
Data observability for data lake
Bring data governance to the data lake
Data lakes contain a large amount of information, but it can be difficult to ensure its quality. Traditional methods may not be able to uncover hidden issues that can contaminate your data, such as corrupted data partitions or inconsistencies in incoming files. These problems can significantly affect the reliability of your data and lead to misleading insights.
DQOps brings comprehensive data observability to data lake. It proactively identifies potential issues by detecting unhealthy partitions and data integrity risks. Additionally, DQOps validates the schema of incoming data to ensure smooth ingestion and prevent misaligned columns. By highlighting trusted data sources within your lake, DQOps helps data teams focus on reliable information, enabling confident data-driven decision-making.

Data observability
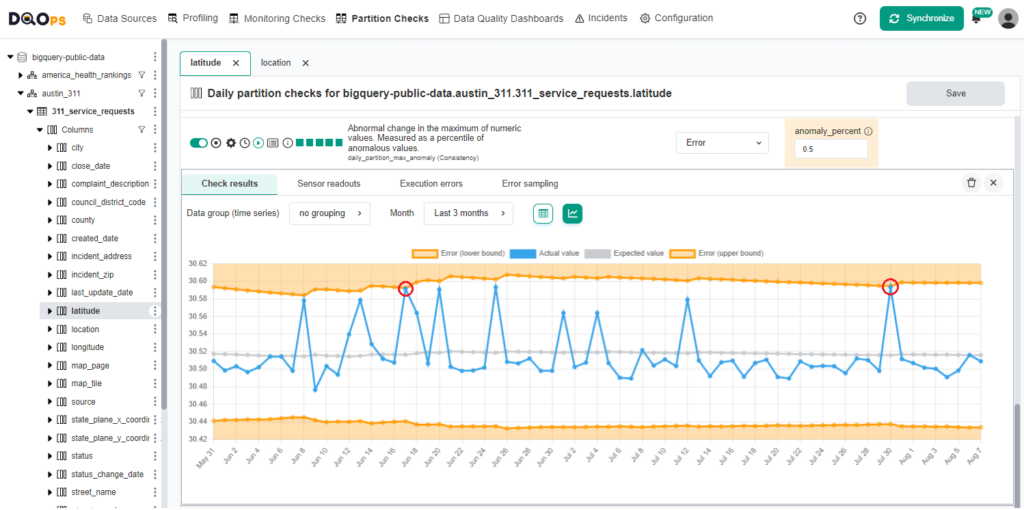
DQOps applies data observability by automatically activating data quality checks on monitored data sources. You can also monitor data quality in CSV, JSON, or Parquet files.
- Monitoring data ingestion, transformation, and storage processes.
- Detect anomalies, errors, or deviations from expected behavior.
- Proactively address potential issues before they escalate.
DQOps applies data observability by automatically activating data quality checks on monitored data sources. You can also monitor data quality in CSV, JSON, or Parquet files.
- Monitoring data ingestion, transformation, and storage processes.
- Detect anomalies, errors, or deviations from expected behavior.
- Proactively address potential issues before they escalate.
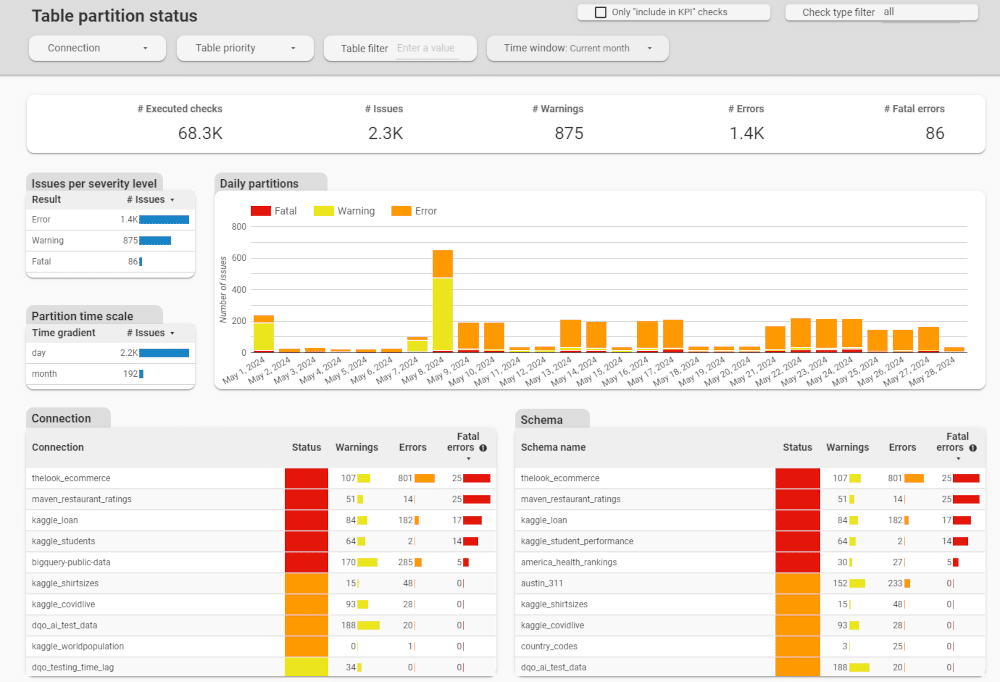
Unhealthy partition detection
Unhealthy partition detection
DQOps proactively identifies corrupted or unavailable partitions within your data lake, safeguarding the reliability of your data.
