Last updated: July 05, 2025
How to Configure Tables for Data Quality Monitoring? Examples
Read this guide to understand how DQOps stores the metadata of monitored tables and columns. Learn how to set the configuration for tables, such as filtering.
Overview
The configuration of every monitored table is stored in *.dqotable.yaml files. The table metadata configuration files are stored in the $DQO_USER_HOME/sources/{data_source_name}/ folder of the data source. The *.dqotable.yaml files are placed directly in the folder, not organized into folders by the database schema name.
Importing table metadata from the DQOps user interface
If you are not interested in the details of configuring data sources and you want to use the user interface, go back to the getting started section and read the import metadata using the user interface section.
Table metadata files
The location and schema of .dqotable.yaml files are described below.
.dqotable.yaml file names
The schema name and the table name are not stored in the .dqotable.yaml file. Instead, DQOps depends on file naming conventions.
The file name pattern for *.dqotable.yaml files is <schema_name>.<table_name>.dqotable.yaml. The table metadata files
are stored in the data source folder of the connection to the data source.
-
<schema_name>part is the database schema name. For databases that group tables by a different object, it is: -
<table_name>part stores the table name
An example of a DQOps user home folder with two tables in the prod-landing-zone connection is shown below.
$DQO_USER_HOME
├───...
└───sources
├───prod-landing-zone
│ ├───connection.dqoconnection.yaml
│ ├───public.fact_sales.dqotable.yaml
│ ├───public.dim_date.dqotable.yaml
│ └───...
└─...
Table YAML file structure
The following .dqotable.yaml file below shows the structure of a table metadata configuration file.
- The type of the file is identified in the
kindelement. - The
spectable specification object that describes the table, its columns and activated data quality checks. - The configuration of timestamp columns that are used for timeliness checks such as freshness, and for running partition checks.
- The column name (date in this example) contains an event timestamp that is used to measure timeliness.
- The column name (date in this example) that will be used in GROUP BY queries to measure the data quality at a partition level. The table does not need to be partition by this column physically. DQOps uses this column to detect data quality issues within time ranges.
- The configuration of the date, datetime, or timestamp columns that are used in timeliness checks and in the GROUP BY clauses in date partition checks.
- The number of recent days used to analyze the data incrementally in daily partition checks.
- The number of recent months used to analyze the data incrementally in monthly partition checks. 1 means that the previous month is analyzed only.
- The node with a list of columns.
- One example column name. The column-level checks for this column are defined inside the node.
The main nodes found created by default in the .dqotable.yaml file when a table is imported into DQOps are listed below.
-
timestamp_columnsnode stores the names of date, datetime or timestamp columns that are used for timeliness and freshness checks, and to configure the date column used for partition checks. -
incremental_time_windownode configures the time window for running partition checks for the most recent data, to enable incremental data quality monitoring -
columnsis a dictionary of columns, storing the columns' metadata, indexed by the column name.
Table YAML core elements
The core elements found on the .dqotable.yaml file are described in the table below.
