Last updated: July 22, 2025
How to detect data quality issues with custom SQL expressions
Read this guide to learn how to use custom SQL expressions in data quality checks, assert custom conditions, and evaluate multi-column expressions.
The data quality checks that support custom SQL expressions are configured in the custom_sql category in DQOps.
Using custom SQL expressions
Data quality checks using custom SQL expressions are a quick method to run custom data quality checks without defining a reusable (custom) check. It is a fast way to evaluate a unique rule needed to validate one or a few columns in the database.
Ad-hoc SQL checks are helpful in several use cases.
-
Assert custom conditions that need a custom SQL expression.
-
Evaluate complex conditions.
-
Evaluate conditions across multiple columns.
-
Import data quality results stored in custom tables.
Evaluate a custom condition
We can use a custom SQL expression to assert a condition on a column or a table. The following example detects one type of data quality problem that we noticed in the city column in the 311 Austin municipal services call history table. Data profiling results indicate that the city names are inconsistently written in both lower and upper case.
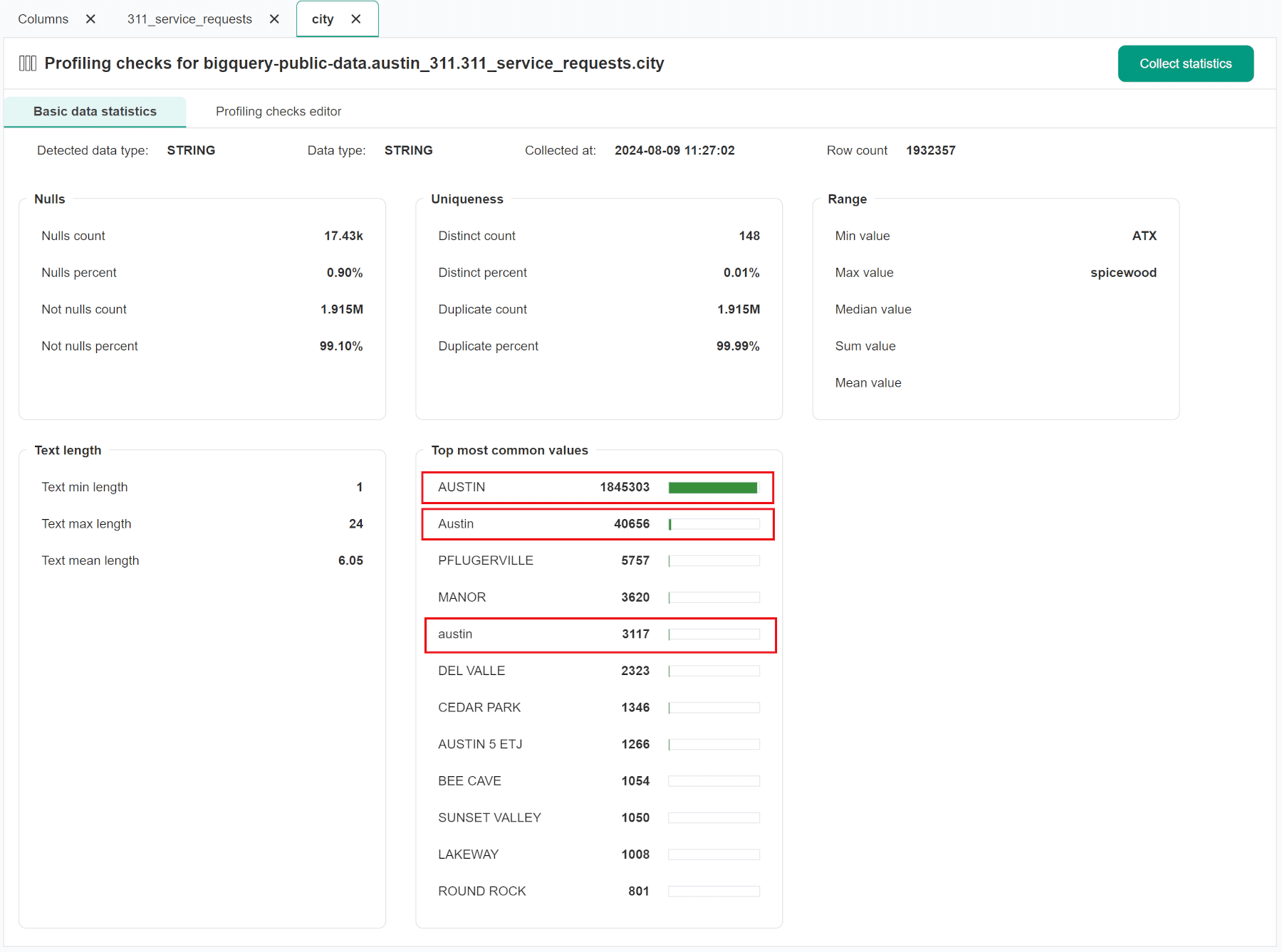
An upper case variant "AUSTIN" is dominant. We want to detect invalid names that are written in lowercase.