- Detect partitions that are unavailable due to corrupted Parquet files.
- Detect tables and partitions whose files are stored on offline or corrupted HDFS nodes.
- Identify unhealthy partitions and ensure your data lake remains a reliable source of insights.
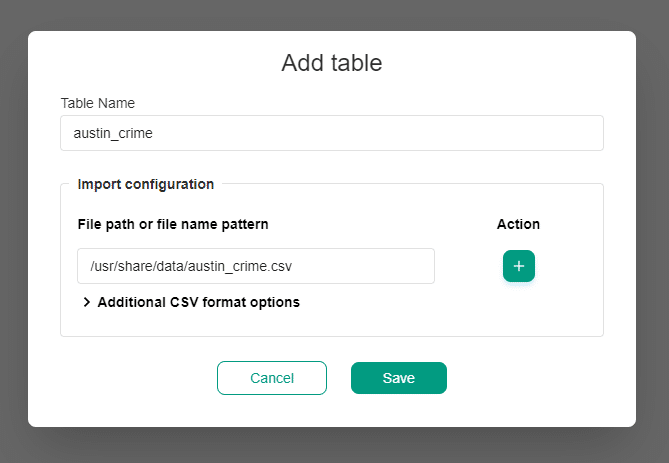
Seamless data ingestion
DQOps safeguards data integrity during the data ingestion process by validating incoming files against defined expectations.
- Detects missing columns in new files, preventing data from being loaded into incorrect locations.
- Analyzes average values to identify reversed or missing columns in CSV files, preventing data from being loaded incorrectly.
- Ensure that the external table always meets the data format and data range checks.
DQOps safeguards data integrity during the data ingestion process by validating incoming files against defined expectations.
- Detects missing columns in new files, preventing data from being loaded into incorrect locations.
- Analyzes average values to identify reversed or missing columns in CSV files, preventing data from being loaded incorrectly.
- Ensure that the external table always meets the data format and data range checks.
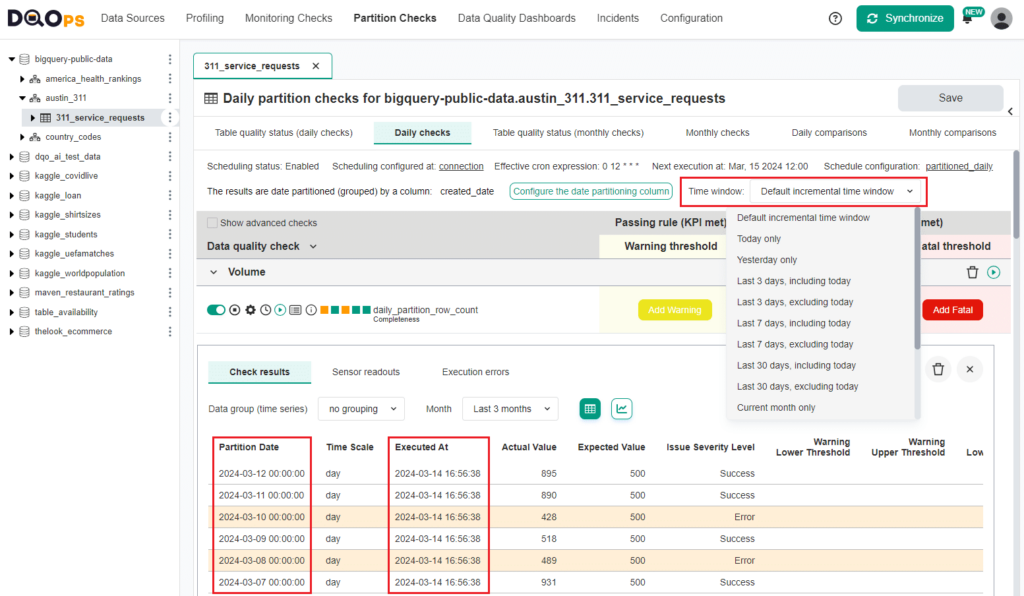
Data observability at petabyte scale
Data observability at petabyte scale
DQOps platform was designed to support analyzing the data quality of large tables. Special partitioned checks analyze data by grouping by a date column, enabling incremental analysis of only the most recent data
- Observe data quality at a petabyte scale.
- Analyze only new or modified data to avoid data lake pressure or high query processing costs.
- Configure the time window for the execution of partitioned checks.