Please expand this section to see the description of all .dqotable.yaml file nodes
| Line | Element path | Description | Default value |
|---|---|---|---|
| 2 | apiVersion |
The version of the DQOps file format | dqo/v1 |
| 3 | kind |
The file type | table |
| 4 | spec |
The main content of the file, contains the table specification. | |
| 5 | spec.timestamp_columns |
The configuration of timestamp columns that are used for timeliness checks such as freshness, and for running partition checks. | |
| 6 | spec.timestamp_columns. event_timestamp_column |
The column name (date in this example) that contains an event timestamp that is used to measure timeliness. It should be a column that identifies the event or transaction timestamp. | |
| 7 | spec.timestamp_columns. partition_by_column |
The column name (date in this example) that will be used in partition checks to detect data quality issues at a date partition or for each daily or monthly time period. It can be a date, datetime or a timestamp column name. | |
| 8 | spec.incremental_time_window |
The configuration for the recent time window used to run partition data quality checks incrementally. | |
| 9 | spec.incremental_time_window. daily_partitioning_recent_days |
The number of recent days used to analyze the data incrementally in daily partition checks. | 7 |
| 10 | spec.incremental_time_window. monthly_partitioning_recent_months |
The number of recent months used to analyze the data incrementally in monthly partition checks. 1 means that the previous month is analyzed only. | 1 |
| 11 | spec.columns |
A node that contains an array of columns for which the data quality checks are configured. | |
| 12 | spec.columns.<first_column_name> |
An example column named first_column_name. The column level data quality checks for this column are configured inside this node. |
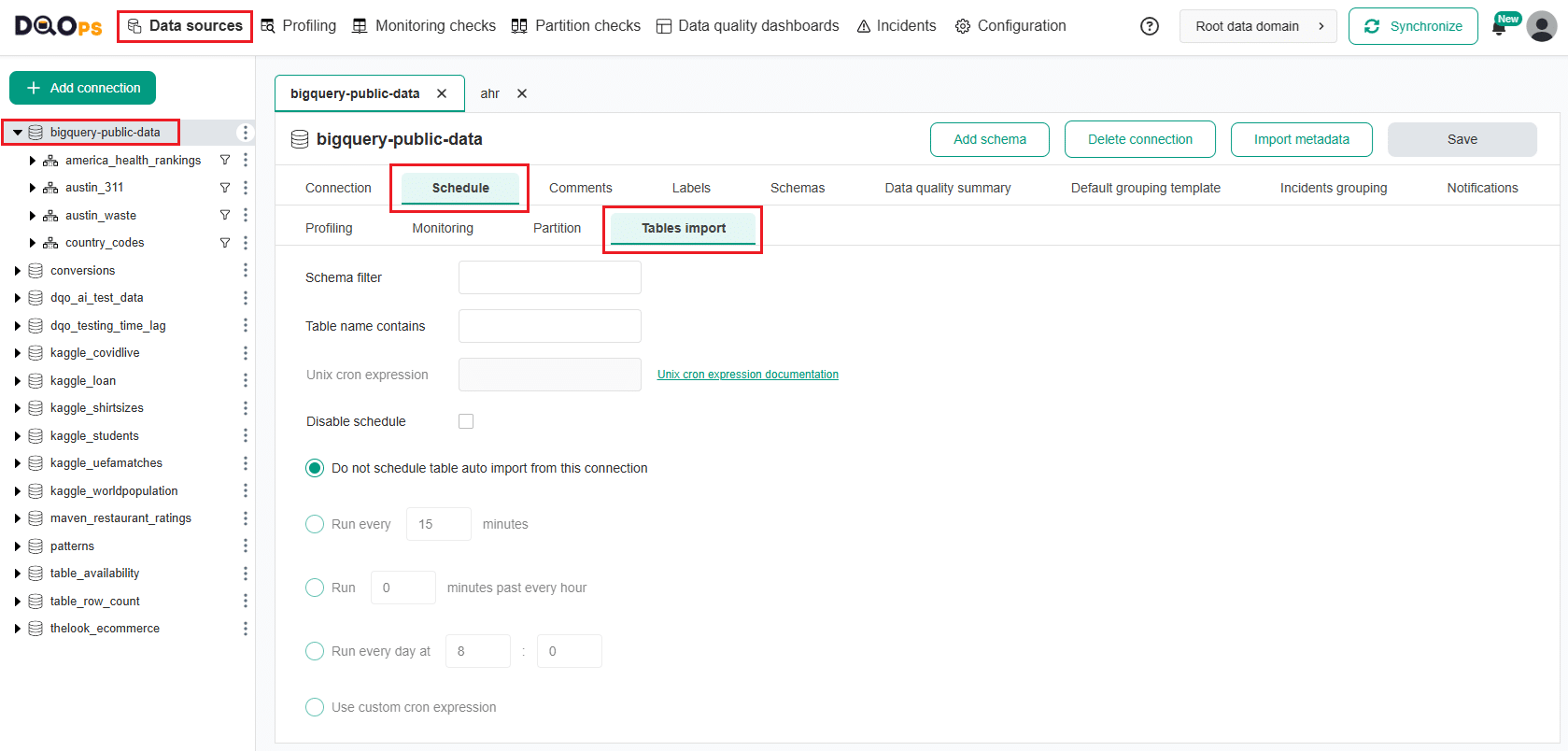
Table auto import configration
You can configure automatic synchronization of metadata to keep your data fresh and up to date.