The SQL expression valid (uppercase) values must pass is city IS NULL OR city = UPPER(city).
SQL expression formats
DQOps supports several forms of SQL expressions, with or without replacement tokens.
The shortest and most resilient format of the SQL expression defined on a column references
the tested column by a {column} token.
DQOps replaces the {column} token with an adequately quoted column name,
allowing the use of column names containing whitespace and special characters.
The next format of SQL expression uses an {alias} token to reference the tested table.
This format supports any column name, but the user must ensure that column names are quoted if necessary.
The last and most compact format uses the column name without using an alias to reference the tested table. This format of SQL expression may lead to errors in the SQL queries generated by DQOps for some database engines. SQL queries that use joins will have issues finding the right table with that column.
If you face issues with running data quality checks not using replacement tokens, please rewrite the SQL condition to use tokens.
Activating failed check in UI
The sql_condition_failed_on_column
and sql_condition_failed_on_table
data quality checks assert that all rows pass the condition.
We want to accept a maximum number of rows that fail the condition by setting the max_count parameter.
The example of running the check on the 311_service_requests table found 45 059 rows that are not uppercase.

Activating failed check in YAML
The sql_condition_failed_on_column
data quality check is straightforward to configure in YAML.
Activating percent check in UI
An alternative method of asserting SQL conditions measures the percentage of rows that pass the condition. It is usable on tables with data quality issues that are impossible to fix, mainly affecting old records.
The sql_condition_passed_percent_on_column
and sql_condition_passed_percent_on_table
data quality checks measure the percentage of rows passing the SQL condition.
The percentage is compared to a minimum accepted percentage by a data quality rule. These data quality checks are
categorized as non-standard checks. To display non-standard checks, select the Show advanced checks checkbox at the top left of the Check editor table.

Activating percent check in YAML
The sql_condition_passed_percent_on_column
data quality check is straightforward to configure in YAML.
The rule parameter is min_percent.
Compare columns
The sql_condition_failed_on_column and
sql_condition_passed_percent_on_column checks
can detect data quality issues affecting multiple columns.
The SQL expression must reference both the current column that is validated and other columns in the same table.
The following example detects if any row has a value in the created_date column after the last_update_date. We expect that 100% of rows have proper dates.
The SQL condition that detects creation dates before the update date must ensure that the row has an updated timestamp by checking if the last_update_date column is not null.
Activate compare check in UI
The following example uses the
sql_condition_passed_percent_on_column
daily monitoring data quality check.

Compare checks error sampling in UI
To assist with identifying the root cause of errors and cleaning up the data, DQOps offers error sampling for this check. You can view representative examples of data that do not meet the specified data quality criteria by clicking on the Error sampling tab in the results section.

For additional information about error sampling, please refer to the Data Quality Error Sampling documentation.
Activate compare check in YAML
The following example uses the
sql_condition_passed_percent_on_column
data quality check.
Aggregate a transformed value
DQOps can calculate custom SQL aggregate expressions, such as SUM, MIN, or AVG.
Using a custom SQL expression to calculate aggregate expressions is necessary when:
-
The column needs additional type casting because the data type of the column is not numeric.
-
A CASE expression is used inside an aggregate function to convert values.
The sql_aggregate_expression_on_column
and sql_aggregate_expression_on_table
data quality checks compute an aggregate value.
DQOps validates the aggregate measure with a data quality rule that verifies if the value
is within a range between the from and to values.
Activating aggregate check in UI
The sql_aggregate_expression_on_column
data quality check is an advanced check.
Please turn on advanced checks to see it in the check editor.
The following example shows running the check on the state_plane_x_coordinate column,
which is a text column and needs casting to a float value. The aggregate expression is AVG(SAFE_CAST({column} as FLOAT64)).

Activating aggregate check in YAML
The sql_aggregate_expression_on_column
data quality check is straightforward to configure in YAML.
Import external data quality results
Many data engineering teams apply data quality checks in the data pipeline code. Because the data loading code can create tables and insert rows into tables, storing data quality results in a custom log table becomes an obvious choice. These tables are usually created in the target database. At DQOps, we call them the data engineering quality checks. Usually, the log tables are used only for error investigation or auditing. The reporting from these tables is limited only to showing core metrics on dashboards, or there are no data quality dashboards.
Another limitation of the data engineering quality checks appears when a non-coding data quality engineer joins the team. Additional data quality checks will be enabled in DQOps, but the results of the data engineering quality checks must be imported into the data quality data warehouse.
DQOps comes with a solution for importing the results of data quality checks that were
executed using other data quality libraries or platforms.
