manages the workflow. These logs show whether each step was successful or not, and any errors that occurred.
- Performance Metrics: Information about how long each step in the pipeline takes to run. This data is often stored in a way that makes it easy to track and analyze performance over time.
- Unstructured Log Files: Detailed logs written in a simple text format. These logs often need to be processed further to be analyzed.
- Structured Cloud Logs: Logs that are organized and stored in a central system. These logs are easier to search and analyze.
- Custom Log Tables: Logs that are written to specific database tables. This allows for more structured analysis and reporting.
- Data Lineage: Information that shows where the data came from and how it was changed at each step in the pipeline. This helps to track the origin of data and understand how it was transformed.
- Temporary Tables and Files: Lists of files or temporary data created during the pipeline process. These are often used to manage intermediate steps but are not kept as part of the final output.
- Audit Trail Columns: Extra columns added to the final data tables that provide information about the processing history, such as the source file name and timestamp.
Data Quality in Automated ETL Data Pipelines
Data quality is paramount for maintaining healthy automated ETL data pipelines. While the pipeline code and input metadata might remain stable over time, the incoming data itself can change constantly. Its schema, distribution, and format can all evolve, potentially impacting the pipeline’s effectiveness.
Automated ETL pipelines should continuously analyze the quality of both source and target data. This involves implementing data quality checks at various stages:
- Source Data Validation: Ideally, data quality checks should be executed directly on the source system. If this isn’t feasible, the pipeline can perform these checks on landing or staging tables before further processing.
- Target Data Validation: After data is loaded into target tables, its quality should be assessed. No-code data quality platforms can empower business users to define and manage these checks, ensuring alignment with business rules.
When data quality checks run, they provide valuable feedback:
- Acknowledgement Records: When checks pass, these records confirm the data’s validity and provide details about the check performed. This information is crucial for auditing and compliance.
- Failure Records: When checks fail, these records highlight the data quality issue and should trigger notifications to data owners for prompt resolution.
These data quality records, both acknowledgements and failures, are essential output metadata. They provide a comprehensive audit trail, support data quality KPI calculation, and enable efficient investigation of data quality issues. By prioritizing data quality and leveraging output metadata effectively, automated ETL pipelines can deliver reliable and trustworthy data for business use.

Data quality best practices - a step-by-step guide to improve data quality
- Learn the best practices in starting and scaling data quality
- Learn how to find and manage data quality issues
What is the DQOps Data Quality Operations Center
DQOps is a data observability platform designed to monitor data and assess the data quality trust score with data quality KPIs. DQOps provides extensive support for configuring data quality checks, applying configuration by data quality policies, detecting anomalies, and managing the data quality incident workflow.
DQOps is a platform that combines the functionality of a data quality platform to perform the data quality assessment of data assets. It is also a complete data observability platform that can monitor data and measure data quality metrics at table level to measure its health scores with data quality KPIs.
You can set up DQOps locally or in your on-premises environment to learn how DQOps can monitor data sources and ensure data quality within a data platform. Follow the DQOps documentation, go through the DQOps getting started guide to learn how to set up DQOps locally, and try it.
You may also be interested in our free eBook, “A step-by-step guide to improve data quality.” The eBook documents our proven process for managing data quality issues and ensuring a high level of data quality over time. This is a great resource to learn about data quality.