Follow the link to learn how to set up or modify automatic table import schedule.
Configuring columns
The list of columns is stored in the spec.columns node in the .dqotable.yaml file.
The spec.columns node is a dictionary of column specifications,
the keys are the column names.
Columns are added to the .dqotable.yaml when the table's metadata is imported into DQOps.
Column schema
The following example shows a .dqotable.yaml file with two columns named cumulative_confirmed and date.
- The column dictionary node. The nodes below it are the column names.
- The configuration and captured metadata of the first column cumulative_confirmed.
- Data type snapshot contains the last imported physical data type of the column. DQOps uses these data types to decide if certain data type specific data quality checks can be activated on a column.
- The data type of the column, it is a physical data type introspected from the monitored table.
The node for each column contains a type snapshot object that is used by DQOps in the following cases:
-
The default data quality checks are activated depending on the column's data type. Numeric anomaly checks are activated only on numeric columns such as the cumulative_confirmed column in the example above.
-
The data quality sensors may use the column's data type to decide if an additional type casting must be generated in the SQL query that will capture the metrics for the data quality check.
DQOps does not require that each column has the type_snapshot node defined. All the data quality checks will work
without knowing the column's data type. The type_snapshot.column_type field can be used to find columns by
the data type when activating multiple data quality checks
using the `dqo check activate command-line command, or
using the bulk check editor screen.
Calculated columns
DQOps goes beyond monitoring columns that are already present in the table. Quite often, the values that will be monitored must be first extracted from complex text columns.
Let's take an example of a table that contains just one column, named message. Each message column stores a single line of a HL7 message.
We want to analyze a table that contains HL7 messages, verifying that the trigger event type is one of the accepted values, 'A01' and 'A02' in this example.
Calculated columns are defined in the .dqotable.yaml file and also in the spec.columns section.
The column name becomes a virtual column name. Data quality checks may be applied to this virtual column.
The following example shows an event_type_code virtual column that extracts the second element from
the message lines that are the 'EVN' event messages.
- The message column that contains one line of a HL7 message.
- The name of the virtual (calculated) column that was created.
- The data type of the calculated column. It is not required to configure it, but the data quality checks may use it as a hint to avoid additional type casting.
- The SQL expression using the SQL grammar of the monitored data source that extracts the value of a calculated column.
The
{alias}.messageexpression references the message column from the monitored source. DQOps will replace the{alias}token with the table alias used in the SQL query that is generated from the sensor's template. - We are validating that the column contains a 'A01' value.
The calculated column is defined using the SQL grammar of the monitored data source.
The sql_expression field must contain an SQL expression that extracts the value of a calculated column.
The {alias}.message expression references the message column from the monitored source. DQOps will replace the {alias}
token with the table alias used in the SQL query that is generated from the sensor's template.
This example also shows that the type_snapshot.column_type value is set to a result data type of the expression.
Setting the data type is not required to run checks, but DQOps may use it as a hint to avoid additional type casting.
Transforming column values
The tables found in the data landing zones are often CSV files with all columns defined as a character data type. These columns must be cast into the correct data type before they can be used to perform some kind of data transformation.
Let's assume that the monitored table is an external table, backed by the following CSV file.
The date column contains a text value that is a valid ISO 8601 date. We want to replace all usages of the column reference with an SQL expression that will cast the column's value to a DATE.
When the date column is cast to a DATE type, we can use it as a partitioning column for partition checks or run date-specific data quality checks such as the daily-date-values-in-future-percent check that detects if any dates are in the future.
The next example shows how to apply additional transformations such as typecasting on a column that is present in the table.
- A column that is already present in the table, but we want to apply a transformation.
- The new data type that is the result of the SQL expression.
- An SQL expression that is applied on the column. DQOps will use this expression to access the column
instead of using the raw column value. The SQL expression uses a token
{alias}.{column}to reference the raw value of the overwritten column.