The results can be imported by using an import_custom_result_on_table
and import_custom_result_on_column data quality checks.
It is a templated SQL query that pulls a result from a dedicated logging table.
Example log table
Let's assume the data engineering team created a table data_pipeline_checks_log. After loading a target table, the data pipeline performs custom-built data quality checks. The results of these checks are inserted into the log table. Each row identifies the target table, the timestamp when the check was run, and the data quality issue severity level for identified issues.
| executed_at | schema_name | table_name | column_name | check_name | check_metric | status |
|---|---|---|---|---|---|---|
| 2024-02-03 21:21:47 | sales_dwh | fact_sales | row_count | 12452342 | passed | |
| 2024-02-03 21:21:47 | sales_dwh | fact_sales | product_id | null_count | 0 | passed |
| 2024-02-03 21:21:48 | sales_dwh | fact_sales | category_id | null_count | 0 | passed |
The following query will pull the most recent result of the null_count check from the log table.
-
A numerical metric that is imported into DQOps as an
actual_value. DQOps will draw the value on the chart. -
An optional metric that is imported into DQOps as an
expected_value. DQOps will draw the value on the chart. -
A data quality issue severity status. The values are: 0 - valid, 1 - warning, 2 - error, 3 - fatal.
-
Filter the results by the schema name, table name, column name.
-
Find the most recent log entry.
-
Search for today's log entries to avoid loading the same results again.
Replacement tokens
The import_custom_result_on_table and
import_custom_result_on_column checks
support the following replacement tokens.
| Token | Description |
|---|---|
{schema_name} |
The schema name. |
{table_name} |
The name of the table on which the check is enabled. |
{column_name} |
An optional name of the column on which the check is enabled. |
Configure table-level check in YAML
The example of a import_custom_result_on_table data quality check
configuration is shown below.
# yaml-language-server: $schema=https://cloud.dqops.com/dqo-yaml-schema/TableYaml-schema.json
apiVersion: dqo/v1
kind: table
spec:
monitoring_checks:
daily:
custom_sql:
daily_import_custom_result_on_table:
parameters:
sql_query: |-
SELECT
logs.check_metric AS actual_value,
0 AS expected_value,
CASE
WHEN logs.status = 'passed' THEN 0
WHEN logs.status = 'failed' THEN 2
ELSE 3
END AS severity
FROM data_pipeline_checks_log as logs
WHERE logs.schema_name = '{schema_name}' AND
logs.table_name = '{table_name}' AND
logs.check_name = 'row_count'
log.executed_at = (
SELECT MAX(max_entry.executed_at)
FROM data_pipeline_checks_log as max_entry
WHERE max_entry.schema_name = '{schema_name}' AND
max_entry.table_name = '{table_name}' AND
max_entry.check_name = 'row_count' AND
max_entry.executed_at >= TODAY()
)
warning: {}
error: {}
fatal: {}
The data quality rules for the warning, error, and fatal severity rules are responsible for importing only data quality issues at the specified severity level.
If you don't want to import issues at a given severity level, remove the configuration of the rule for that level.
Configure column-level check in YAML
The example of a import_custom_result_on_column data quality check
configuration is shown below.
# yaml-language-server: $schema=https://cloud.dqops.com/dqo-yaml-schema/TableYaml-schema.json
apiVersion: dqo/v1
kind: table
spec:
columns:
city:
monitoring_checks:
daily:
custom_sql:
daily_import_custom_result_on_column:
parameters:
sql_query: |-
SELECT
logs.check_metric AS actual_value,
0 AS expected_value,
CASE
WHEN logs.status = 'passed' THEN 0
WHEN logs.status = 'failed' THEN 2
ELSE 3
END AS severity
FROM data_pipeline_checks_log as logs
WHERE logs.schema_name = '{schema_name}' AND
logs.table_name = '{table_name}' AND
logs.column_name = '{column_name}' AND
logs.check_name = 'null_count'
log.executed_at = (
SELECT MAX(max_entry.executed_at)
FROM data_pipeline_checks_log as max_entry
WHERE max_entry.schema_name = '{schema_name}' AND
max_entry.table_name = '{table_name}' AND
max_entry.column_name = '{column_name}' AND
max_entry.check_name = 'null_count' AND
max_entry.executed_at >= TODAY()
)
warning: {}
error: {}
fatal: {}
Use cases
| Name of the example | Description |
|---|---|
| Percentage of rows passing SQL condition | This example shows how to detect that the percentage of passed sql condition in a column does not fall below a set threshold using sql_condition_passed_percent check. |
List of custom sql checks at a table level
| Data quality check name | Friendly name | Data quality dimension | Description | Standard check |
|---|---|---|---|---|
| sql_condition_failed_on_table | Maximum count of rows that failed SQL conditions | Validity | A table-level check that uses a custom SQL expression on each row to verify (assert) that all rows pass a custom condition defined as an SQL condition. Use the {alias} token to reference the tested table. This data quality check can be used to compare columns on the same table. For example, the condition can verify that the value in the col_price column is higher than the col_tax column using an SQL expression: `{alias}.col_price > {alias}.col_tax`. Use an SQL expression that returns a true value for valid values and a false one for invalid values, because it is an assertion. | |
| sql_condition_passed_percent_on_table | Minimum percentage of rows that passed SQL condition | Validity | A table-level check that ensures that a minimum percentage of rows passed a custom SQL condition (expression). Measures the percentage of rows passing the condition. Raises a data quality issue when the percent of valid rows is below the min_percent parameter. | |
| sql_aggregate_expression_on_table | Custom aggregated SQL expression within range | Reasonableness | A table-level check that calculates a given SQL aggregate expression on a table and verifies if the value is within a range of accepted values. | |
| sql_invalid_record_count_on_table | Custom SELECT SQL that returns invalid records | Validity | A table-level check that uses a custom SQL query that return invalid values from column. Use the {table} token to reference the tested table. This data quality check can be used to compare columns on the same table. For example, when this check is applied on a age column, the condition can find invalid records in which the age is lower than 18 using an SQL query: `SELECT age FROM {table} WHERE age < 18`. | |
| import_custom_result_on_table | Import custom data quality results on table | Validity | A table-level check that uses a custom SQL SELECT statement to retrieve a result of running a custom data quality check that was hardcoded in the data pipeline, and the result was stored in a separate table. The SQL query that is configured in this external data quality results importer must be a complete SELECT statement that queries a dedicated table (created by the data engineers) that stores the results of custom data quality checks. The SQL query must return a severity column with values: 0 - data quality check passed, 1 - warning issue, 2 - error severity issue, 3 - fatal severity issue. |
Reference and samples
The full list of all data quality checks in this category is located in the table/custom_sql reference. The reference section provides YAML code samples that are ready to copy-paste to the .dqotable.yaml files, the parameters reference, and samples of data source specific SQL queries generated by data quality sensors that are used by those checks.
List of custom sql checks at a column level
| Data quality check name | Friendly name | Data quality dimension | Description | Standard check |
|---|---|---|---|---|
| sql_condition_failed_on_column | Maximum count of rows that failed SQL conditions | Validity | A column-level check that uses a custom SQL expression on each column to verify (assert) that all rows pass a custom condition defined as an SQL expression. Use the {alias} token to reference the tested table, and the {column} to reference the column that is tested. This data quality check can be used to compare columns on the same table. For example, when this check is applied on a col_price column, the condition can verify that the col_price is higher than the col_tax using an SQL expression: `{alias}.{column} > {alias}.col_tax` Use an SQL expression that returns a true value for valid values and false for invalid values, because it is an assertion. | |
| sql_condition_passed_percent_on_column | Minimum percentage of rows that passed SQL condition | Validity | A table-level check that ensures that a minimum percentage of rows passed a custom SQL condition (expression). Measures the percentage of rows passing the condition. Raises a data quality issue when the percent of valid rows is below the min_percent parameter. | |
| sql_aggregate_expression_on_column | Custom aggregated SQL expression within range | Reasonableness | A column-level check that calculates a given SQL aggregate expression on a column and verifies if the value is within a range of accepted values. | |
| sql_invalid_value_count_on_column | Custom SELECT SQL that returns invalid values | Validity | A column-level check that uses a custom SQL query that return invalid values from column. This check is used for setting testing queries or ready queries used by users in their own systems (legacy SQL queries). Use the {table} token to reference the tested table, and the {column} to reference the column that is tested. For example, when this check is applied on a column. The condition can find invalid values in the column which have values lower than 18 using an SQL query: `SELECT {column} FROM {table} WHERE {column} < 18`. | |
| import_custom_result_on_column | Import custom data quality results on column | Validity | Column level check that uses a custom SQL SELECT statement to retrieve a result of running a custom data quality check on a column by a custom data quality check, hardcoded in the data pipeline. The result is retrieved by querying a separate logging table, whose schema is not fixed. The logging table should have columns that identify a table and a column for which they store custom data quality check results, and a severity column of the data quality issue. The SQL query that is configured in this external data quality results importer must be a complete SELECT statement that queries a dedicated logging table, created by the data engineering team. |
Reference and samples
The full list of all data quality checks in this category is located in the column/custom_sql reference. The reference section provides YAML code samples that are ready to copy-paste to the .dqotable.yaml files, the parameters reference, and samples of data source specific SQL queries generated by data quality sensors that are used by those checks.
What's next
- Learn how to run data quality checks filtering by a check category name
- Learn how to configure data quality checks and apply alerting rules
- Read the definition of data quality dimensions used by DQOps