The sql_expression parameter is an SQL expression that uses a token {alias}.{column} to reference the
raw value of the overwritten column.
Additional table configuration
The following examples show how to apply additional configuration on a table level.
Table owner
Store the name of the data owner, for reference and informative purposes.
Table filter predicate
DQOps analyzes all rows in a table. This behavior is not always desired.
In order to analyze only a subset of rows, a filter predicate that is added to the WHERE SQL clause
should be defined. The filter predicate may use an {alias}. token to reference the analyzed table.
The {alias} is replaced with the table alias that is used in the query.
Almost all data quality sensors in DQOps use analyzed_table as the name of the alias, but some more complex
sensors that need to apply joins and other SQL clauses may use a different alias.
The following example shows a table alias that will analyze the data only after 2023-11-06.
- The table filter using a token
{alias}that is replaced with the real table alias that is used in the SQL query.
Table stage
The tables can be grouped into different stages, which is helpful in identifying data quality issues at various stages, such as landing zones, staging, cleansing, data marts, or other stage names specific to the environment. By breaking down the tables into different stages, it becomes easier to calculate the data quality KPIs for each stage.
It is worth noting that DQOps does not enforce any naming convention for the different stages. Instead, the stages are simply free-form string values that are assigned to a table in the .dqotable.yaml file.
The value of the stage field that was configured on the table at the time of running the check is saved in the
sensor_readouts and the
check_results parquet tables.
The data quality dashboards in DQOps are designed
to allow filtering by the stage, using the stage value from the tables mentioned above.
The following example shows how the stage field is configured.
Table priority
The table priority is a concept practiced by DQOps data quality engineers when conducting data quality projects in an agile way.
The principle of agile software development is dividing the workload into iterations. The agile principles are realized in DQOps by assigning numerical priorities to all tables that are initially imported at the beginning of a data quality project.
When the tables are assigned to priorities (1, 2, 3, ...), an agile data quality project should focus on improving the
data quality of the priority 1 tables first. When a satisfactory level of data quality, measured using
the data quality KPIs is achieved, the tables from the next priority
level are assigned to be improved in the next iteration.
The value of the priority field that was configured on the table at the time of running the check is saved in the
sensor_readouts and the
check_results parquet tables.
The data quality dashboards in DQOps use a filter for the table priorities,
allowing to separate data quality issues between high-priority tables that should be already cleansed and lower-priority tables
that are still in the data cleansing process.
The following example shows how the priority field is configured.
- The priority 1 is the highest priority.
The DQOps team has written a free eBook Best practices for effective data quality improvement that describes the iterative data quality process based on table priorities in details. Please download the eBook to learn more about the concept.
Iterative data quality cleansing projects
The application of table prioritization for improving the data quality in iterations is described in the data quality improvement process section of the data quality KPIs article. Using priorities enables a quick return of investment for data quality projects.
Custom scheduling
DQOps runs all data quality checks configured on all tables in a data source using the CRON schedule.
It is also possible to configure a custom schedule for a table.
Or exclude scheduling certain types of data quality checks.
Labels
Tables and columns can be tagged with labels. The labels are used by DQOps for targeting data quality checks when the checks are run.
Labels are defined in a labels section below the spec node (for a table-level label)
or below the column's node for column-level labels. The labels are defined as a list of string values.
The following example shows how to assign one label on a table level and two labels on a column level.
Comments
You can also track comments about tables. This feature becomes important if multiple users are maintaining data quality checks.
Comments are also supported for columns.
What's next
- Learn how to set up connections to data sources in DQOps.
- If you want to see how to import the metadata of data sources using the DQOps user interface, go back to the getting started section, and read the adding data source connection again.
- Learn how to configure data quality checks and rules in the .dqotable.yaml files.
- Learn more about managing configuration in the
DQOps user homefolder. - Review the list of data sources supported by DQOps to find a step-by-step configuration manual for each data source.
- Learn what extensions are needed to activate editing DQOps configuration files in Visual Studio Code with code completion and validation.